




SpringAI–基于MySQL的持久化对话记忆实现
SpringAI目前提供了一些将对话保存到不同数据源中的实现,比如:
- InMemoryChatMemory 基于内存存储
- CassandraChatMemory 在Cassandra中带有过期时间的持久化存储。
- Neo4jChatMemory 在Neo4j中没有过期时间限制的持久化存储。
- JdbcChatMemory 在JDBC中没有过期时间限制的持久化存储。
如果要将对话持久化到数据库中,就可以使用JdbcChatMemory。但是spring-ai-starter-model-jdbc依赖模板版本很少,而且缺乏相关介绍,Maven官方仓库还搜不到依赖,所以不推荐使用。在Spring仓库能搜到,但是用的人太少了。
SpringAI源码中只有InMemoryChatMemory实现了ChatMemory。
所以可以自己自定义一个数据库持久化对话记忆。
自定义实现
Spring AI的对话记忆实现非常巧妙,解耦了“存储”和“记忆算法”。
- 存储:ChatMemory:我们可以单独修改
ChatMemory存储来改变对话记忆的保存位置,而无需修改保存对话记忆的流程。 - 记忆算法:ChatMemory Advisor,advisor可以理解为拦截器,在调用大模型时的前或后执行一些操作
- MessageChatMemoryAdvisor: 从记忆中(ChatMemory)检索历史对话,并将其作为消息集合添加到提示词中。常用。能更好的保持上下文连贯性。
- PromptChatMemoryAdvisor: 从记忆中检索历史对话,并将其添加到提示词的系统文本中。可以理解为没有结构性的纯文本。
- VectorStoreChatMemoryAdvisor: 可以用向量数据库来存储检索历史对话。
ChatMemory接口的方法并不多,需要实现对话消息的增、删、查就可以了。
源码中的conversationId就相当于会话id,每个用户可以有自己的会话id,这个值可以自己来生成,在调用的时候传过去就可以了,就是根据这个值实现了多轮对话(多轮对话的本质实际上就是把历史消息拼接上新的消息再一起发送给大模型)。
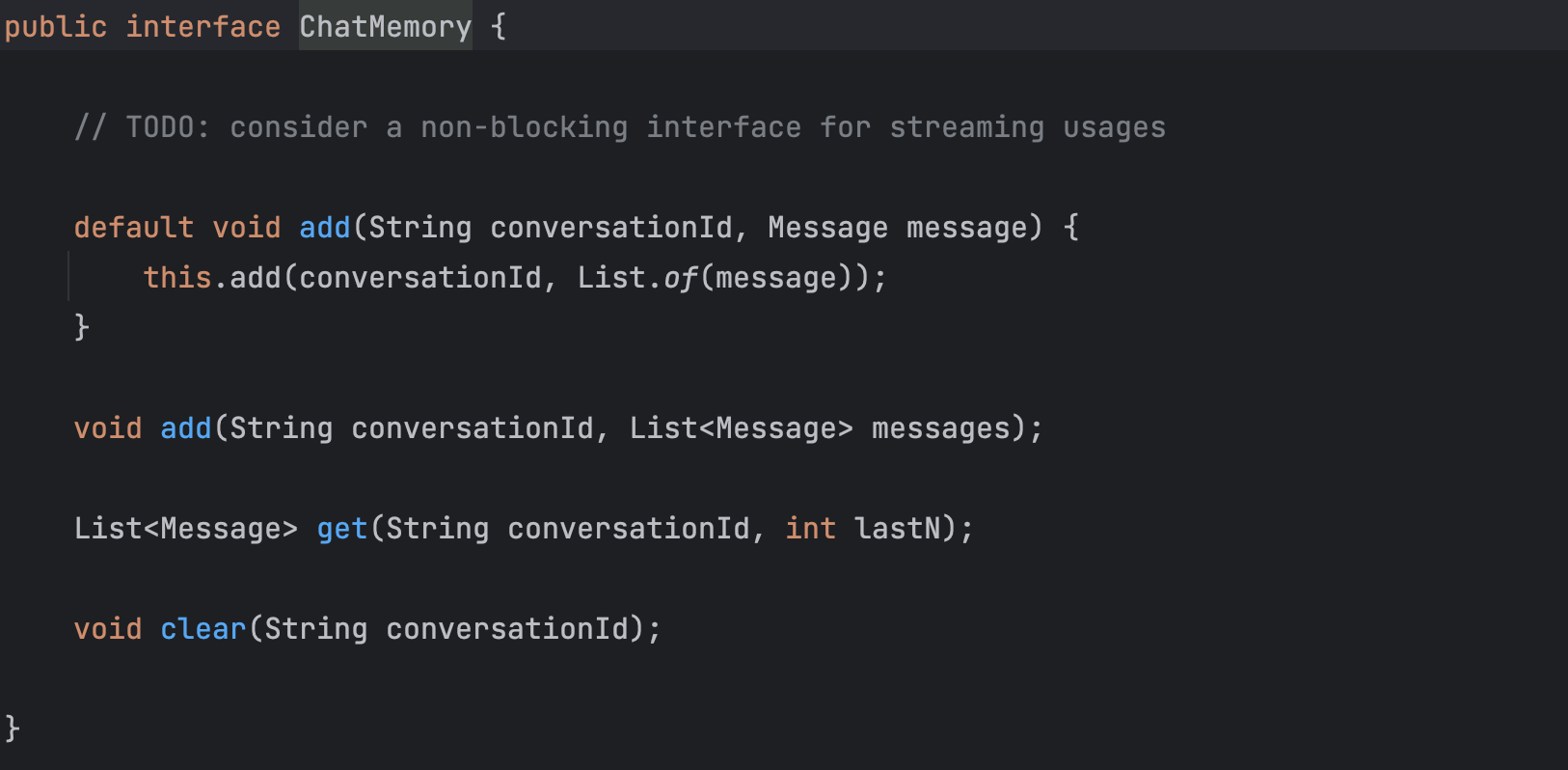
自定义持久化ChatMemory
版本
- JDK21
- Springboot 3.4.5
- Spring AI Alibaba 1.0.0-M6.1
- mysql驱动 8.0.32
- mybatis plus 3.5.12
依赖
<!--Spring AI Alibaba-->
<!--Spring AI 还不支持国产大模型,所以使用Alibaba-->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter</artifactId>
<version>1.0.0-M6.1</version>
</dependency>
<!-- MySQL 驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.32</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.baomidou/mybatis-plus-boot-starter -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-spring-boot3-starter</artifactId>
<version>3.5.12</version>
</dependency>
<!-- 3.5.9及以上版本想使用mybatis plus分页配置需要单独引入-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-jsqlparser</artifactId>
<version>3.5.12</version> <!-- 确保版本和 MyBatis Plus 主包一致 -->
</dependency>
SQL
CREATE TABLE ai_chat_memory (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
conversation_id VARCHAR(255) NOT NULL comment '会话id',
type VARCHAR(20) NOT NULL comment '消息类型',
content TEXT NOT NULL comment '消息内容',
create_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP comment '创建时间',
update_time TIMESTAMP default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间',
is_delete tinyint default 0 not null comment '是否删除',
INDEX idx_conv (conversation_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
配置
大模型使用的是阿里的百炼大模型
spring:
application:
name: yy-ai-agent
profiles:
active: local
ai:
dashscope:
api-key: ${DASH_SCOPE_API_KEY}
chat:
options:
model: qwen-max
datasource:
url: jdbc:mysql://localhost:3306/your_database?useUnicode=true&characterEncoding=UTF-8&connectionCollation=utf8mb4_unicode_ci&serverTimezone=Asia/Shanghai
username: your_username
password: your_password
driver-class-name: com.mysql.cj.jdbc.Driver
mybatis-plus:
configuration:
map-underscore-to-camel-case: false
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
db-config:
logic-delete-field: isDelete # 全局逻辑删除的实体字段名
logic-delete-value: 1 # 逻辑已删除值(默认为 1)
logic-not-delete-value: 0 # 逻辑未删除值(默认为 0)
model
import com.baomidou.mybatisplus.annotation.*;
import java.io.Serializable;
import java.util.Date;
import lombok.Data;
/**
*
* @TableName ai_chat_memory
*/
@TableName(value ="ai_chat_memory")
@Data
public class AiChatMemory implements Serializable {
/**
*
*/
@TableId(type = IdType.AUTO)
private Long id;
/**
* 会话id
*/
@TableField("conversation_id")
private String conversationId;
/**
* 消息类型
*/
@TableField("type")
private String type;
/**
* 消息内容
*/
@TableField("content")
private String content;
/**
* 创建时间
*/
@TableField("create_time")
private Date createTime;
/**
* 更新时间
*/
@TableField("update_time")
private Date updateTime;
/**
* 是否删除
*/
@TableLogic
@TableField("is_delete")
private Integer isDelete;
}
mapper
注意在项目启动类上加上@MapperScan("自己mapper所在报名")。
@Mapper
public interface AiChatMemoryMapper extends BaseMapper<AiChatMemory> {
}
mybatis plus分页配置
这块有个坑,mybatis plus 3.5.9及以上版本想使用mybatis plus分页配置需要再引入一个mybatis-plus-jsqlparser的包,单纯只引入mybatis-plus-spring-boot3-starter这个依赖会找不到PaginationInnerInterceptor这个类。
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
@Configuration
public class MyBatisPlusConfig {
/**
* 注册 MyBatis-Plus 拦截器并添加分页插件
*/
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
// 指定数据库类型为 MySQL,构造分页内置拦截器
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}
ChatMemory实现
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.core.aiagent.mapper.AiChatMemoryMapper;
import com.core.aiagent.model.AiChatMemory;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.messages.AssistantMessage;
import org.springframework.ai.chat.messages.Message;
import org.springframework.ai.chat.messages.SystemMessage;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
@Component
public class MyBatisPlusChatMemory implements ChatMemory {
@Autowired
private AiChatMemoryMapper mapper;
@Override
public void add(String conversationId, Message message) {
AiChatMemory aiChatMemory = new AiChatMemory();
aiChatMemory.setConversationId(conversationId);
aiChatMemory.setType(message.getMessageType().getValue());
aiChatMemory.setContent(message.getText());
mapper.insert(aiChatMemory);
}
@Override
public void add(String conversationId, List<Message> messages) {
List<AiChatMemory> aiChatMemories = new ArrayList<>();
for (Message message : messages) {
AiChatMemory aiChatMemory = new AiChatMemory();
aiChatMemory.setConversationId(conversationId);
aiChatMemory.setType(message.getMessageType().getValue());
aiChatMemory.setContent(message.getText());
aiChatMemories.add(aiChatMemory);
}
mapper.insert(aiChatMemories);
}
@Override
public List<Message> get(String conversationId, int lastN) {
// 分页查询最近N条记录
Page<AiChatMemory> page = new Page<>(1, lastN);
QueryWrapper<AiChatMemory> wrapper = new QueryWrapper<>();
wrapper.eq("conversation_id", conversationId)
.orderByDesc("create_time");
List<AiChatMemory> aiChatMemories = mapper.selectList(wrapper);
// 反转列表,使得最新的消息在最后
Collections.reverse(aiChatMemories);
// 转换为Message对象
List<Message> messages = new ArrayList<>();
for (AiChatMemory aiChatMemory : aiChatMemories) {
String type = aiChatMemory.getType();
switch (type) {
case "user" -> messages.add(new UserMessage(aiChatMemory.getContent()));
case "assistant" -> messages.add(new AssistantMessage(aiChatMemory.getContent()));
case "system" -> messages.add(new SystemMessage(aiChatMemory.getContent()));
default -> throw new IllegalArgumentException("Unknown message type: " + type);
}
}
return messages;
}
@Override
public void clear(String conversationId) {
// 删除指定会话的所有消息
QueryWrapper<AiChatMemory> wrapper = new QueryWrapper<>();
wrapper.eq("conversation_id", conversationId);
mapper.delete(wrapper);
}
}
使用自定义持久化的ChatMemory
import com.core.aiagent.advisor.MyLoggerAdvisor;
import com.core.aiagent.chatmemory.MyBatisPlusChatMemory;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.MessageChatMemoryAdvisor;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.memory.InMemoryChatMemory;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.model.ChatResponse;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.util.List;
import static org.springframework.ai.chat.client.advisor.AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY;
import static org.springframework.ai.chat.client.advisor.AbstractChatMemoryAdvisor.CHAT_MEMORY_RETRIEVE_SIZE_KEY;
@Component
@Slf4j
public class LoveApp {
private ChatClient chatClient;
// mysql对话记忆
@Autowired
private MyBatisPlusChatMemory chatMemory;
private static final String SYSTEM_PROMPT = "自己随便写点什么";
public LoveApp(ChatModel dashScopeChatModel) {
// 对话记忆,创建一个内存对话记忆
//ChatMemory chatMemory = new InMemoryChatMemory();
this.chatClient = ChatClient.builder(dashScopeChatModel)
.defaultSystem(SYSTEM_PROMPT)
// 指定默认advisor(类似拦截器),MessageChatMemoryAdvisor实现对话记忆功能,chatMemory是用来保存对话的
// .defaultAdvisors(...):注册「要用记忆」的能力。
.defaultAdvisors(
//new MessageChatMemoryAdvisor(chatMemory),
new MyLoggerAdvisor()
)
.build();
}
/**
*
* @param message 用户消息
* @param chatId 对话记忆的id
* @return ai回复
*/
public String doChat(String message, String chatId) {
ChatResponse chatResponse = chatClient.prompt()
.user(message)
// 指定对话记忆的id和对话记忆的长度(10条)
// .advisors(spec->...):告诉该能力「这次用哪个会话」「取多少历史」
.advisors(spec -> spec.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId)
.param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 5))
// 自定义mysql对话记忆
.advisors(new MessageChatMemoryAdvisor(chatMemory))
.call()
.chatResponse();
String text = chatResponse.getResult().getOutput().getText();
//log.info("用户消息: {}, 返回消息: {}", message, text);
return text;
}
}
单元测试
先执行testChat(),再执行testChatMemory(),会发现在执行testChatMemory()时,大模型返回的是testChat()方法中的执行的信息。
@Test
void testChat() {
String chatId = UUID.randomUUID().toString();
System.out.println("chatId: " + chatId);
// 第一轮对话
String message = "我是一个程序员,我叫xx";
String answer = loveApp.doChat(message, chatId);
Assertions.assertNotNull(answer);
// 第二轮对话
message = "我的另一半是yy,我想让她更爱我";
answer = loveApp.doChat(message, chatId);
Assertions.assertNotNull(answer);
// 第三轮对话
message = "我的另一半是谁来着,我刚刚提到过";
answer = loveApp.doChat(message, chatId);
Assertions.assertNotNull(answer);
}
@Test
void testChatMemory() {
// 取出数据库中的conversation_id
String chatId = "804e52bf-aa75-4a07-bb2e-ec93f47f4e1e";
System.out.println("chatId: " + chatId);
// 第一轮对话
String message = "我是谁,我的另一半叫什么";
String answer = loveApp.doChat(message, chatId);
Assertions.assertNotNull(answer);
}

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









