







 注意力机制模拟生物观察过程,常用于Encoder-Decoder框架。它为输入序列分配权重,实现软寻址。主流形式包括基于CNN、RNN和self-Attention(如Transformer)。通道域的注意力如SE-block和CBAM-block通过赋予通道权重来捕捉依赖关系。
注意力机制模拟生物观察过程,常用于Encoder-Decoder框架。它为输入序列分配权重,实现软寻址。主流形式包括基于CNN、RNN和self-Attention(如Transformer)。通道域的注意力如SE-block和CBAM-block通过赋予通道权重来捕捉依赖关系。
参考:https://zhuanlan.zhihu.com/p/35571412
什么是注意力机制?
注意力机制模仿了生物观察行为的内部过程,即一种将内部经验和外部感觉对齐从而增加部分区域的观察精细度的机制。例如人的视觉在处理一张图片时,会通过快速扫描全局图像,获得需要重点关注的目标区域,也就是注意力焦点.
Encoder-Decoder框架
目前大多数的注意力模型都是依附在Encoder-Decoder框架下,但并不是只能运用在该模型中,注意力机制作为一种思想可以和多种模型进行结合,其本身不依赖于任何一种框架。
备注:所谓编码,就是将输入的序列编码成一个固定长度的向量;解码,就是将之前生成的固定向量再解码成输出序列。
Attention机制其实就是一系列注意力分配系数,也就是一系列权重参数罢了,就是加权。
attention函数
既然attention是一组注意力分配系数,那么他是如何实现的?这里要提出一个函数叫做attention函数,它是用来得到attention value的,比较主流的attention框架是:
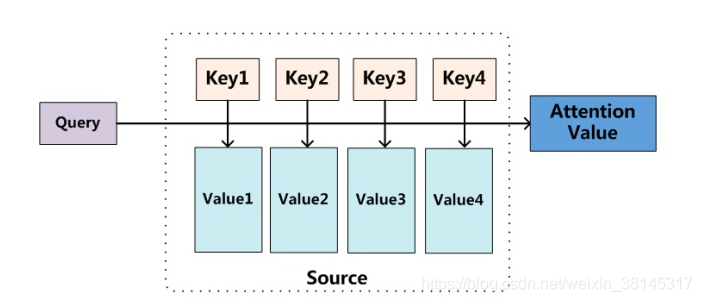
上图其实可以描述出attention value的本质,它其实就是一个查询(query)到一系列键值(key-value)对的映射。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









