







版本:spark3.0.2
1.1. 问题现象:
业务使用hive union all产生的数据目录如下,sparksql无法读取该子目录下的数据。select * from table 这种简单的sql也无法读取。

一些博客建议设置下面两个参数,spark.hive.mapred.supports.subdirectories=true和spark.hadoop.mapreduce.input.fileinputformat.input.dir.recursive=true, 设置后sparksql依然无法读取,问题依然存在。
1.2. 问题分析:
查看物理执行计划,叶子节点为FileSourceScanExec,该执行计划是spark内置的读取文件的SparkPlan,根本就不会使用spark.hive.mapred.supports.subdirectories和spark.hadoop.mapreduce.input.fileinputformat.input.dir.recursive,这两个配置。
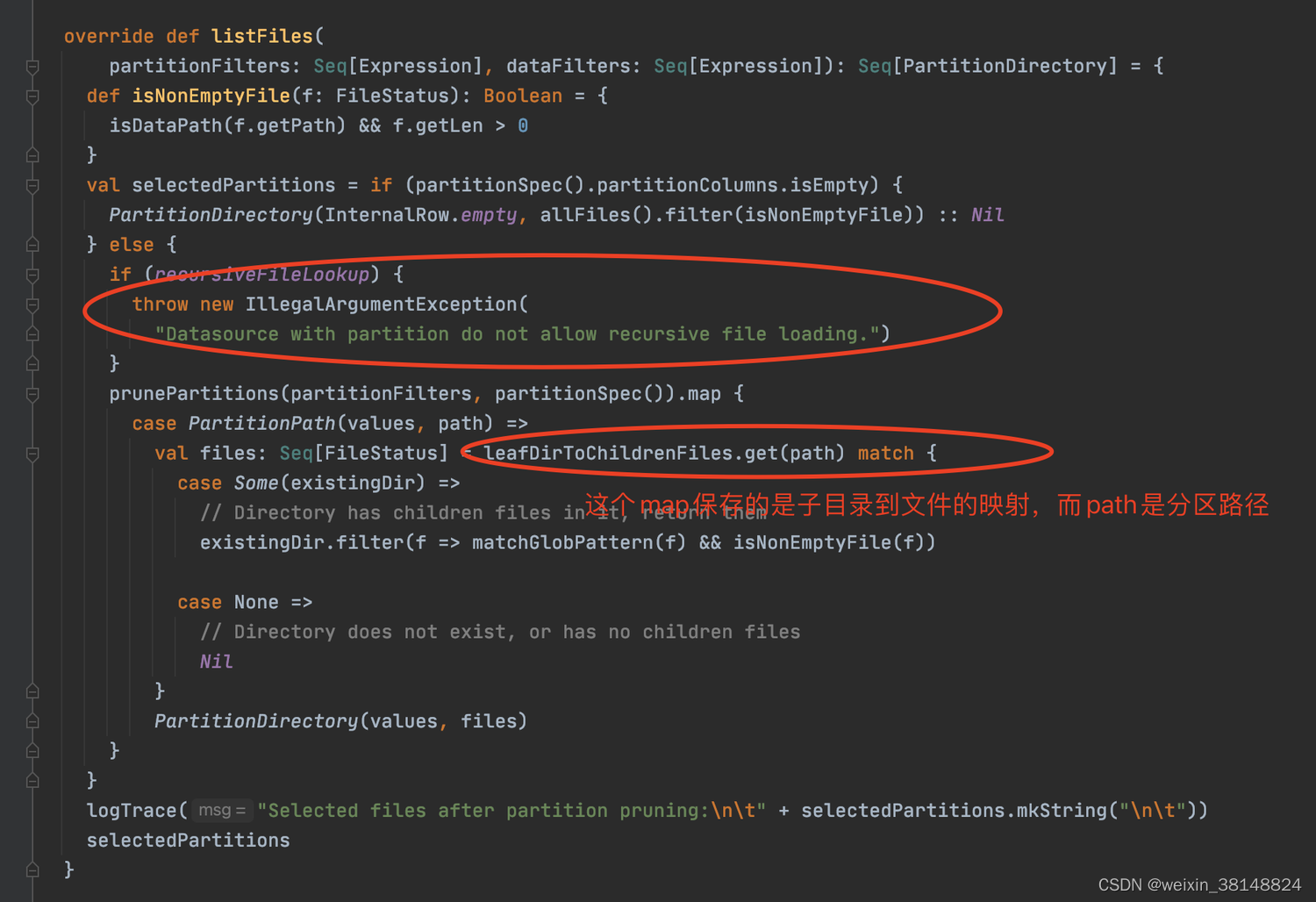
那么在FileSourceScanExec的逻辑中,是否能够处理这种子目录的情况呢。答案是目前FileSourceScanExec无法递归处理子目录:
FileSourceScanExec的selectedPartitions的属性保存了需要的读取的分区文件,这些文件信息来自PartitioningAwareFileIndex的listFiles方法。leafDirToChildrenFiles这个map中保存的是子目录和数据文件的映射,而path为分区路径,所以这里get返回为空。
既然FileSourceScanExec无法处理子目录,那有没有其他SparkPlan能够处理呢?
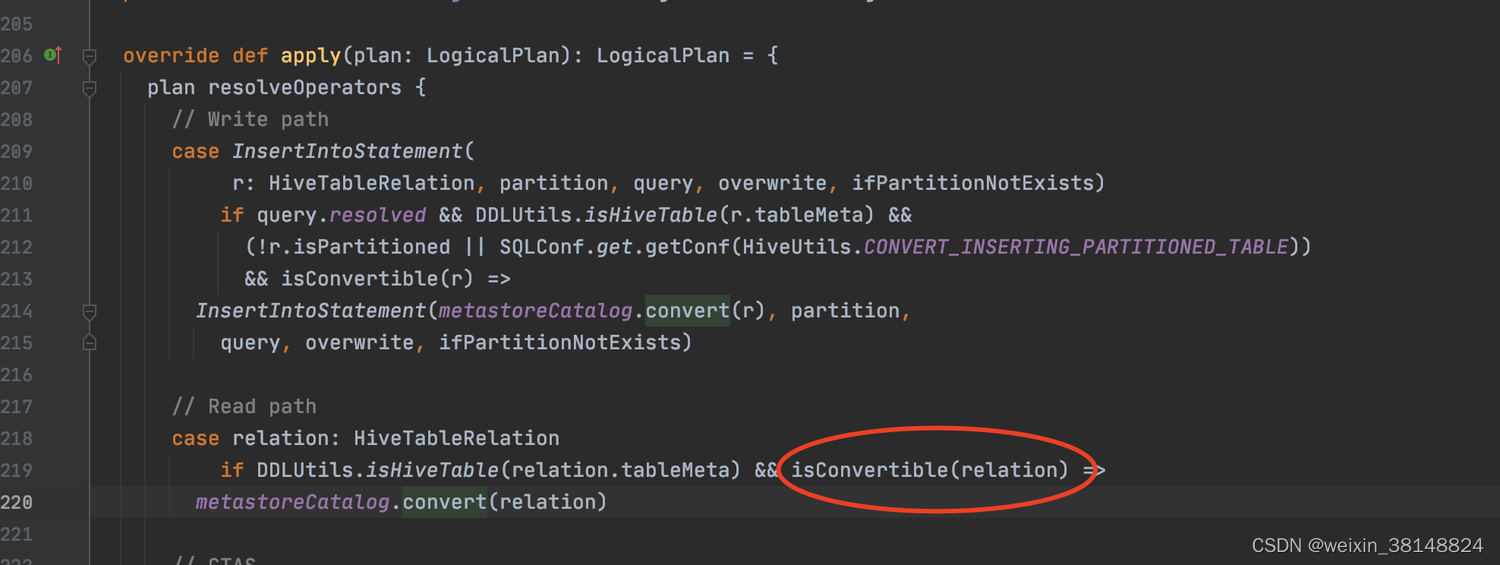
spark读取hive表时,hive表在logicPlan中其实最开始是HiveTableRelation,然后HiveSessionStateBuilder的postHocResolutionRules中的RelationConversions规则,将HiveTableRelation转换成了LogicalRelation。这个LogicalRelation最终会转换成FileSourceScanExec。
如果RelationConversions规则不生效,HiveTableRelation就不会转换成LogicalRelation,那最终HiveTableRelation对应的SparkPlan为HiveTableScanExec,在HiveTableScanExec中能够使用spark.hadoop.mapred.input.dir.recursive=true配置读取子目录。
所以如何控制RelationConversions规则是否生效,见代码。 如果数据文件是orc,那么就设置spark.sql.hive.convertMetastoreOrc=false,如果数据文件是parquet,就设置spark.sql.hive.convertMetastoreParquet=false。 设置了参数后RelationConversions规则就不会生效。
1.3. 问题解决方法
如果是orc文件:
--conf spark.hadoop.mapred.input.dir.recursive=true --conf spark.sql.hive.convertMetastoreOrc=false
如果是parquet文件:
--conf spark.hadoop.mapred.input.dir.recursive=true --conf spark.sql.hive.convertMetastoreParquet=false

















 905
905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









