






一、模拟问题代码
准备一个空的springboot项目
可以从https://start.spring.io/生成一个(也可以自己创建一个):
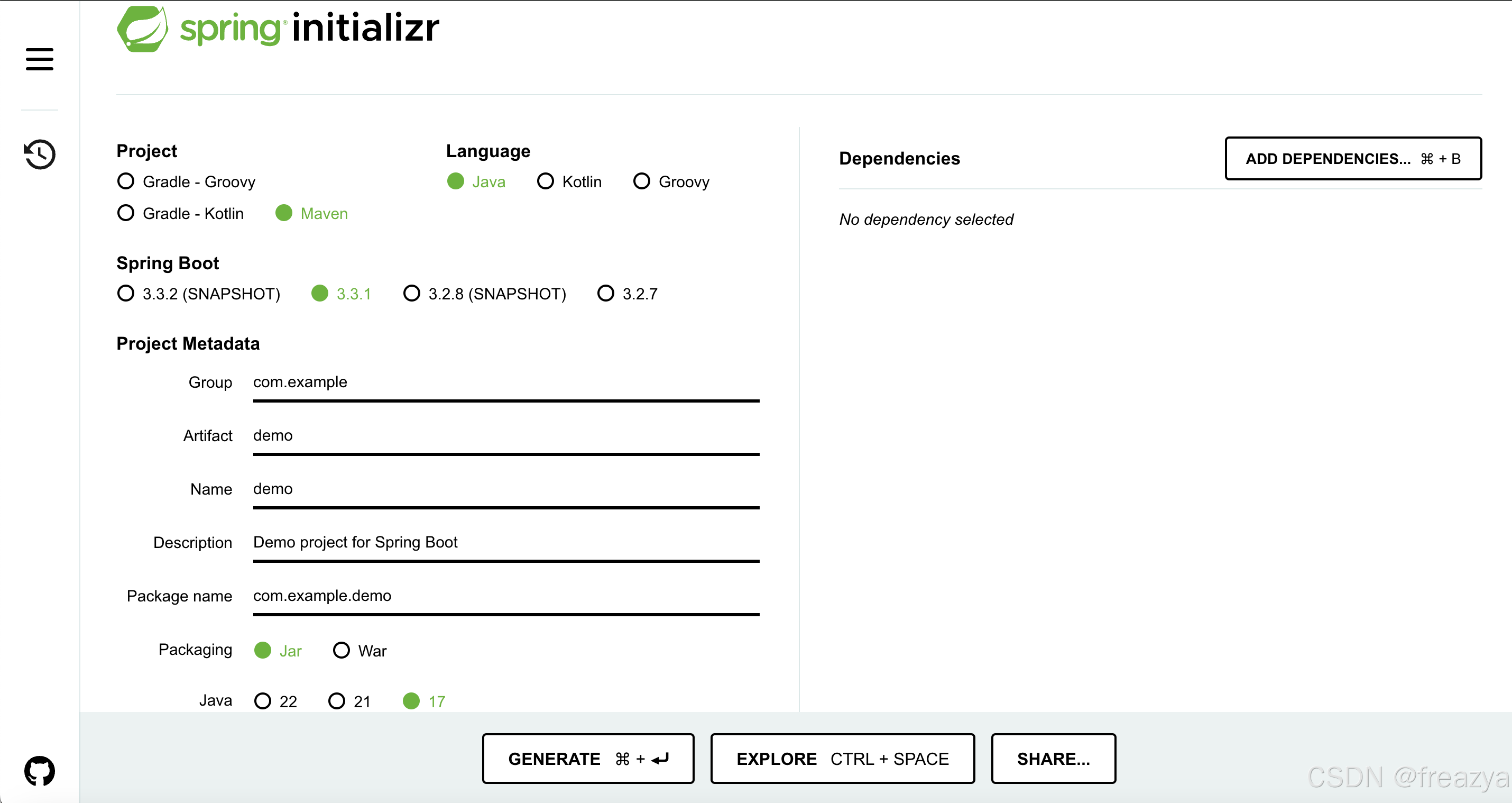
我们准备编写一个由外部访问来触发的OOM,所以依赖里请加入:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
编写触发oom的controller
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.ArrayList;
import java.util.List;
@RestController
public class OomController {
private List<Object> objects = new ArrayList<>();
@GetMapping("/oom")
public String triggerOom() {
while (true) {
objects.add(new byte[1024 * 1024]); // 每次分配1MB
}
}
}
打包
mvn clean package
将生成的jar上传到服务器上
用FileZilla或其他工具
二、部署
为了模拟oom,我们把jvm的内存设置小一点:64M
linux上运行:
nohup java -Xms64m -Xmx64m -jar demo-0.0.1-SNAPSHOT.jar > output.log 2>&1 &
命令解释:
nohup ... &用于在系统后台不挂断地运行命令,退出终端不会影响程序的运行-Xms64m -Xmx64m是设置初始内存和最大内存为64m> output.log 2>&1将标准错误 2 重定向到标准输出 &1 ,标准输出 &1 再被重定向输入到 output.log 文件中
如果想直接用IDEA启动,可以在IDEA里设置
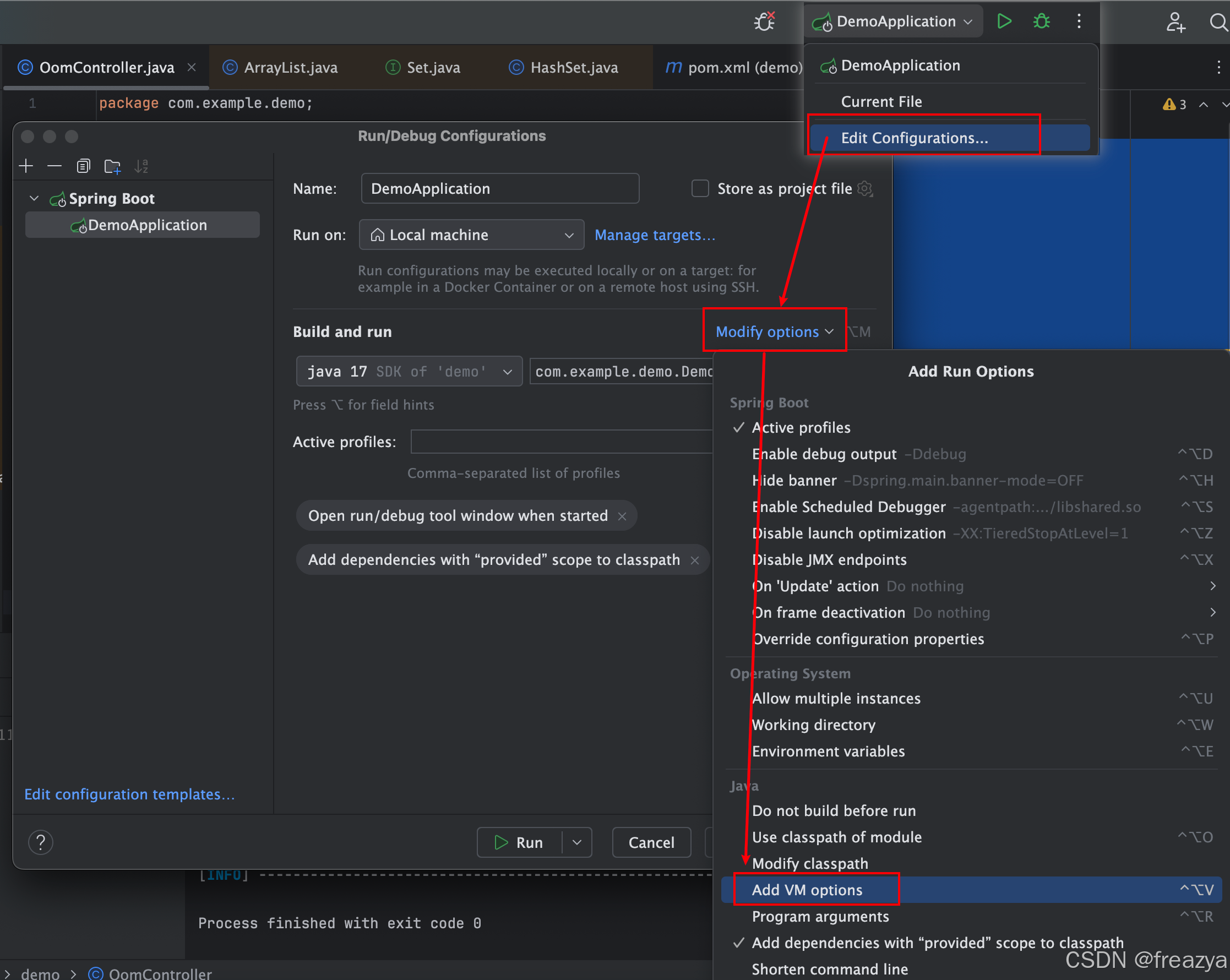
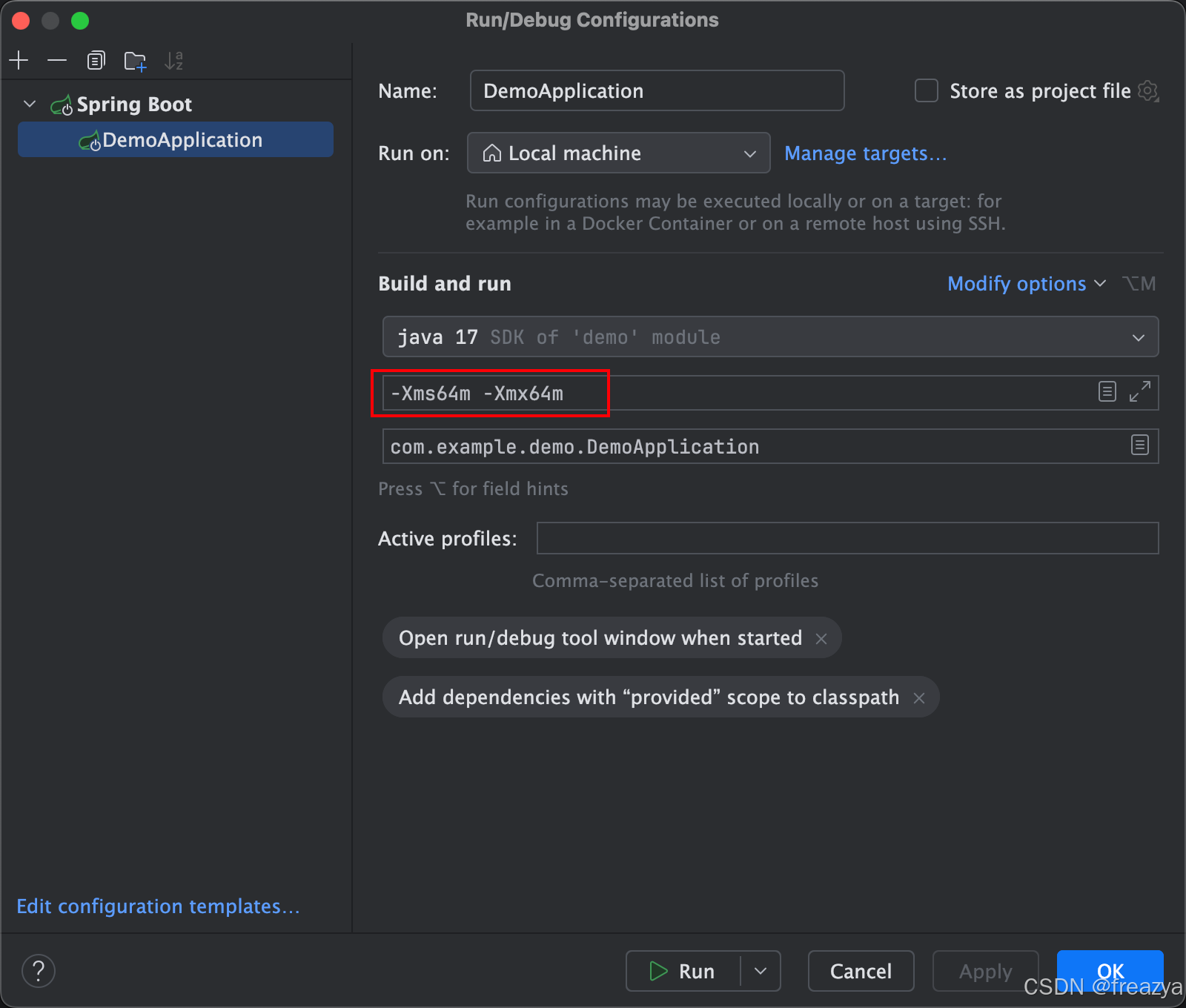
三、触发OOM
在部署的机器上执行
curl http://localhost:8080/oom
或者通过浏览器远程访问(将server换成服务器ip地址):
http://server:8080/oom
会发现访问报错:
- curl报错:
{"timestamp":"2024-07-15T06:47:38.083+00:00","status":500,"error":"Internal Server Error","path":"/oom"}
- 浏览器报错:
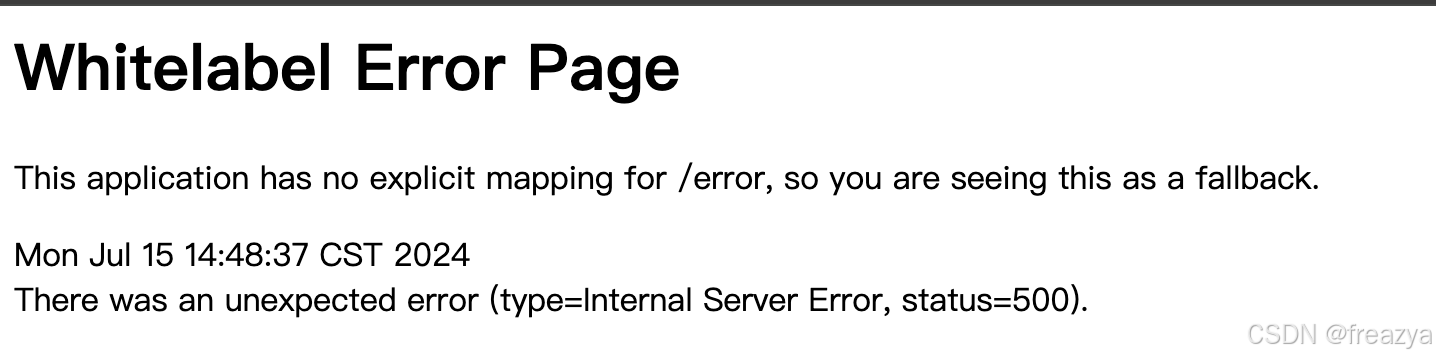
四、尝试查看日志
- linux上:
cat output.log

- IDEA里:
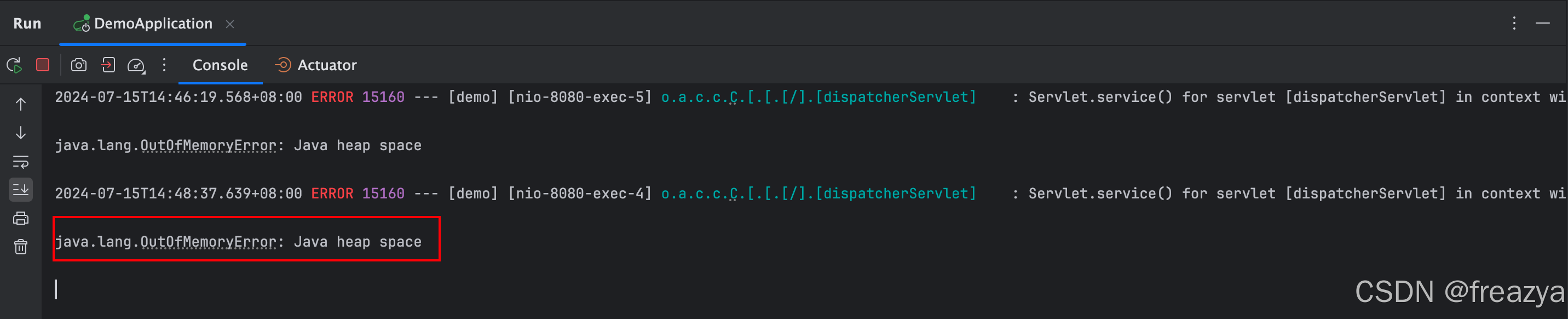
五、dump线程和堆使用情况
- 获取 JVM 的进程 ID
使用 ps
ps -ef | grep java
或使用 jps:
jps -l
- 使用jmap生成堆转储
将<pid>换成上面获取到的pid
jmap -dump:format=b,file=heapdump.hprof <pid>
- 使用 jstack 生成线程 dump
将<pid>换成上面获取到的pid
jstack -l <pid> > threaddump.txt
六、分析结果
对于oom,主要看堆转储:heapdump.hprof
可以利用Eclipse Memory Analyzer(MAT)来进行分析
去Eclipse Memory Analyzer官网下载安装
安装后,打开软件,点击file->Open Heap Dump打开heapdump.hprof,打开时会有如下选项:
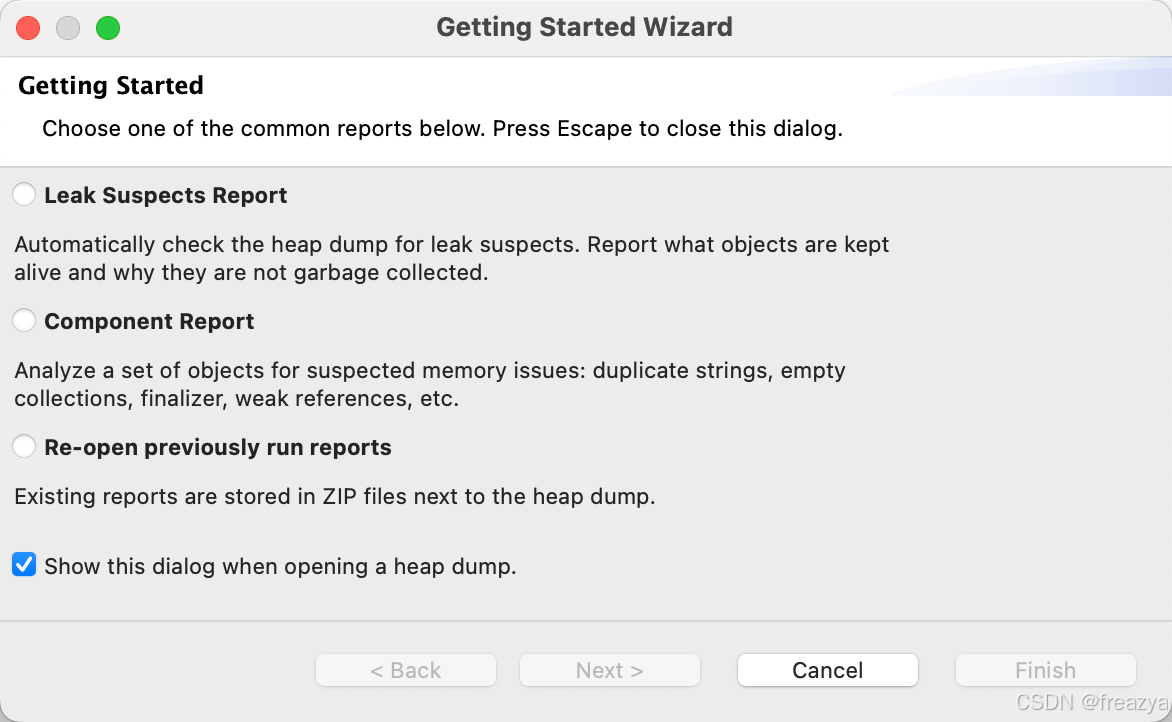
选项解释:
-
Leak Suspects Report:
功能:这个选项会生成一个报告,标识出可能的内存泄漏点。MAT会分析堆转储,尝试找出那些可能导致内存泄漏的对象,并生成一个详细的报告。
用途:用于快速定位和分析可能的内存泄漏问题。报告会显示泄漏的路径、相关对象以及这些对象的内存使用情况。
推荐使用场景:当你怀疑应用程序中存在内存泄漏,并且想要迅速找到可能的泄漏点时,这个选项非常有用。 -
Component Report:
功能:这个选项生成一个组件报告,提供有关内存使用情况的概述和详细的内存分析。它可以按组件(例如类、包等)显示内存使用情况。
用途:用于全面了解应用程序中的内存使用模式。通过按组件查看内存使用情况,你可以识别哪些部分的代码占用了最多的内存。
推荐使用场景:当你需要全面分析应用程序的内存使用情况,而不仅仅是查找内存泄漏时,这个选项非常有用。 -
Re-open previously run reports:
功能:这个选项允许你重新打开之前生成的报告。MAT会保存你之前生成的报告,因此你可以快速访问和查看这些报告,而无需重新分析堆转储文件。
用途:用于快速访问之前生成的报告,节省时间和资源,特别是当你需要反复查看和比较多个报告时。
推荐使用场景:当你已经生成并查看了一些报告,并且想要再次查看或比较这些报告时,这个选项非常有用。
所以,一般选第一个就可以:

可以看到,下面黄色部分,已经标识出了可能的问题,可以翻到黄色部分最下面,直接点Details进去查看
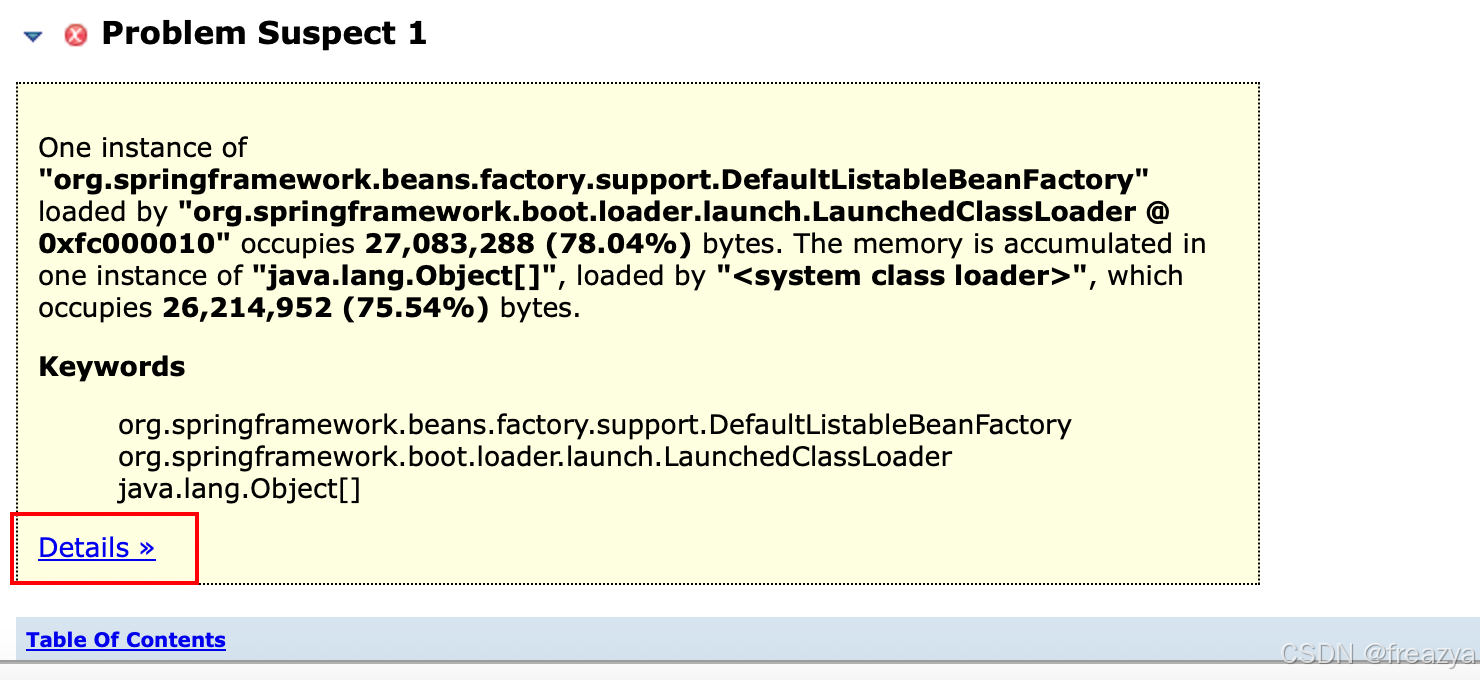
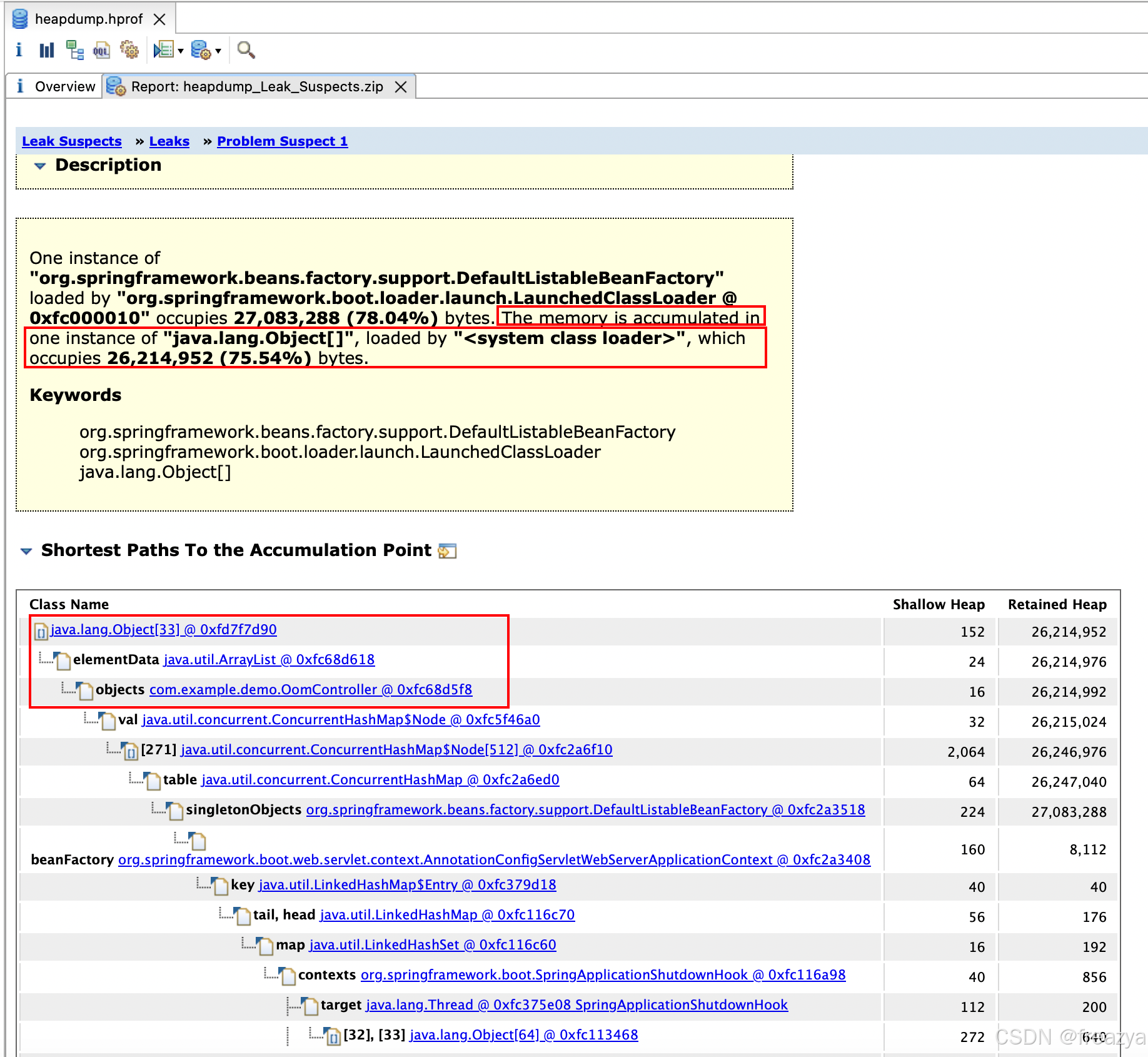
可以看到,这里已经很明显的标明了,时java.lang.Object[]实例占用内存过大,占到了(26214952kb),占总内存的75%
其他功能
当然,你也可以自行选择看不同的视角,点击上面的overview,下面会有不同功能入口:
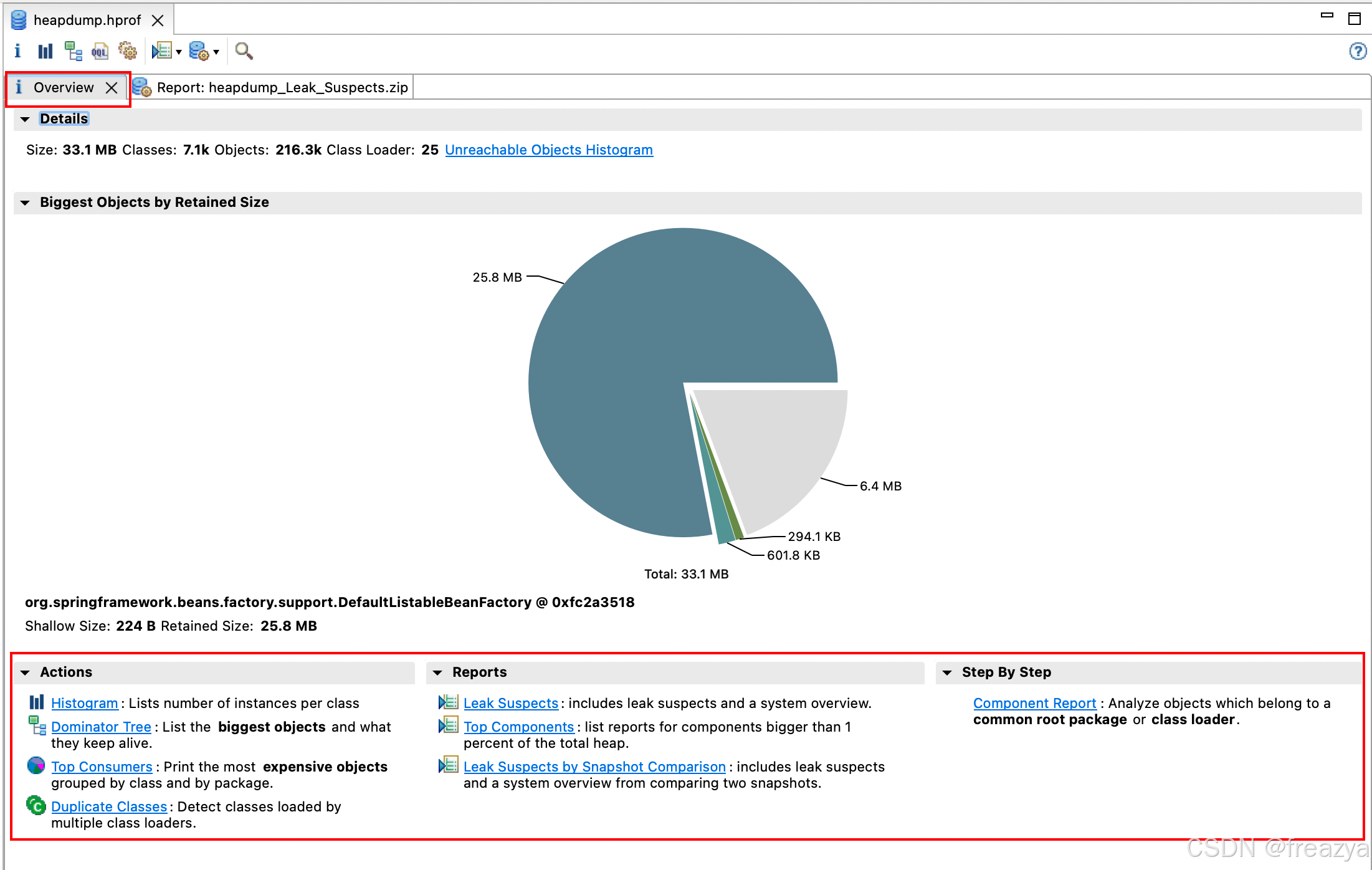
解释如下:
- Actions(动作类):
- Histogram: Lists number of instances per class(柱状图:列出每个类的实例数)
- Dominator Tree: List the biggest objects and what they keep alive.(支配者树:列出最大的对象及其存活的依赖)
- Top Consumers: Print the most expensive objects grouped by class and by package.(顶级消费者:按类和包打印最大的对象)
- Duplicate Classes: Detect classes loaded by multiple class loaders.(重复类:检测由多个类加载器加载的类)
- Reports(报告类):
- Leak Suspects: includes leak suspects and a system overview.(泄漏嫌疑对象:包括泄漏嫌疑对象和系统概述)
- Top Components: list reports for components bigger than 1 percent of the total heap.(大组件:列出大于总堆1%的组件的报告)
- Leak Suspects by Snapshot Comparison: includes leak suspects and a system overview from comparing two snapshots.(按快照比较的泄漏嫌疑对象:包括泄漏嫌疑对象和比较两个快照的系统概述)
- Step By Step(步骤)
- Component Report: Analyze objects which belong to a common root package or class loader(组件报告:分析属于公共根包或类加载器的对象)
以前两个为例:
-
Histogram(柱状图:列出每个类的实例数)
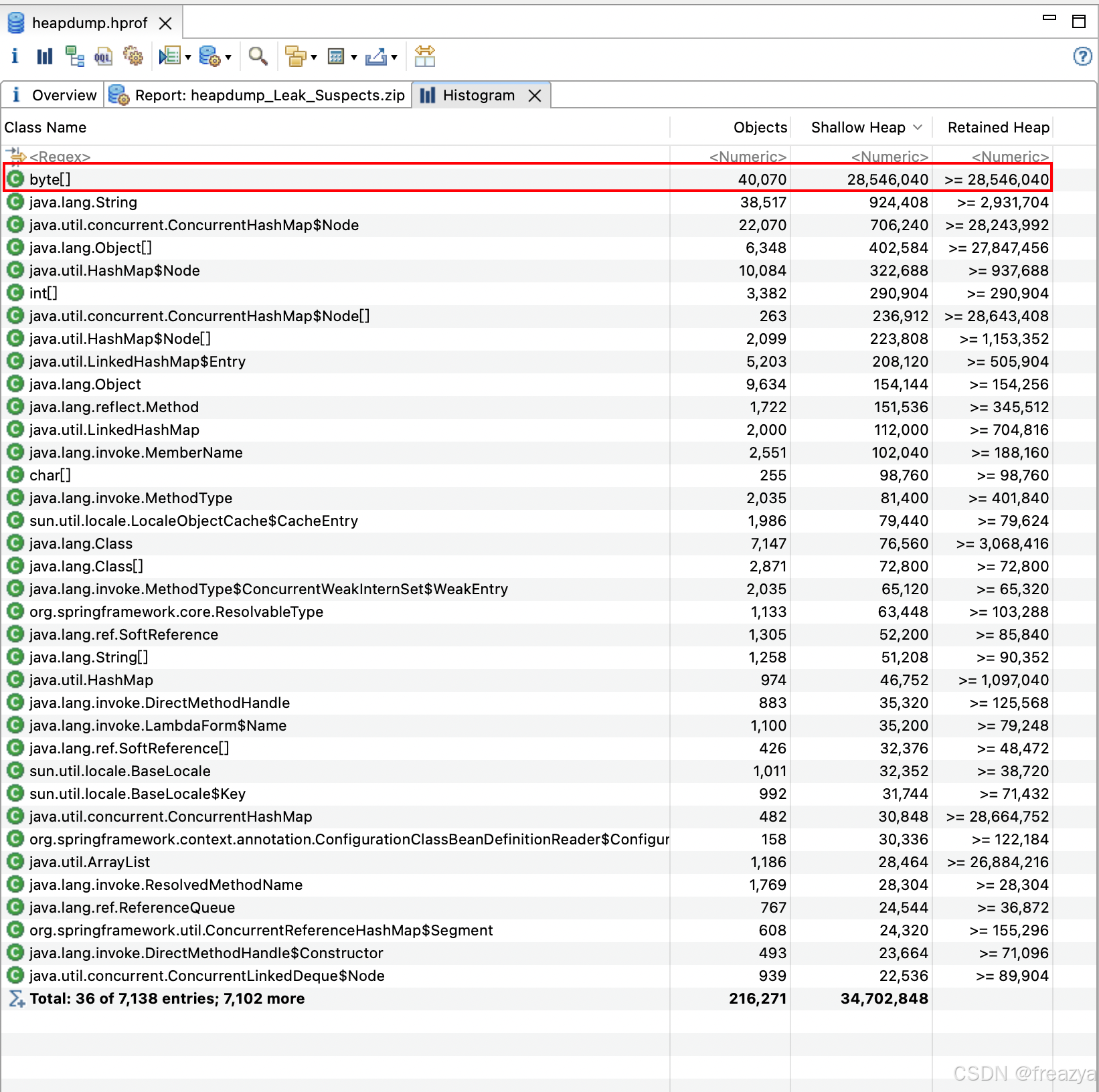
-
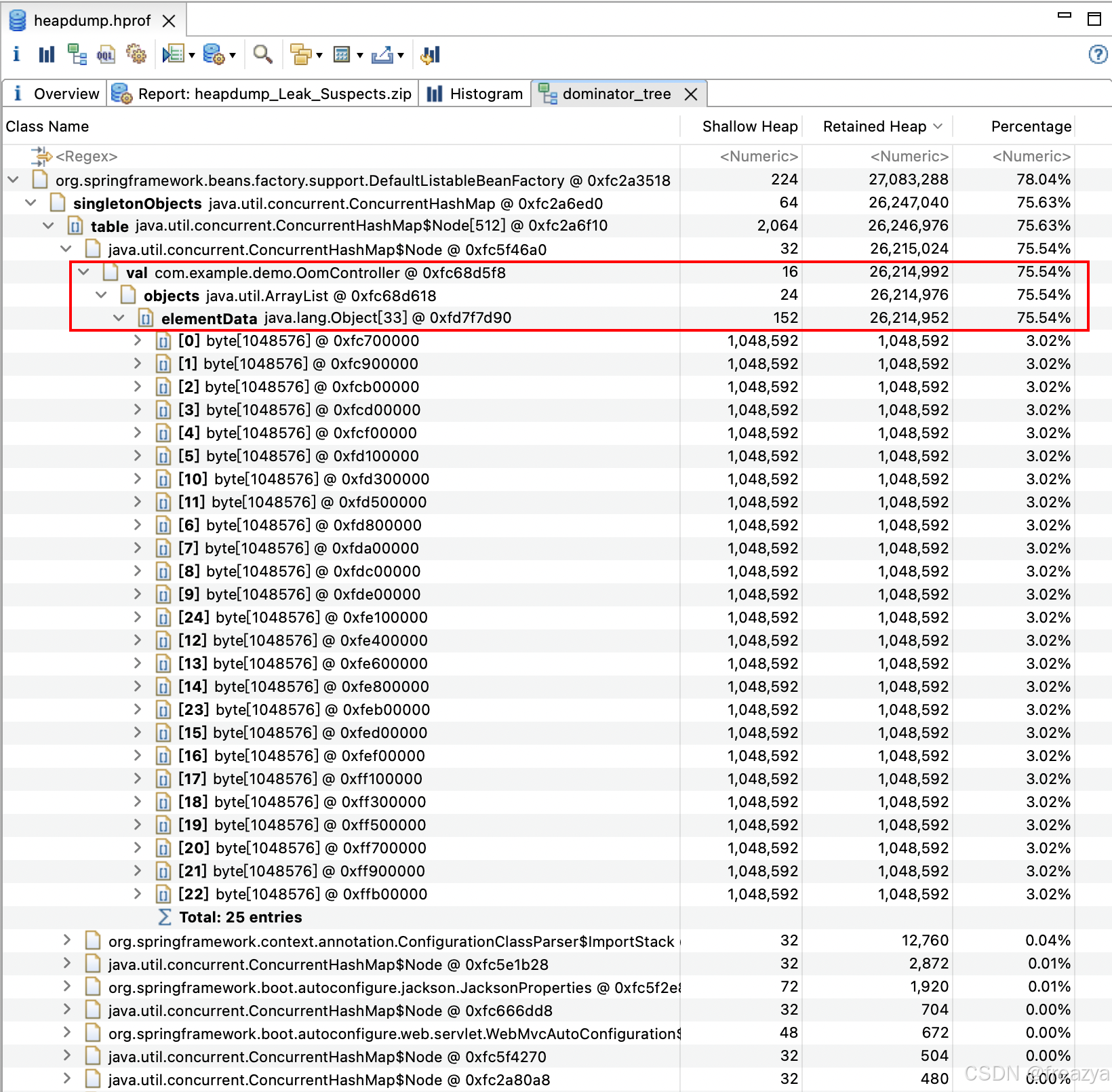
Dominator Tree(支配者树:列出最大的对象及其存活的依赖)
可以看到最大的对象是org.springframework.beans.factory.support.DefaultListableBeanFactory @ 0xfc2a3518,最终依赖的对象是java.util.ArrayList @ 0xfc68d618中存储的各个元素:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









