







论文笔记--A Fine-grained Interpretability Evaluation Benchmark for Neural NLP
1. 文章简介
- 标题:A Fine-grained Interpretability Evaluation Benchmark for Neural NLP
- 作者:Lijie Wang, Yaozong Shen, Shuyuan Peng, Shuai Zhang, Xinyan Xiao, Hao Liu, Hongxuan Tang, Ying Chen, Hua Wu, Haifeng Wang
- 日期:2022
- 期刊:arxiv preprint
2. 文章概括
文章构建了一个新的benchmark用于评估神经网络等算法的可解释性。benchmark包括三种NLP任务:情感分析、文本相似度评估和阅读理解。和现有的一些benchmark相比,文章给出的benchmark覆盖了中、英文,且属于token水平的解释性评估,此外,该benchmark满足度量可解释性的benchmark的所有基本性质,即充分的、紧致的、全面的。
3 文章重点技术
3.1 数据收集
文章考虑了中、英文的三种代表性的NLP任务:情感分析、文本相似度评估和阅读理解。
- 情感分析(SA):从SST验证/测试集中随机获取1500个样本、从Movie Reviews测试集中随机获取400个样本构建英文评估集;从SA API随机获取60000个用户授权的日志,标注人员从中选择标注2000个构建中文评估集。
- 语义相似度(STS):从QQP中随机选择2000个文本对构建英文评估集;从LCQMC中随机选择2000个文本对构建中文评估集。
- 机器阅读理解(MRC):从SQUAD2.0中随机选择1500个问答对和500个没有回答的问题作为英文评估集;从DuReader中随机筛选1500个问答对和500个没有回答的问题作为中文评估集。
3.2 数据扰动
为了评估模型的faithfulness(根因在多大程度上影响输出结果),文章希望度量相同的模型决策机制下,外界扰动对根因是否有影响。一个好的根因应该满足“当扰动发生时,根因和预测输出的变化是一致的(输出不变,则根因也不变)。
文章从两个角度构建扰动:1) 扰动不影响根因和预测结果 2)扰动造成了根因的改变且可能会影响预测结果。基于这两个角度,文章定义了三种类型的扰动:
- 可有可无的单词的改变:插入、删除、替换可有可无的单词应该对模型结果和根因没有影响。比如"what are some reasons to travel alone"修改为"List some reasons to travel alone".
- 重要单词的改变:替换重要的单词为它们的同义词或者相关的单词,会对结果和根因造成影响。如"I dislike you"修改为"I hate you".
- 同义变换:将句子的结构进行变换但不改变语义,此时模型的预测结果和根因都不发生改变。如"The customer commented the hotel"修改为"The hotel is commented by the customer".
标注时,标注员会首先选定一种扰动类型,然后基于原句子构建一个该句子符合该扰动类别的实例和真实结果。
3.3 迭代标注和检查根因
标记员会原始输入中对输入影响较大的tokens为根因(rationales)。一些研究认为,好的rationale应该满足以下三点
- 充分性:包含足够的信息支撑人去做正确的预测
- 紧致性:所有tokens都可以有效支撑预测,即移除任意一个token都无法做正确的预测
- 全面性:所有可以支撑输出的tokens都在这个rationale中。
基于上述原则,文章设计了下述工作流保证标注数据的质量: - step1:标注根因:普通的标记员根据输入、输出标记rationales
- step2:根因打分:高级的标记员来对根因进行double-check。首先,标记员按照充分性对根因进行打分:不能支撑结果(1) 不确定(2) 可以支撑结果(3);然后标记员按照紧致性对根因进行打分:包含多余的tokens(1) 包含扰动(2) 不确定(3) 精准(4) ;最后标记员对每个输入的所有rationale sets的全面性进行打分:不全面(1) 不确定(2) 全面(3)。如果一个rationale在三个维度的得分低于给定阈值,则进入下一环节
- step3: 根因修改:针对step2中产生的低质量的根因,标记人员会尝试重新修改根因,然后重新进行step2的打分环境。如果打分仍不满足要求,则直接放弃该case。
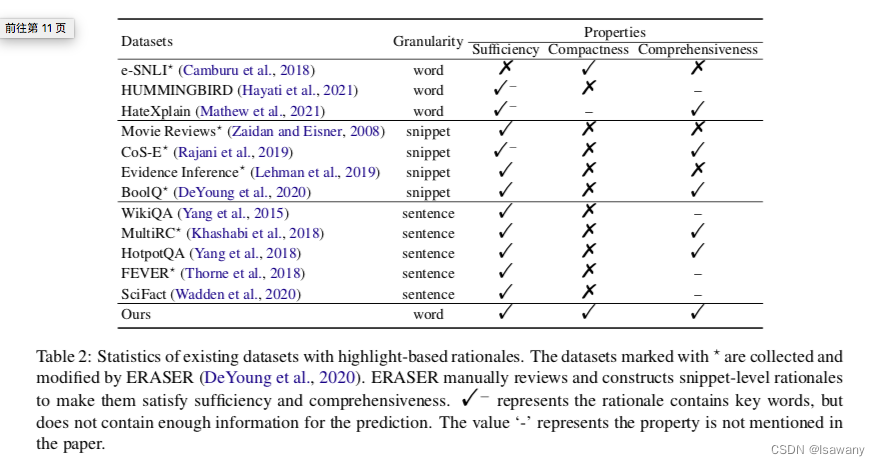
如下表所示,相比于现存的评估集,按照上述三个步骤构建的评估集满足全部要求。
3.4 度量
为了构建更合理地对模型表现进行度量,文章采用token-F1来度量可信度(plausibility),MAP来度量忠实度(faithfulness)
3.4.1 Token F1-score
如下式定义,token F1-score用于计算token之间重叠的比例,用于评估可信度(模型给出根因和真实根因的对齐程度) T o k e n − F 1 = 1 N ∑ i = 1 N ( 2 × P i × R i P i + R i ) , w h e r e P i = ∣ S i p ∩ S i g ∣ ∣ S i p ∣ , a n d R i = ∣ S i p ∩ S i g ∣ ∣ S i g ∣ Token-F1 = \frac 1N \sum_{i=1}^N \left(2 \times \frac {P_i \times R_i}{P_i +R_i}\right), \\ where\ P_i = \frac {|S_i^p \cap S_i^g|}{|S_i^p|}, \ and \ R_i = \frac {|S_i^p \cap S_i^g|}{|S_i^g|} Token−F1=N1i=1∑N(2
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









