




 本文介绍了Flink作为实时处理领域的佼佼者,其核心是一个流式数据流执行引擎,支持多种API和类似SQL的操作。文章详细阐述了Flink的数据传输方式、作业流程、支持的数据源、强大的容错机制以及窗口功能,强调了Flink的高速计算、高稳定性、灵活性和易用性的特点。
本文介绍了Flink作为实时处理领域的佼佼者,其核心是一个流式数据流执行引擎,支持多种API和类似SQL的操作。文章详细阐述了Flink的数据传输方式、作业流程、支持的数据源、强大的容错机制以及窗口功能,强调了Flink的高速计算、高稳定性、灵活性和易用性的特点。
作为实时领域对飙spark的存在,flink现在已经得到广泛的使用了,既然能得到业界任何和使用,肯定有其过人之处,之后工作中也有可能会用到,了解一下总是没错的。
什么是flink
Flink核心是一个流式的数据流执行引擎,提供各种API,如Java、Scala和Python,同事支持类似SQL的操作。
为什么选flink
数据传输方式
首先需要了解两个概念:
1.流处理:当一条数据被处理完成后,序列化到缓存中,然后立刻通过网络传输到下一个节点,由下一个节点继续处理;
2.批处理:当一条数据被处理完成后,序列化到缓存中,并不会立刻通过网络传输到下一个节点,当缓存写满,就持久化到本地硬盘上,当所有数据都被处理完成后,才开始将处理后的数据通过网络传输到下一个节点。
故流处理的优势是低延迟,批处理的优势是高吞吐,而flink可以通过调整缓存块的超时阈值,灵活地权衡系统延迟和吞吐量。
作业流程
flink作业提交流程:
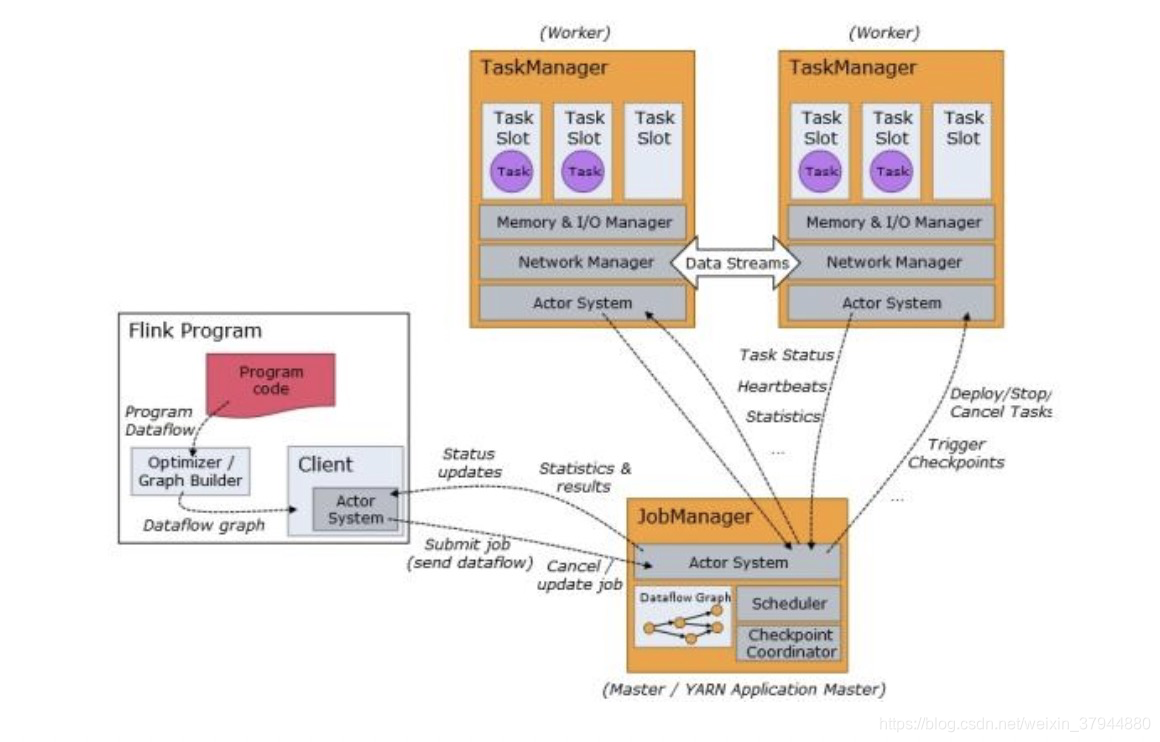
其中:
Program Code:我们编写的 Flink 应用程序代码;
Job Client:Job Client 不是 Flink 程序执行的内部部分,但它是任务执行的起点。 负责接受用户的程序代码,然后创建数据流,将数据流提交给 Job Manager。 执行完成后,将结果返回给用户;
Job Manager:主进程(也称为作业管理器)协调和管理程序的执行。 主要职责包括安排任务,管理checkpoint ,故障恢复等。机器集群中至少要有一个 master,master 负责调度 task,协调 checkpoints 和容灾,高可用设置的话可以有多个 master,但要保证一个是 l
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 475
475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









