







 本文介绍了大模型如BERT、GPT和T5,以及主流开源模型LLaMA、ChatGLM-6B和BLOOM。重点讨论了AdapterTuning参数微调方法。文章还提及使用LangChain进行文本处理和大模型应用实例。
本文介绍了大模型如BERT、GPT和T5,以及主流开源模型LLaMA、ChatGLM-6B和BLOOM。重点讨论了AdapterTuning参数微调方法。文章还提及使用LangChain进行文本处理和大模型应用实例。
https://www.bilibili.com/video/BV14w411C78s/?spm_id_from=333.337.search-card.all.click&vd_source=4b2caf1fab34e94c80df37ee4480ba45
一、大模型
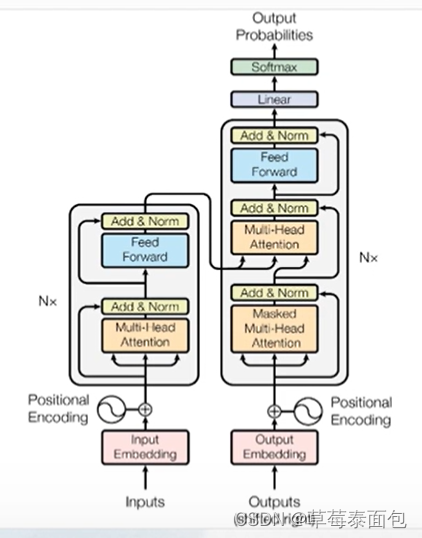
Transformer模型:

BERT模型
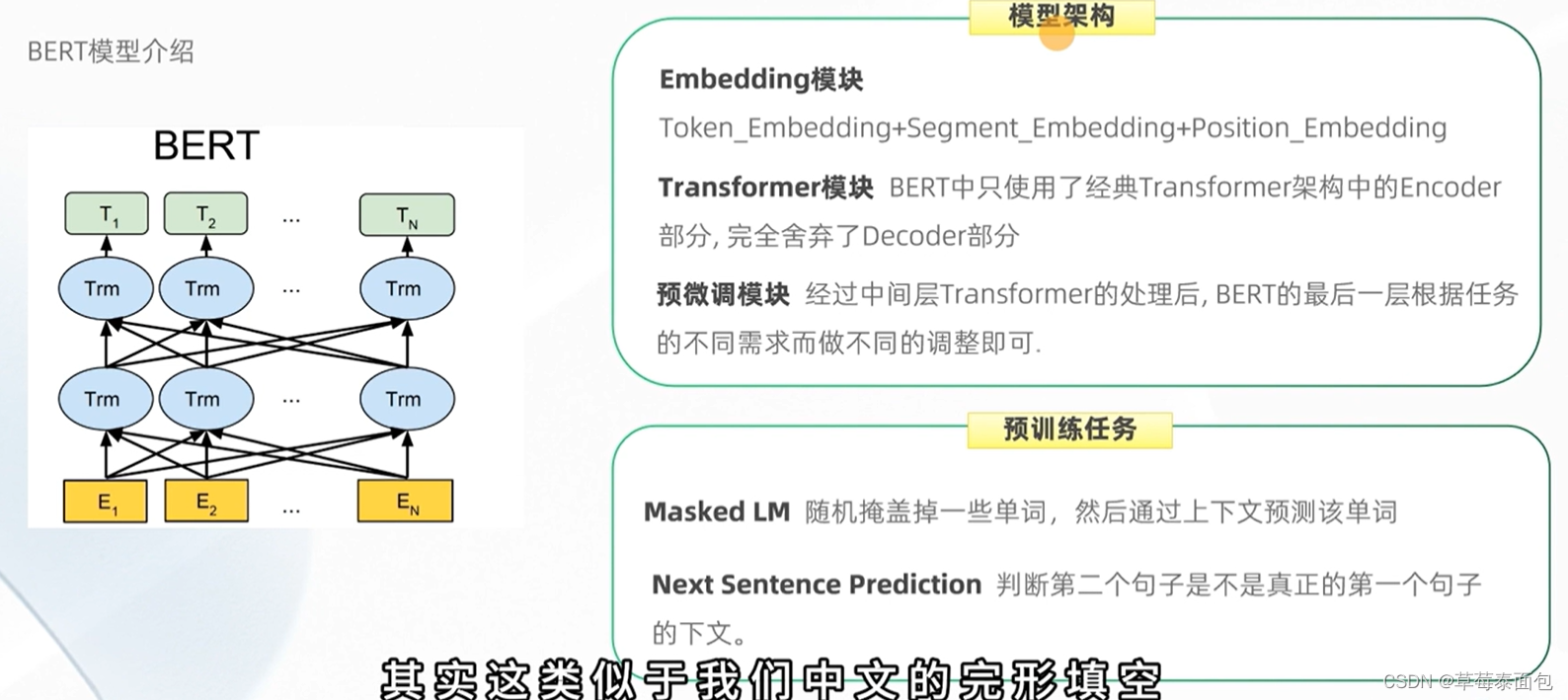
模型架构:
- embedding
- transformer
- 预微调模块
预训练任务:
-Masked LM
-NSP
GPT模型

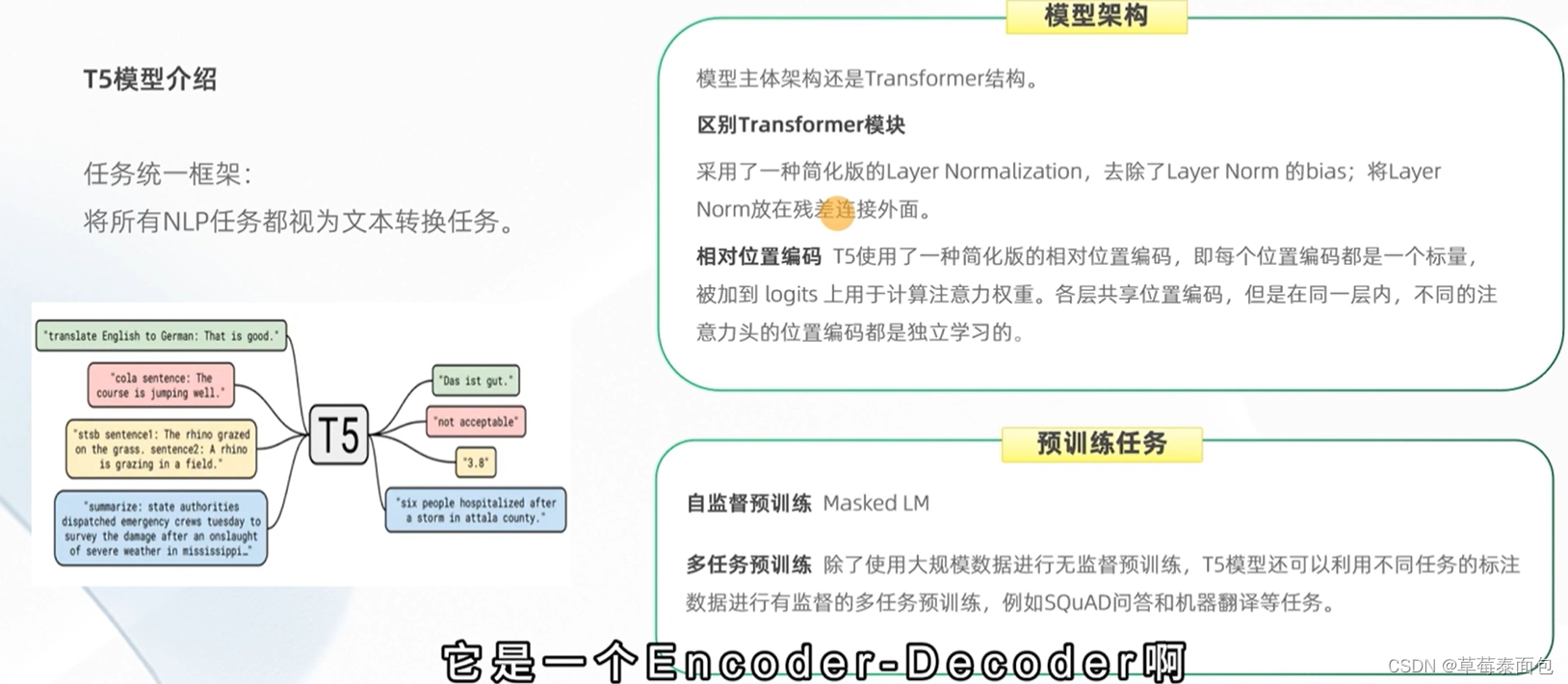
T5模型
二、主流开源大模型
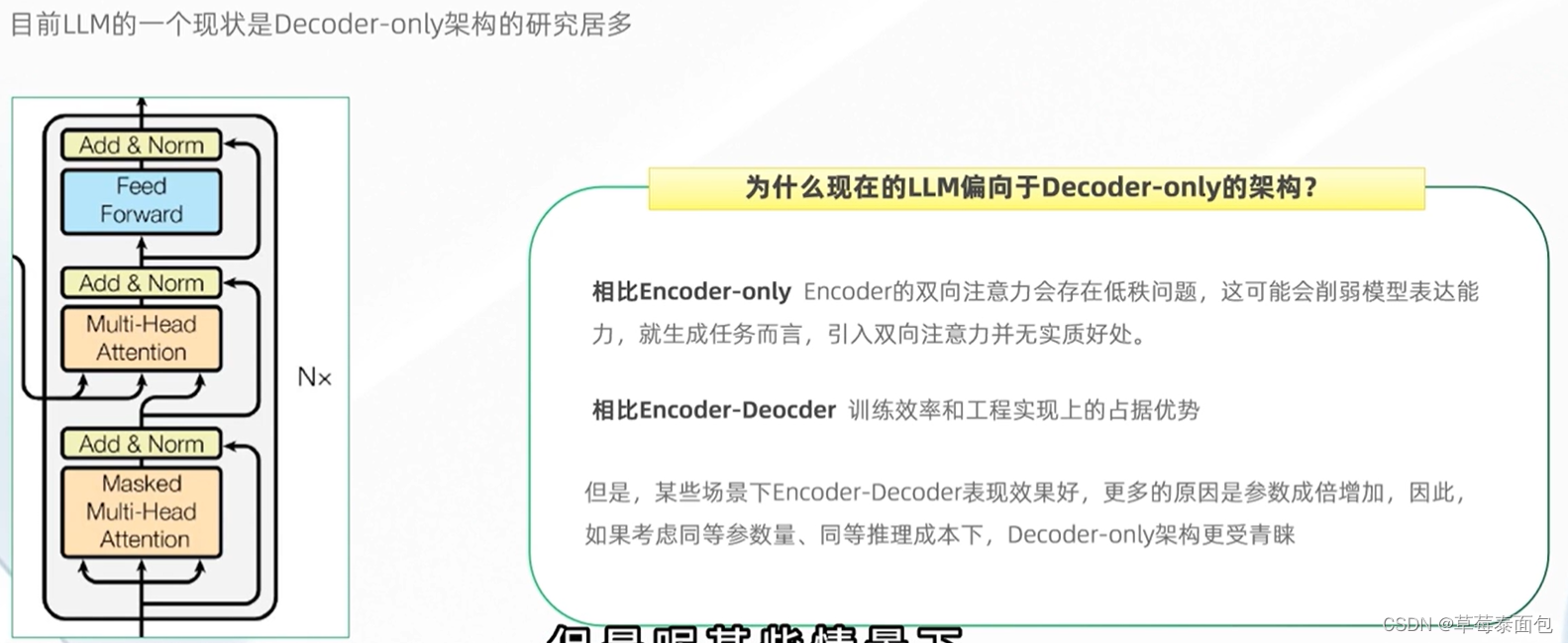
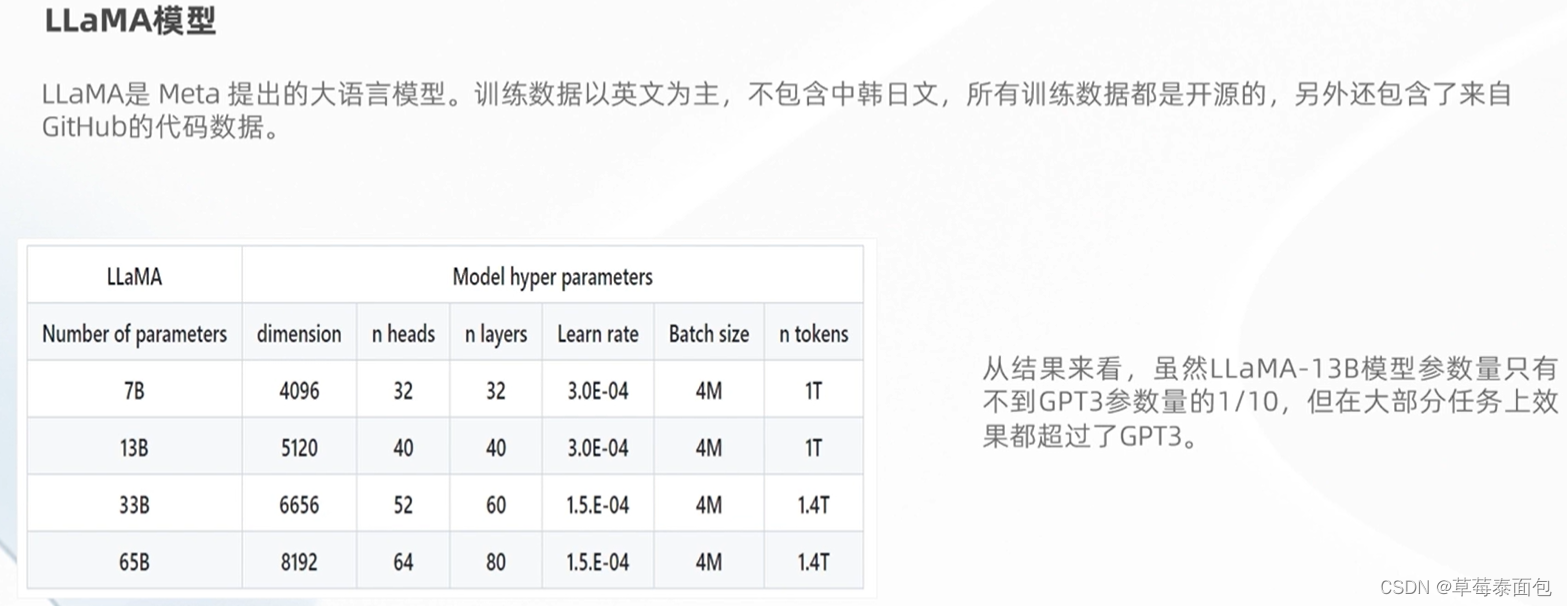
LLaMA


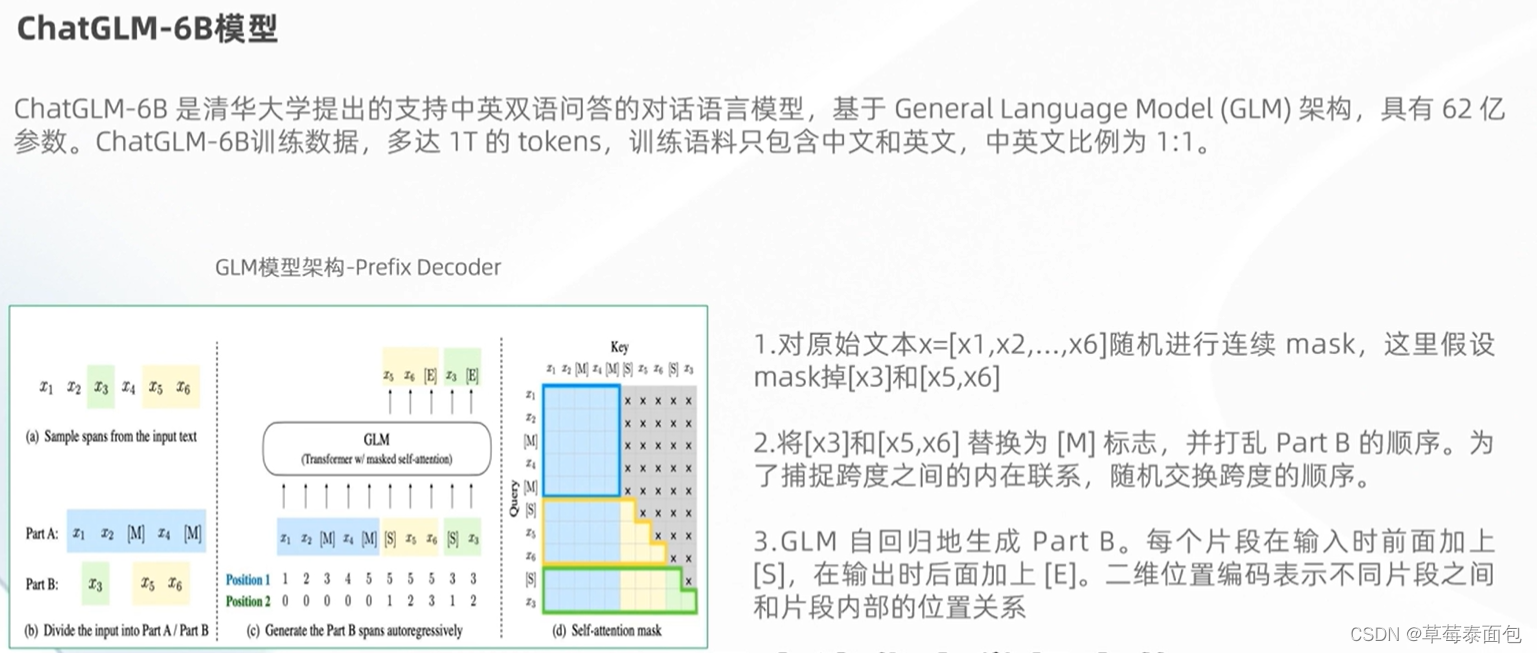
ChatGLM-6B
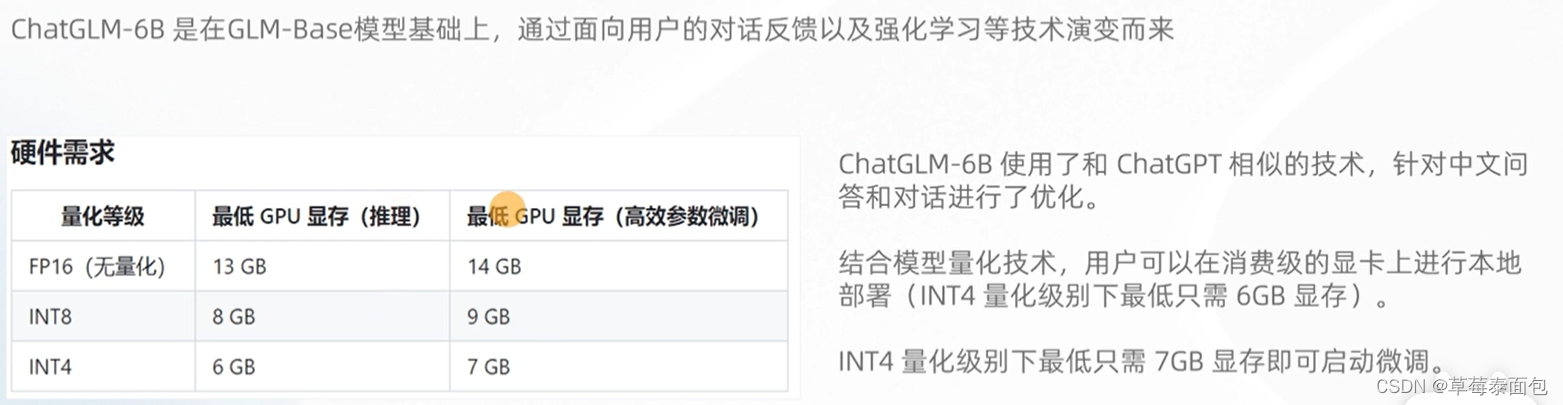
INT4在个人笔记本上也可以部署。

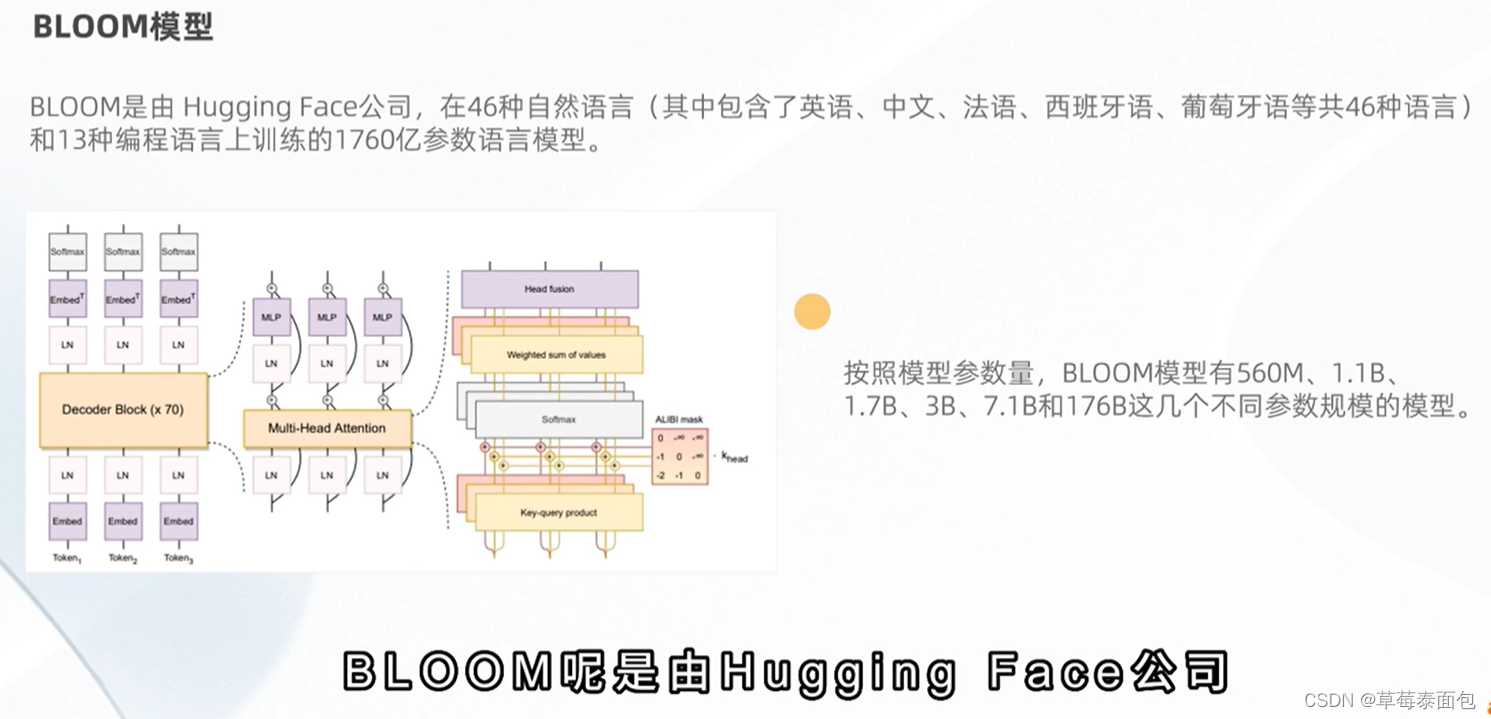
BLOOM
decoder


三、大模型参数微调方法

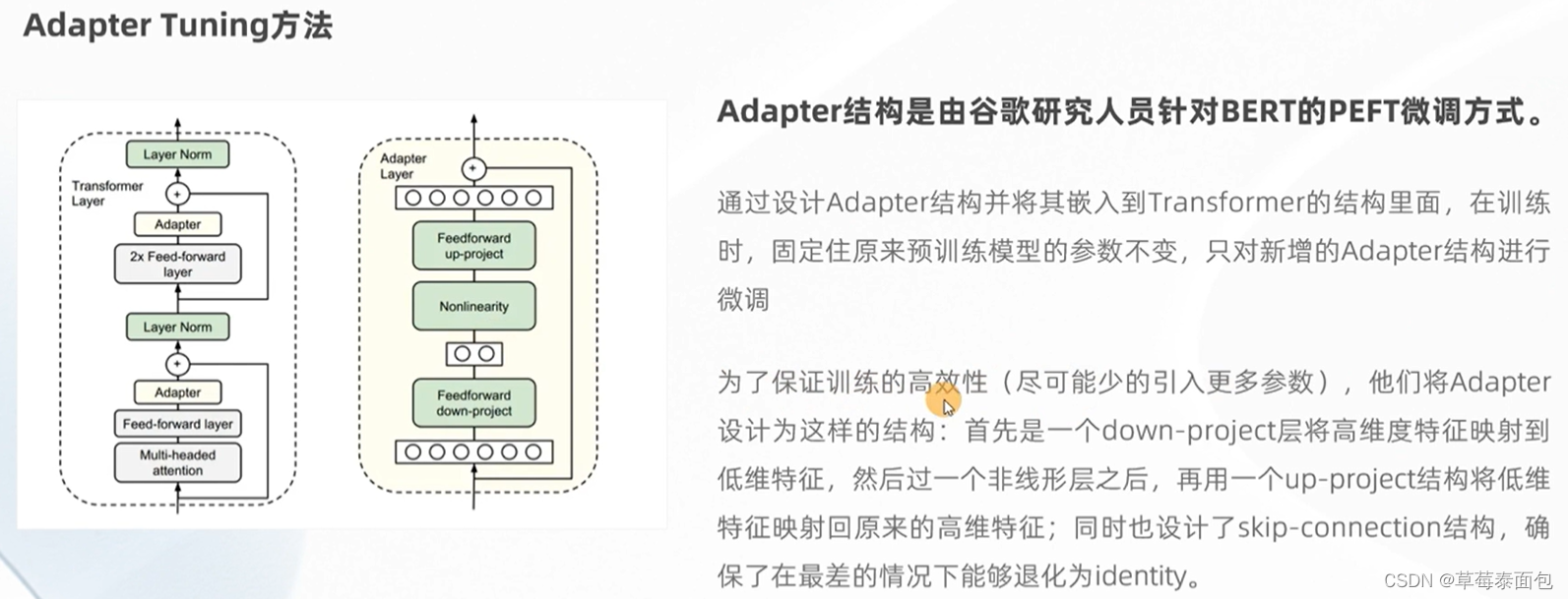
Adapter Tuning



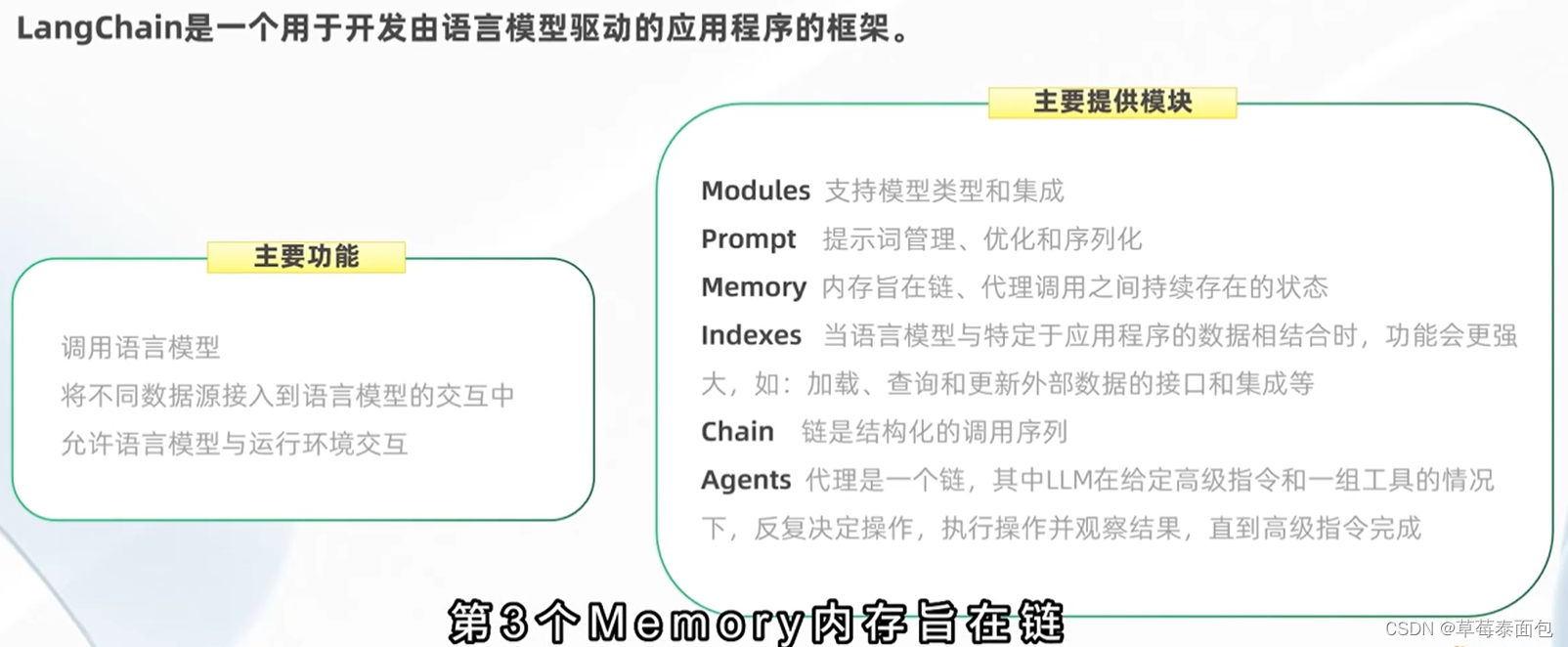
#四、 LangChain

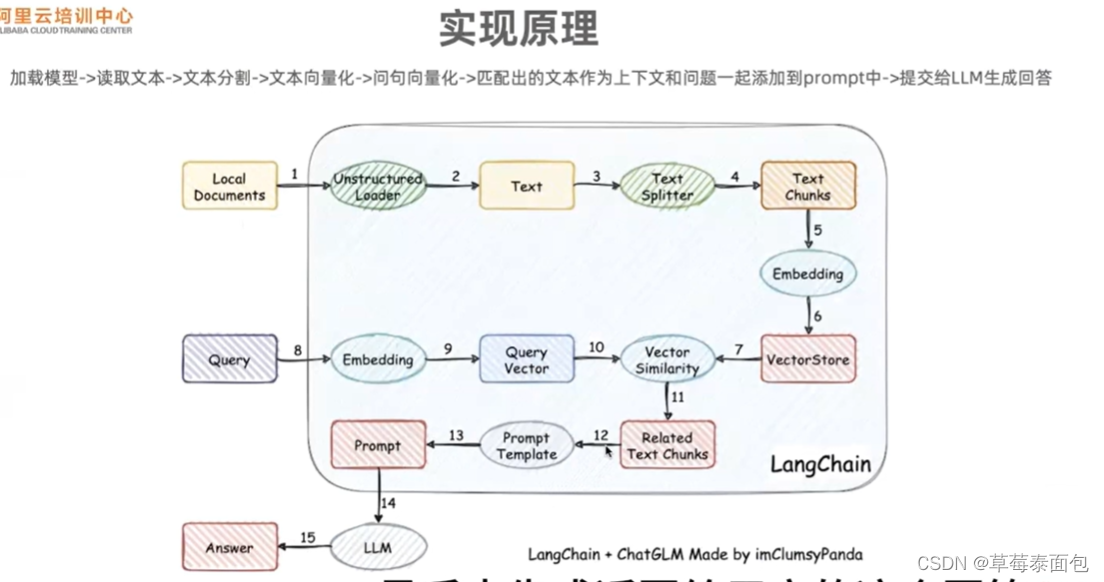
本地文件——文本分割———向量化embedding——向量存储vectorstore——向量相似度比较
提问——向量化——向量相似度比较
比较选取跟query最接近的vectorstore中的k个向量,把这些向量放到这个prompt里面,一起传输给LLM,最后生成返回给用户的回答。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









