









 本文深入探讨了C++编程中的关键实践,包括延后变量定义以减少构造开销,避免不必要的类型转换以提高效率,避免返回对象内部句柄以保护数据完整性,追求异常安全的代码设计,理解和使用内联函数优化性能,以及减少文件间的编译依赖。这些最佳实践有助于提升代码质量、性能和可维护性。
本文深入探讨了C++编程中的关键实践,包括延后变量定义以减少构造开销,避免不必要的类型转换以提高效率,避免返回对象内部句柄以保护数据完整性,追求异常安全的代码设计,理解和使用内联函数优化性能,以及减少文件间的编译依赖。这些最佳实践有助于提升代码质量、性能和可维护性。
《Effictive C++》学习笔记 — 实现
条款26 — 尽可能延后变量定义式的出现时间
1、过早定义变量的代价
如果我们为一个定义了一个可能不使用的变量,我们就需要为之付出构造和析构的代价。在我的实际工作中,最有可能出现这种问题应该就是在使用goto语句的情况下。为了使所有函数中new的资源都得到释放,会在每次出错都跳到goto标签处执行。
class CLS_Test{};
int test()
{
char* pc = new char[1024];
CLS_Test* pTest = new CLS_Test;
string strTemp;
int ret = -1;
if (...)
{
goto END;
}
...
// use strTemp;
END:
if (pc)
{
delete pc;
}
if (pTest)
{
delete pTest;
}
return ret;
}
goto语句要求所有变量的声明都在其之前,因此这里即使我们是在后面用的strTemp变量,也需要将它声明在前面,相应的也需要承担构造析构的成本。
2、延后变量定义直到获取到尽可能多的构造信息
void test(const char* _pcTemp)
{
string strTemp;
// change the content of the pointer
strTemp = _pcTemp;
}
void test(const char* _pcTemp)
{
// change the content of the pointer
string strTemp(_pcTemp);
}
显然是第二段代码更好一些,因为我们避免了一次赋值操作。然而,实际开发中,我们往往没有注意到这一点。因此,尽可能在拿到做够多的构造信息再去构造对象,降低函数调用等不必要的开销。
条款27 — 尽量少做转型动作
1、static_const 之新对象 or 原对象
来看一个派生类调用基类函数的例子。
class CLS_Window
{
public:
virtual void onResize()
{
cout << "CLS_Window: " << this << endl;
}
};
class CLS_WindowsWindow : public CLS_Window
{
public:
virtual void onResize()
{
static_cast<CLS_Window>(*this).onResize();
cout << "CLS_WindowsWindow: " << this << endl;
}
};
int main()
{
CLS_WindowsWindow window;
window.onResize();
}

代码貌似看着没问题,实际上问题出现在对于static_cast转换符的理解上了。我们可以以一条相同的赋值语句来代替然后就能理解其作用:
CLS_Window __windowTemp = (CLS_Window)(*this);
__windowTemp .onResize();
这里我们无意间创建了一个临时对象并且调用了临时对象的方法。结果是什么呢?就是resize行为没有作用在正确的基类部分上。
2、降低效率的dynamic_cast
我们知道dynamic_cast被用于动态类型转换,然而它的效率令人难以满意。
#include <iostream>
#include <ctime>
using namespace std;
class CLS_Layer1
{
virtual void test(){}
};
class CLS_Layer2 : public CLS_Layer1 {};
class CLS_Layer3 : public CLS_Layer2 {};
class CLS_Layer4 : public CLS_Layer3 {};
class CLS_Layer5 : public CLS_Layer4 {};
int main()
{
CLS_Layer1* pLayer = new CLS_Layer5;
time_t tStart = clock();
for (int i = 0; i < 100000000; i++)
{
CLS_Layer2* pLayer2 = dynamic_cast<CLS_Layer2*>(pLayer);
}
time_t tEnd = clock();
cout << "time(dynamic_cast) = " << (tEnd - tStart) << endl;
tStart = clock();
for (int i = 0; i < 100000000; i++)
{
CLS_Layer2* pLayer2 = (CLS_Layer2*)pLayer;
}
tEnd = clock();
cout << "time(cast) = " << (tEnd - tStart) << endl;
}

我们执行了1亿次转换,可以看出执行效率大约为1:27。这正是由于dynamic_cast所采取的字符串比较策略所导致的。结合我们学习的vs实现typeid运算符的方式,我们不难推测出其基类字符串的存放位置:
int main()
{
CLS_Layer1* pLayer = new CLS_Layer5;
CLS_Layer1* pLayer2 = new CLS_Layer4;
CLS_Layer5* pLayerCast = dynamic_cast<CLS_Layer5*>(pLayer);
_RTTICompleteObjectLocator* pRtti = static_cast<_RTTICompleteObjectLocator***>((void*)pLayer)[0][-1];
_RTTIClassHierarchyDescriptor* pClass = pRtti->pClassDescriptor;
_RTTICompleteObjectLocator* pRtti2 = static_cast<_RTTICompleteObjectLocator***>((void*)pLayer2)[0][-1];
_RTTIClassHierarchyDescriptor* pClass2 = pRtti2->pClassDescriptor;
cout << "pClass->pBaseClassArray->arrayOfBaseClassDescriptors = " << pClass->pBaseClassArray->arrayOfBaseClassDescriptors << endl;
cout << "pClass2->pBaseClassArray->arrayOfBaseClassDescriptors = " << pClass2->pBaseClassArray->arrayOfBaseClassDescriptors << endl;
cout << endl;
for (int i = 0; i < pClass->numBaseClasses; i++)
{
cout << (pClass->pBaseClassArray->arrayOfBaseClassDescriptors[i])->pTypeDescriptor->name << endl;
}
cout << endl;
for (int i = 0; i < pClass2->numBaseClasses; i++)
{
cout << (pClass2->pBaseClassArray->arrayOfBaseClassDescriptors[i])->pTypeDescriptor->name << endl;
}
cout << endl;
}
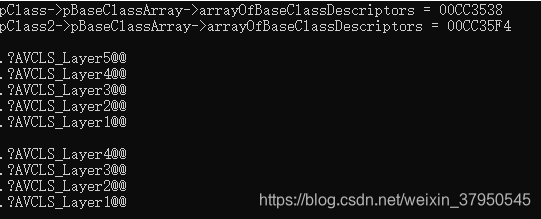
这里我们可以看出在单继承体系中,每个类的基类描述符数组各不相同,这样才保证能定位到属于自己的基类描述符。那么,为了减小比较开销,在存储的时候,继承层次越深的类的信息放的越靠前。
这里提到在工作中以前确实写过这样的代码:
void func(CLS_Base* p)
{
if (dynamic_cast<class1>(p) != nullptr)
{
...
}
else if (dynamic_cast<class2>(p) != nullptr)
{
...
}
else if (dynamic_cast<class1>(p) != nullptr)
{
...
}
else if (dynamic_cast<class1>(p) != nullptr)
{
...
}
}
效率着实低!这种情况还不如使用typeinfo.name简单。
3、减少对dynamic_cast的使用
书上提出了两种办法:
(1)直接使用派生类指针
(2)在基类中为所有外部需要调用的函数提供默认的虚函数版本
有时我们需要在两种办法中权衡,但是无论哪种,可以预见其效率定高于dynamic_cast
4、使用函数隔离转型的操作
条款28 — 避免返回handles指向对象内部成分
1、常量性的破坏
这一条款和条款21以及条款03遥相呼应,我们把条款03中的例子再拿出来看一下:
using namespace std;
class CLS_Test
{
char* m_pcStr;
public:
explicit CLS_Test(const char* _pcInit)
{
m_pcStr = new char(strlen(_pcInit) + 1);
if (m_pcStr != nullptr)
{
strcpy_s(m_pcStr, strlen(_pcInit) + 1, _pcInit);
}
}
char& operator[] (std::size_t position) const
{
return m_pcStr[position];
}
~CLS_Test()
{
delete m_pcStr;
}
};
int main()
{
CLS_Test clsTest("test");
char* pc = &clsTest[0];
*pc = 'a';
cout << clsTest[0];
return 0;
}
让我们再分析下为什么这段代码编译可以通过。C++中const成员函数的常量性指的是位常量性,即要求函数内部不能修改任何成员变量的值,同时不能返回非const引用或指针指向成员变量。我们这里 operator[] 满足上述两个条件,但是它返回了通过成员变量指针访问的数据存储。这使得用户可以修改其数据,破坏了常量性!同时,这也给了我们两个教训:
(1)成员变量的封装性最多只等于返回其引用函数的访问级别 这里m_pcStr成员变量虽然是私有的,然而用户可以通过 [] 操作符对其进行修改,因此其封装性其实可以当做公有。
(2)const成员函数仅保证存储在对象地址空间内的数据不变 这也是我们这里常量性被破坏的原因。m_pcStr自身不可作为引用被返回,因为其地址空间位于对象内部;然而其指向的数据却可以作为引用被返回。尽管它们才是真正保存数据的位置,然而它们并没有为对象的存储空间中。
除了不应返回指向关联数据的引用,我们还要避免在成员函数中返回级别更低的函数引用:
#include <iostream>
using namespace std;
class CLS_Test
{
private:
typedef void (CLS_Test::*voidFunc)();
void privateFunc()
{
cout << "privateFunc" << endl;
}
public:
voidFunc publicFunc() const
{
return &CLS_Test::privateFunc;
}
};
int main()
{
CLS_Test test;
auto func = test.publicFunc();
(test.*func)();
}
2、悬挂引用
显然,上述问题的解决办法之一是给返回值类型加上const,然而,这样会引发悬挂引用(野指针)的问题。
const char* test()
{
return &CLS_Test("test")[0];
}
void func()
{
const char* pc = test();
...
}
这里由于临时变量的引入会导致pc称为一个野指针,指向已经被释放的内存。
因此,我们说尽量不要让成员函数返回句柄。因为这样会导致句柄的不确定使用;同时句柄的生命周期不能保持和对象一致。然而,像我们的operator[]有时必须返回引用,这也是为了让我们操作类似vector和string这样的类能和操作数组一样。
条款29 — 为“异常安全”而努力是值得的
1、异常安全条件
这里我们引用书中的例子。考虑一个包含背景的窗口,其支持多线程操作,因此包含一个互斥器,代码使用Qt写起来简单些:
#include <QImage>
#include <QMutex>
#include <QFile>
class CLS_MyWindow
{
QImage* m_pBackImg;
QMutex m_mutex;
int m_ImageChanges;
public:
void changeBackground(QFile &file)
{
m_mutex.lock();
delete m_pBackImg;
++m_ImageChanges;
m_pBackImg = new QImage(file.readAll());
m_mutex.unlock();
}
};
这里我们不难发现,changeBackground这个函数十分危险。结合我们前面所学,在new引发异常的时候,m_pBackImg所指向的对象已经被销毁了,而m_pBackImg并没有指向有效的指针;除此之外,另外两个显而易见的问题是:锁永远无法得到释放;m_ImageChanges也不适当的进行了计数增加。由此,我们可以得到异常安全的条件:
不泄露任何资源 锁的释放问题 — 我们可以使用对象资源管理(条款13)的方法解决
不允许数据败坏 对象数据的部分修改 — 现在我们需要专注于此问题
2、异常安全函数的三个保证
基本承诺 — 如果异常抛出,所有对象都处于一种内部前后一致的状态。针对前面例子中的changeBackground函数,在其抛出异常后,我们可以选择让其背景使用缺省背景或是保持原背景不变。这两种状态都可以成为一致性状态。为什么称其为基本承诺呢?因为客户无法预知哪种情况将发生,除非他们调用显示函数在屏幕上输出图像。
强烈保证 — 如果函数成功,就是完全成功;如果函数失败,将会回到调用之前的状态。
不抛掷保证 — 承诺绝不抛出异常,因为它们总是能完成他们原先承诺的功能。作用域内置类型的所有操作都提供nothrow保证。
显然不抛出异常是最好的选择。然而,现在我们所写的大多数函数都会抛出异常;即使程序员愿意在内部使用try-catch捕获所有异常并进行异常处理,大部分情况下我们还是应该将出现的问题暴露给用户,而不是内部消化。
3、强烈的异常安全保证 ?
针对上面的changeBackground我们给出一个看似强烈保证的异常安全版本:
class CLS_MyWindow
{
QSharedPointer<QImage> m_pBackImg;
QMutex m_mutex;
int m_ImageChanges;
public:
void changeBackground(QFile &file)
{
QMutexLocker(&(this->m_mutex));
m_pBackImg.reset(new QImage(file.readAll()));
++m_ImageChanges;
}
};
这个版本通过使用我们前面所学的使用资源管理对象以及改编代码执行顺序增加了异常安全性。然而,其是否提供强烈的异常安全保证还需要取决于QImage的构造函数是否提供了这样的特性。如果QFile在读取过程中抛出了异常,而其内部的文件指针没有归位,它就不能提供强烈的异常安全保证。所以,函数的异常安全保证级别也符合短板效应 — 取决于调用函数链中异常安全保证最差的函数。
4、copy and swap
假设我们忽略上面所说的这种子函数的问题。那么我们有一种一般化的设计策略可以提供强烈异常安全保证 — copy and swap。其原则是:为我们打算修改的对象创建副本,在副本上进行内容修改。修改完毕后将临时对象通过不抛出异常的swap函数拷贝到目标对象中。这里我们常常会使用私有类指针保存数据。
struct STRUCT_PImpl
{
QSharedPointer<QImage> m_pBackImg;
int m_ImageChanges;
};
class CLS_MyWindow
{
protected:
QMutex m_mutex;
QSharedPointer<STRUCT_PImpl> pImpl;
public:
void changeBackground(QFileDevice &file)
{
QMutexLocker(&(this->m_mutex));
QSharedPointer<STRUCT_PImpl> temp(new STRUCT_PImpl(*pImpl));
temp->m_pBackImg.reset(new QImage(file.read(1000)));
++temp->m_ImageChanges;
qSwap(temp, pImpl);
}
};
这里为了简单表示,没有将声明和实现分开在不同的文件。否则这里的结构体应该出现在实现文件中,然后使用前向声明在头文件中引用。
这是一个很好的提供异常安全保证的办法。然而,实际应用中,往往存在两个问题:
(1)拷贝和交换过程中可能调用其它函数,我们不能确定它们的异常安全保证。再进一步说,如果前面的函数发生异常而后面的函数没有发生异常,我们应该怎样使前面的函数回到初始状态呢?
(2)拷贝的开销是相当大的,因为这里我们执行的必然是深拷贝。
因此,在强烈保证不合实际时,我们必须提供基本的异常安全保证。对于大多数函数而言,这是一个“合情合理”的选择。然而,如果我们选择完全不提供异常安全的保证呢?根据短板效应,整个系统都将不具备异常安全性!不幸的是,如果我们调用许多旧版本的C++代码,那么系统的异常安全性将很难得到保证。
综上,我们得到的经验是:在写代码时,先考虑以对象管理资源防止资源泄漏;然后从三个异常安全保证级别挑选可施行的最高等级。只有当我们调用了旧版的C++代码时,才能将之设置为无异常安全保证级别。最后,我们需要将确定过程使用文档记录下来,为函数用户以及该模块的后继维护者提供说明。
条款30 — 透彻了解inlining的里里外外
我们对inline函数都很熟悉了,其和普通函数相比,体积往往会更大但执行效率却更快。
1、inline函数是否inline
通常情况下,我们说内联函数的特点是:其函数体不会出现在生成的文件中,而是被直接替换到调用处。然而我们使用inline关键字声明函数,仅仅表示函数编写者向编译器发出内联申请。至于内联是否进行,取决于编译器的实现,以及我们的其他代码。
在vs2019进行测验时,默认情况下函数内联是被关闭的。也就是说使用inline修饰的函数还是通过调用的方式执行函数。只有当我们开启了优化,内联函数才会在可执行文件中被替换到调用处。
除此之外,在以下的情况中,内联函数的函数体仍将存在可执行文件中:
#include <iostream>
using namespace std;
class CLS_InlineTest
{
public:
virtual inline void test()
{
cout << "CLS_InlineTest::test" << endl;
}
};
inline void test()
{
cout << "test" << endl;
}
int main()
{
auto pF = &test;
pF(); // 1.call by function pointer
CLS_InlineTest *testInline = new CLS_InlineTest;
testInline->test(); // 2.call with polymorphism
return 0;
}
2、在选择inline前充分评估
在使用inline函数时,构造函数和析构函数等往往会让人做出错误的选择。
class CLS_Base
{
public:
inline CLS_Base()
{
... // about 50 lines
}
};
class CLS_Derived : public CLS_Base
{
public:
CLS_Derived();
~CLS_Derived();
};
CLS_Derived::CLS_Derived()
{
}
CLS_Derived::~CLS_Derived()
{
}
此时派生类的构造函数和析构函数看上去再简单不过,可以声明为inline函数。然而,不要忘了我们前面所学的编译器行为。
CLS_Derived::CLS_Derived()
{
try
{
CLS_Base();
}
catch
{
~CLS_Base();
}
}
因此,如果我们将派生类的构造函数或者基类的析构函数声明为内联函数,都并非一个好的选择。这会导致该类的父类和成员变量中使用 inline 声明的构造函数体都在该类的构造函数中进行一份复制。
慎用inline!
条款31 — 将文件间的编译依存关系降至最低
1、接口和实现未分离
传统的C++代码实现一个类的方式如下:
class CLS_Person
{
public:
CLS_Person(string _name, int _age);
int getAge();
string getName();
private:
string m_strName;
int m_iAge;
};
这有什么问题呢?数据的封装性没有问题,而且也提供了公有接口进行访问。然而,这里没有将实现与接口分离。这就是说,如果我们将头文件提供给别人(动态库头文件),他们完全可以从我们的数据声明中了解我们的实现方式。进一步讲,如果我们改变头文件中的私有变量(例如我们改用char* 去存放name),所有引用此文件的代码都需要重新编译(否则就会出现二进制不兼容的问题)。
请注意,这里直属于CLS_Person的成员变量必须声明在头文件中,因为在编译时编译器需要知道类对象的大小。
2、pImpl(pointer to implementation)原理
前面我们提供很多次这种实现方式,这里简单列出代码:
// CLS_Person.h
class CLS_PersonImpl;
class CLS_Person
{
public:
CLS_Person(string _name, int _age);
int getAge();
string getName();
private:
unique_ptr<CLS_PersonImpl> pImpl;
};
// CLS_Person.cpp
class CLS_PersonImpl
{
private:
string m_strName;
int m_iAge;
};
这里我们分离实现与定义的关键在于以声明的依存性替换定义的依存性。这是因为,声明可以使用不完备类型,而定义必须清楚地知道类型的大小。因此,在声明中:
如果使用引用和指针可以完成任务,就不要使用对象(这里指的是定义变量时)
如果能够使用前向声明就不要引入头文件(前向声明支持按值传参和返回的函数声明)
为声明式和定义式提供不同的头文件(这里的声明式指的是前向声明,定义式指的是函数和类的声明)
3、handle类:请求转发
我们这里所说的CLS_PersonImpl类为真正实现功能的类,也被称为handle类。
显然,最简单的实现方式就是公有接口内部将所有请求都转发给私有类指针:
string CLS_Person::getName()
{
return pImpl->getName();
}
我们需要额外执行的操作包括:通过对象指针间接访问对象;在对象中保存私有类指针;动态分配私有类对象。
4、interface类:工厂方法
这里我们还可以将CLS_Person设计为一个对用户公开的接口来分离实现:
// CLS_AbsPerson.h
class CLS_AbsPerson
{
public:
static shared_ptr<CLS_AbsPerson> create();
~CLS_AbsPerson();
virtual int getAge() = 0;
virtual string getName() = 0;
};
具体的功能将由对用户隐藏的子类完成:
// CLS_CommonPerson.h
class CLS_CommonPerson : public CLS_AbsPerson
{
public:
CLS_CommonPerson(string _strName, int _iName);
virtual int getAge() override;
virtual string getName() override;
private:
string name;
int age;
};
这里使用依赖倒转原则分离了接口与实现。我们需要额外执行的操作包括:虚函数的间接调用;虚函数指针的内存。

















 7573
7573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









