







引言
在人工智能技术快速发展的今天,企业对于数据安全和隐私保护的需求日益增强。基于检索增强生成(Retrieval-Augmented Generation, RAG)的本地知识库系统,成为解决大模型知识局限性和幻觉问题的关键方案。本文将以 Ollama 和 AnythingLLM 为核心工具,详细介绍如何通过API实现企业本地知识库的训练与调用,并提供完整的Python代码示例及执行效果分析,助力企业构建安全高效的私有化知识管理系统。
tip:
本篇文中用于接上一篇做续,真正工业化 rag 流程,后续会持续更新,目前这套比较适合知识库更新不频繁,公司内协作流程,部门内知识库构建基本满足使用,二手 4060 显卡也基本满足,工业化还需要更精细的技术解决方案,后续再更新,大家拿这套先玩着。
一、工具与技术背景
1.1 RAG技术原理
RAG通过结合大语言模型(LLM)的生成能力与外部知识库的检索功能,显著提升回答的准确性和专业性。其核心流程包括:
- 知识库构建:将企业文档转化为向量并存储于向量数据库;
- 检索增强:根据用户问题检索相关文档片段;
- 生成回答:LLM结合检索结果生成最终响应。
1.2 AnythingLLM与Ollama简介
- Ollama:开源本地大模型管理工具,支持一键部署Llama、Gemma等模型,提供REST API接口。
- AnythingLLM:企业级知识库管理平台,支持多格式文档上传、向量数据库集成及灵活的API调用,适用于构建私有化问答系统。
组合优势:本地化部署保障数据安全,灵活支持多模型切换,降低企业AI应用门槛。
- 访问
http://localhost:3001,选择Ollama作为LLM Provider,填写Base URL为http://host.docker.internal:11434。
- 选择预加载的模型(如
deepseek-r1:8b)。
二、知识库训练实战
2.1 文档上传与嵌入处理
1. 通过UI上传文档:
- 支持PDF、TXT、DOCX等格式,单个文件可达500MB。
- 示例:这里录入一本道德经做测试。

如果你用过 swagger,那点击阅读 api 文档,你会很熟悉,下面接口调用部分可以忽略了,自行玩吧。
本地也可以访问:http://localhost:3001/api/docs/
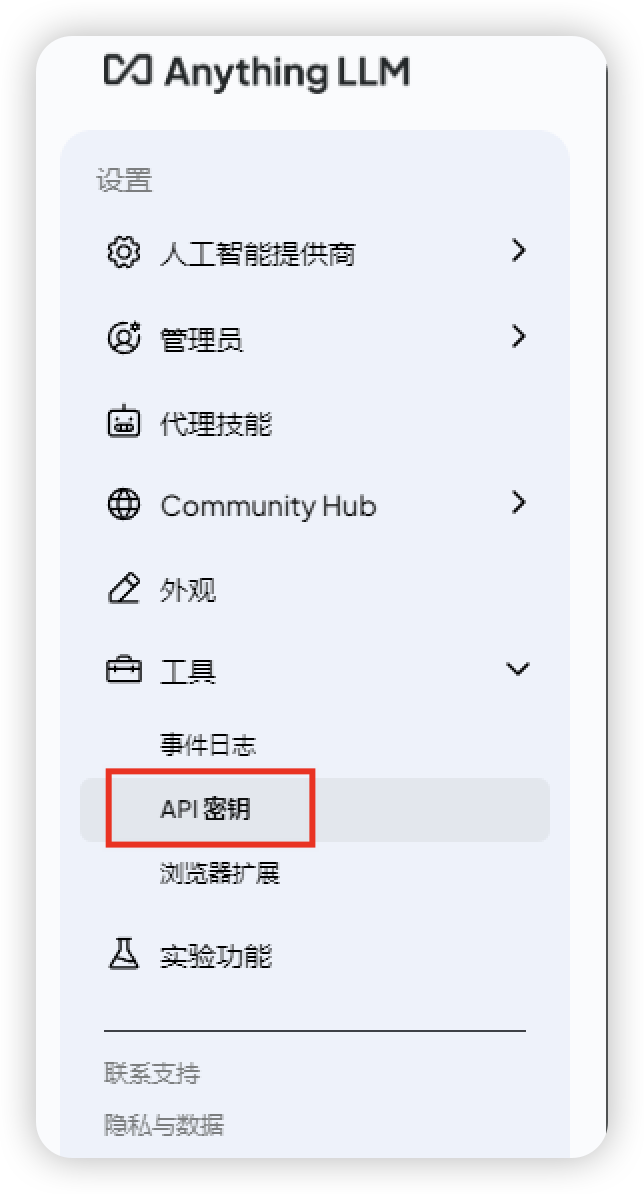
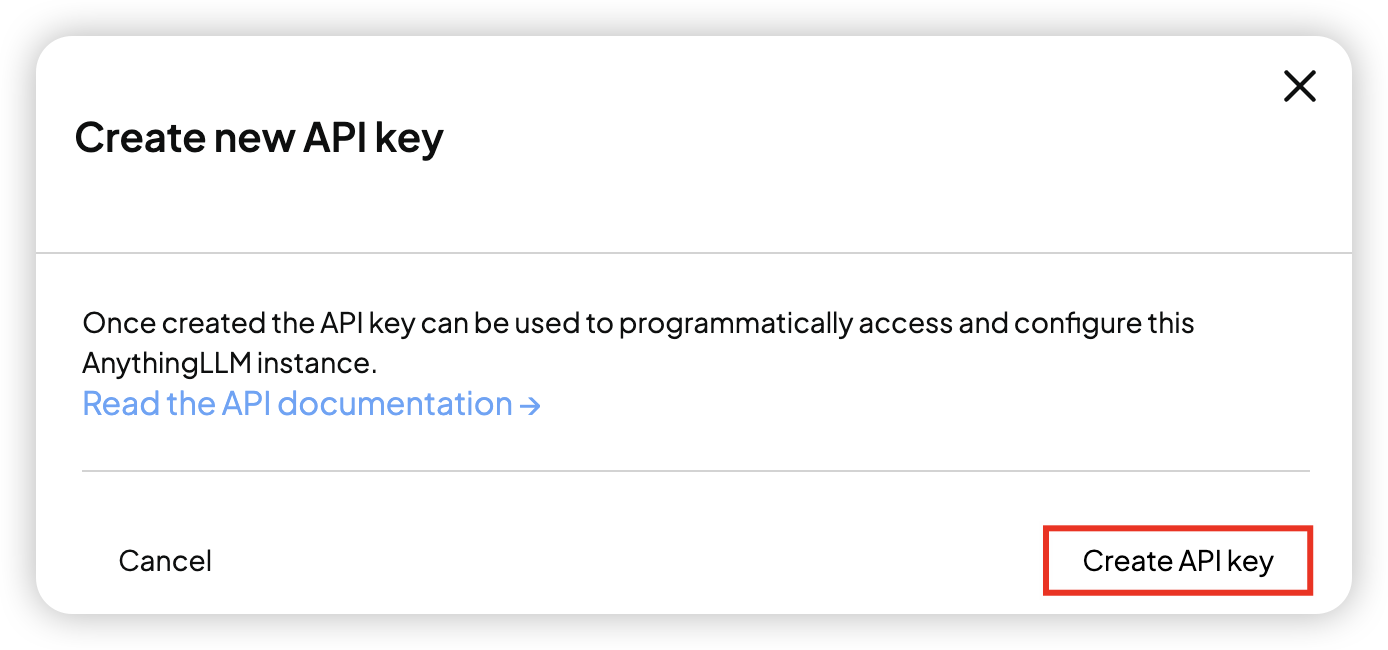
点开 api 文档中,authorize,将生成的 apikey 录入:

调用接口测试是否成功:

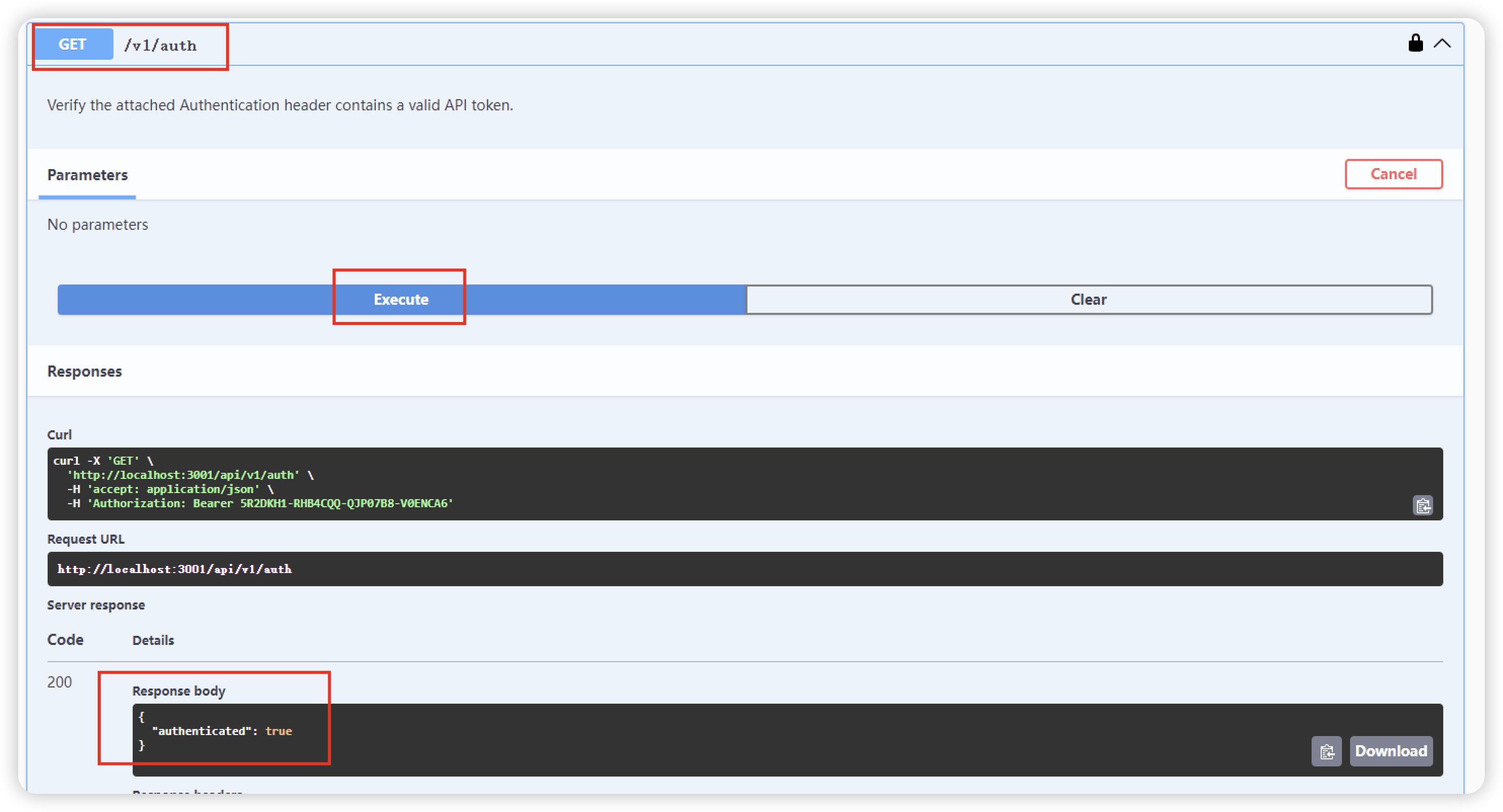
运行第一个借口/v1/auth,如果返回截图中的结果,即调用成功。
2. 创建工作区:
import requests
# 替换为实际的 API 端点
api_url = "http://localhost:3001/api/v1/workspace/new"
# 身份验证,设置请求头
headers = {
"accept": "application/json",
"Authorization": "Bearer your_api_key", #注意,替换apikey一定要保留Bearer
"Content-Type": "application/json"
}
# 准备创建工作区所需的数据
workspace_data = {
"name": "New Workspace", #我这里创建的 ddj,替换成你的工作空间
"similarityThreshold": 0.7,
"openAiTemp": 0.7,
"openAiHistory": 20,
"openAiPrompt": "Custom prompt for responses",
"queryRefusalResponse": "Custom refusal message",
"chatMode": "chat",
"topN": 4
}
try:
# 发送 POST 请求
response = requests.post(api_url, headers=headers, json=workspace_data)
# 检查响应状态码
if response.status_code == 200: # 200 表示创建成功
result = response.json()
print("工作区创建成功:", result)
else:
print(f"工作区创建失败,状态码:{response.status_code},错误信息:{response.text}")
except requests.RequestException as e:
print(f"请求发生错误:{e}")
执行输出如下结果,则为成功,如果不成功,仔细看我上面的每一行代码 注释地方要特别注意。
#如下结果则执行成功
{
"workspace": {
"id": 4,
"name": "ddj",
"slug": "ddj",
"vectorTag": null,
"createdAt": "2025-02-10T16:14:58.744Z",
"openAiTemp": 0.7,
"openAiHistory": 20,
"lastUpdatedAt": "2025-02-10T16:14:58.744Z",
"openAiPrompt": "Custom prompt for responses",
"similarityThreshold": 0.7,
"chatProvider": null,
"chatModel": null,
"topN": 4,
"chatMode": "chat",
"pfpFilename": null,
"agentProvider": null,
"agentModel": null,
"queryRefusalResponse": "Custom refusal message",
"vectorSearchMode": "default"
},
"message": null
}
3. 执行嵌入操作(文档上传):
# Python调用AnythingLLM文档上传API
import requests
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"accept": "application/json" }
files = {'file': open('product_guide.pdf', 'rb')}
response = requests.post(
'http://localhost:3001/api/v1/workspace/{workspace_id}/document',
headers=headers,
files=files
)
print(response.json()) # 返回文档ID及处理状态 ``
关键参数:
workspace_id: 目标工作区ID(可通过GET /api/v1/workspaces获取),也可以在 swagger 中调用,如下(屏幕不够大,截图范围有限,不过核心的都截到了)file
2.2 向量数据库管理- 默认数据库:LanceDB(无需额外配置)。
- 高级选项:支持Chroma、Pinecone等数据库,优化检索性能。后期会出针对文档向量化的方法,这块有很多细节需要注意,目前先将整个流程走通。
三、API调用与问答系统开发
3.1 生成API密钥
- 在AnythingLLM设置界面创建API Key,权限设置为
Full Access。 - 密钥格式:
Bearer {API_KEY},需加入请求头。
3.2 Python调用示例
import requests
import jsondef
ask_anythingllm(question, workspace_name, api_key):
url = f"http://localhost:3001/api/v1/workspace/{workspace_name}/chat"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
"accept": "application/json"
}
data = {
"message": question,
"mode": "query" # 可选chat/query模式
}
response = requests.post(url, headers=headers, json=data)
if response.status_code == 200:
result = response.json()
# 提取有效回答(去除思考过程)
answer = result['textResponse'].split('</think>')[-1].strip()
sources = result.get('sources', [])
return answer, sources
else:
return f"Error: {response.text}", []
# 示例调用
api_key = "your_api_key" #替换成你自己的apikey
workspace = "product_kb"
question = "道德经讲的是什么,用50个字概括"
answer, sources = ask_anythingllm(question, workspace, api_key)
print("回答:", answer)
print("来源:", [src['title'] for src in sources])
执行效果:
回答: 道德经讲的是“无为而治、柔弱胜刚强、厚积薄发”,强调以智慧和德行为本,以柔克刚,顺其自然,实现内心与外在的平衡。
来源: ['ddj.txt']
3.3 高级功能扩展
- 多工作区隔离:为不同部门创建独立知识库。
- 对话历史管理:通过
chatId参数实现多轮对话上下文保持。
四、优化与故障排查
4.1 性能调优建议
- 模型选择:根据硬件配置选择模型尺寸(如
deepseek-r1:8bvs70b)。 - 分块策略:调整文档分割大小(默认512 tokens)以平衡精度与速度。
4.2 常见问题解决
| 问题现象 | 解决方案 |
|---|---|
| API返回403错误 | 检查API密钥权限及有效期 |
| 文档嵌入失败 | 确认文件格式兼容性,尝试重新上传 |
| 响应速度慢 | 增加Ollama的num_ctx参数提升上下文容量 |
| api执行报错 | 建议用swager上测试,没问题再编辑代码,如果执行不下去,尝试切换anythingllm 版本 |


















 5920
5920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









