









 本文深入解析Bengio的GATs论文,介绍了如何利用Multi-head Self-attention进行节点分类,通过计算节点的隐藏表示,实现inductive方法的应用。文章详细阐述了GAT结构,结合GCN和multi-head attention,特别关注了图注意力层的输入、输出及权重矩阵的计算,展示了注意力机制在图神经网络中的应用。
本文深入解析Bengio的GATs论文,介绍了如何利用Multi-head Self-attention进行节点分类,通过计算节点的隐藏表示,实现inductive方法的应用。文章详细阐述了GAT结构,结合GCN和multi-head attention,特别关注了图注意力层的输入、输出及权重矩阵的计算,展示了注意力机制在图神经网络中的应用。
今天读一读Bengio大神的GATs
本篇论文Introduction所介绍的文章路线比较清晰,可以拿来做个Roadmap。
任务:Node Classification
Idea: 通过Multi-head Self-attention,考虑节点的邻节点,计算每个节点的hidden representation。方法可直接应用于inductive方法。
GAT结构
本文结合了GCN和multi-head attention。
首先明确单个注意力层方法:
图注意力层输入为:
h
=
{
h
1
→
,
h
2
→
,
…
,
h
N
→
}
,
h
i
→
∈
R
F
h = \{ \overrightarrow {{h_1}} ,\overrightarrow {{h_2}} , \ldots ,\overrightarrow {{h_N}} \} ,\overrightarrow {{h_i}} \in {R^F}
h={h1,h2,…,hN},hi∈RF
N为节点数量,F为特征维度。
输出就是相应的新的节点特征,节点数量不变:
h
′
=
{
h
1
′
→
,
h
2
′
→
,
…
,
h
N
′
→
}
,
h
i
′
→
∈
R
F
′
h' = \{ \overrightarrow {{h_1'}} ,\overrightarrow {{h_2'}} , \ldots ,\overrightarrow {{h_N'}} \} ,\overrightarrow {{h_i'}} \in {R^F}'
h′={h1′,h2′,…,hN′},hi′∈RF′
以及一个应用于每个节点的权重矩阵:
W
∈
R
F
′
×
F
W \in {R^{F' \times F}}
W∈RF′×F
然后就可以在节点上进行self-attention操作了:
α
i
j
=
exp
(
L
e
a
k
y
R
e
L
U
(
a
→
T
[
W
h
i
→
∥
W
h
j
→
]
)
)
∑
k
∈
N
i
exp
(
L
e
a
k
y
R
e
L
U
(
a
→
T
[
W
h
i
→
∥
W
h
k
→
]
)
)
{\alpha _{ij}} = \frac{{\exp ({\rm{LeakyReLU(}}{{\overrightarrow a }^T}\left[ {W\overrightarrow {{h_i}} \left\| {W\overrightarrow {{h_j}} } \right.} \right]{\rm{)}})}}{{\sum\nolimits_{k \in {N_i}} {\exp ({\rm{LeakyReLU(}}{{\overrightarrow a }^T}\left[ {W\overrightarrow {{h_i}} \left\| {W\overrightarrow {{h_k}} } \right.} \right]{\rm{)}})} }}
αij=∑k∈Niexp(LeakyReLU(aT[Whi
Whk]))exp(LeakyReLU(aT[Whi
Whj]))
-
||为concatenation
-
a为一个全连接层,后面接了LeakyReLU,至于为什么是它,炼出来的吧
-
N_i不是节点i的所有邻节点也不是图中的所有节点,而是包括节点i在内的first-order neighbors. 这一过程是通过mask 邻接矩阵实现的
-
输出的alpha为归一化的注意力系数
上述公式如下图
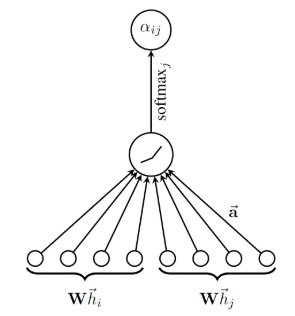
得到归一化的注意力权重系数alpha后,就可以计算每个节点的新的节点特征了,具体而言:
h
i
′
→
=
σ
(
∑
j
∈
N
i
α
i
j
W
h
j
→
)
\overrightarrow {{h_i}'} = \sigma (\sum\limits_{j \in {N_i}} {{\alpha _{ij}}W} \overrightarrow {{h_j}} )
hi′=σ(j∈Ni∑αijWhj)
因为N_i中包括了节点i本身及其first-order邻节点,所以新的特征融合了自身及其邻节点的信息。注意这里的W和alpha中的是同一个。
Multi-head也很简单,就是K个独立的注意力模块的concatenation:
h
i
′
→
=
∣
∣
k
=
1
K
σ
(
∑
j
∈
N
i
α
i
j
k
W
k
h
j
→
)
\overrightarrow {{h_i}'} = \mathop {||}\limits_{k = 1}^K \sigma (\sum\limits_{j \in {N_i}} {\alpha _{_{ij}}^k{W^k}} \overrightarrow {{h_j}} )
hi′=k=1∣∣Kσ(j∈Ni∑αijkWkhj)
总结
不难发现,上面基本在讨论Attention。因为GAT的权重矩阵W和alpha的计算完全不依赖于图的结构,这使得GAT是可以处理inductive问题的:
inductive问题是指:训练阶段与测试阶段的图结构不同,测试阶段需要处理未知的顶点,相当于训练阶段是整个数据图的子图。
另外GAT只根据邻节点计算注意力权重,这显然是充分利用了图结构的特点。如果将所有节点都考虑进来,无疑弱化了图结构的信息。
注意力机制被玩烂了,GAT之后也涌现了不少基于注意力机制的图网络。

















 1143
1143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









