




 本文介绍了使用Python的selenium库配合chrome浏览器爬取淘宝商品信息的初步心得。内容包括有头和无头模式的区别,以及在爬取需要登录的网页时,如何利用已有的Chrome用户信息进行模拟登录,避免手动操作。文章中提到了在实施过程中遇到的错误和解决办法,适合初学者参考。
本文介绍了使用Python的selenium库配合chrome浏览器爬取淘宝商品信息的初步心得。内容包括有头和无头模式的区别,以及在爬取需要登录的网页时,如何利用已有的Chrome用户信息进行模拟登录,避免手动操作。文章中提到了在实施过程中遇到的错误和解决办法,适合初学者参考。
python爬虫之selenium+chrome 爬去淘宝商品信息
初学selenium,有点小心得分享下~~
首先默认你安装好了selenium+chrome,其中chromedriver下载后把文件解压,然后放到本机chrome浏览器文件路径里,网上有很多配置方法,自行百度即可。
有头和无头
搜selenium发现有有头和无头两种,大概明白有头就是使用selenium会自动打开浏览器,无头就是在背后默默的运行,不打开浏览器。
有头模式:
from selenium import webdriver
driver = webdriver.Chrome()
driver.maximize_window() #将窗口最大化,最好加上这段代码避免出错
driver.get('https://www.taobao.com/')
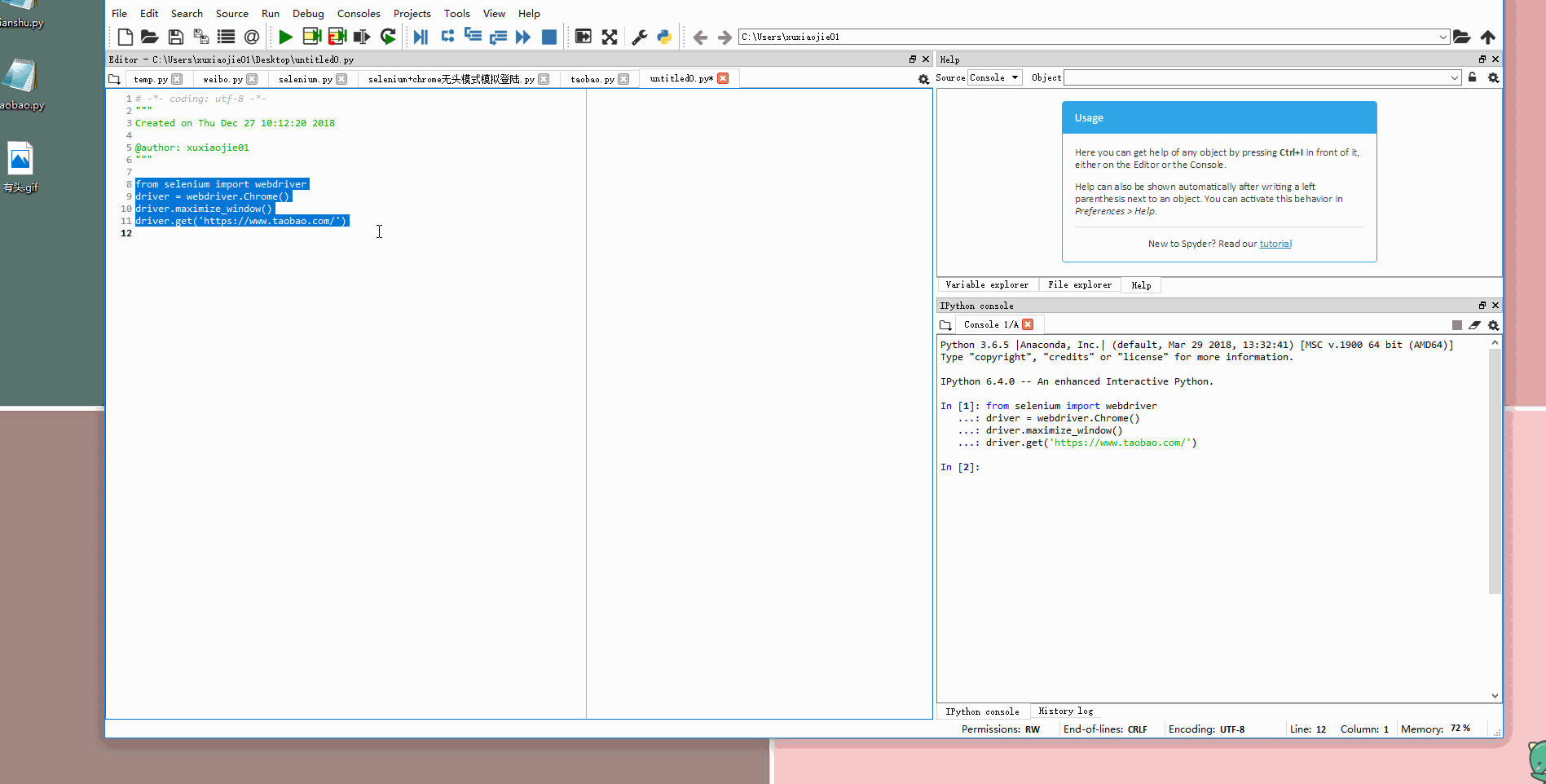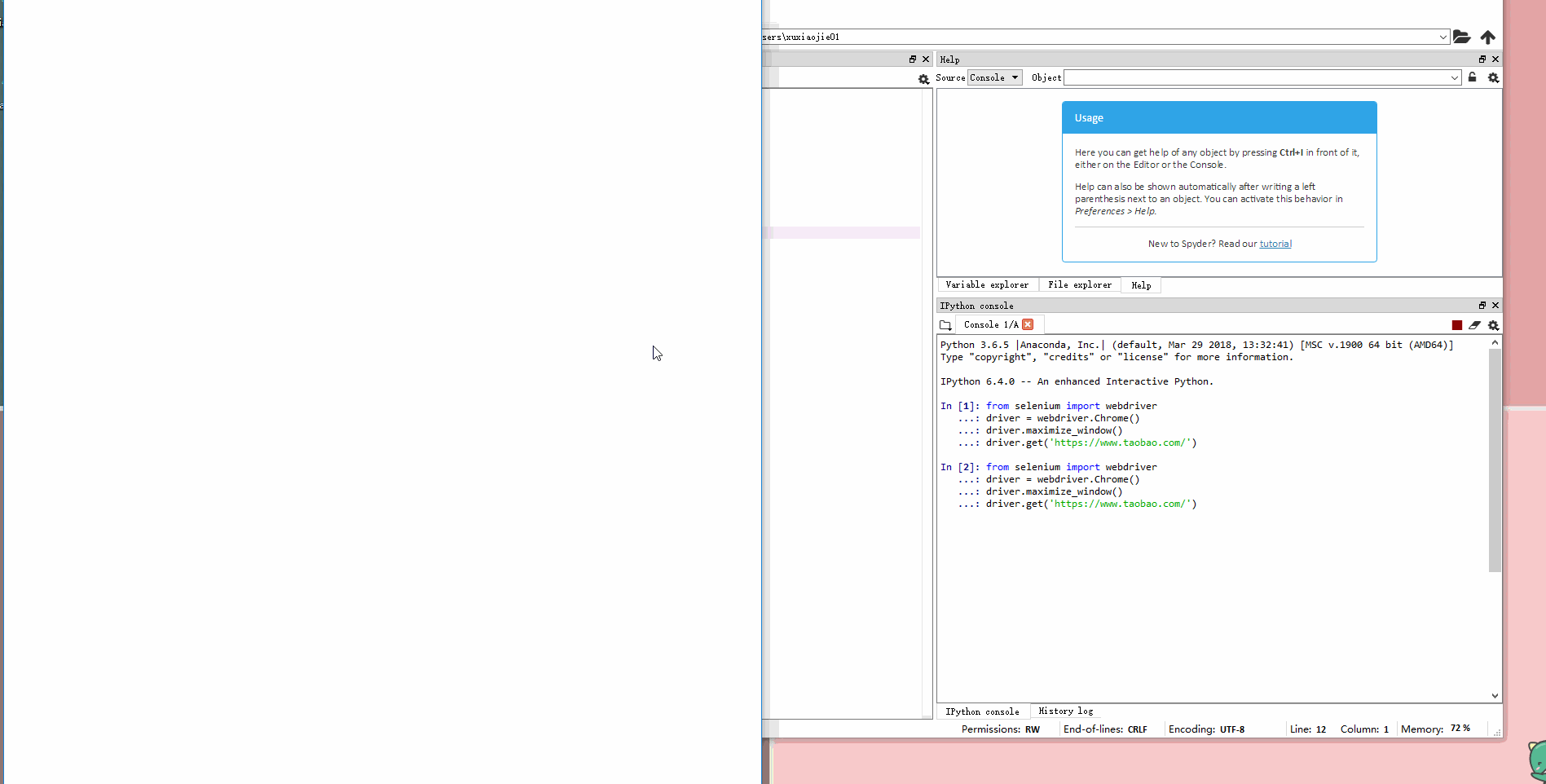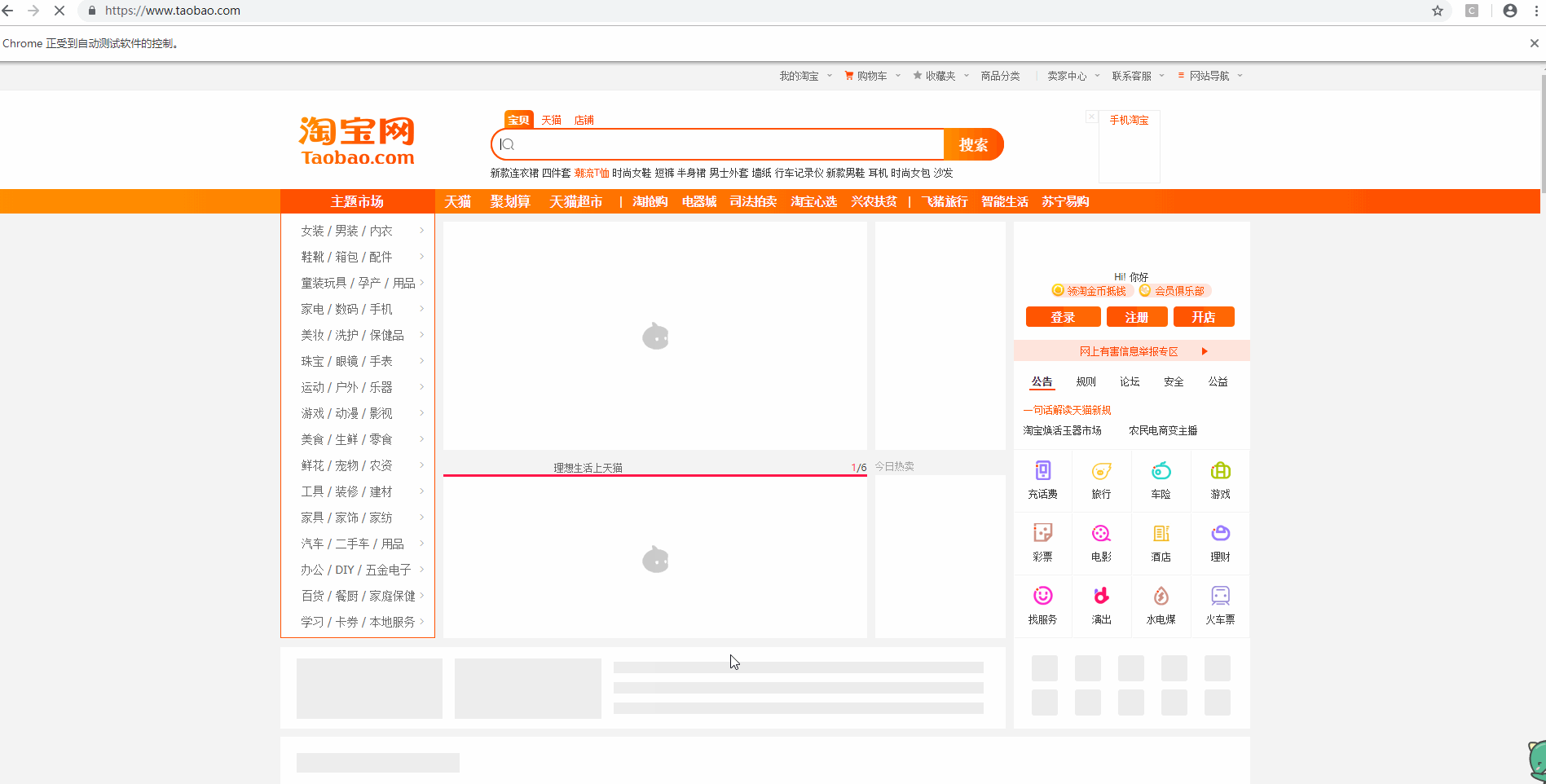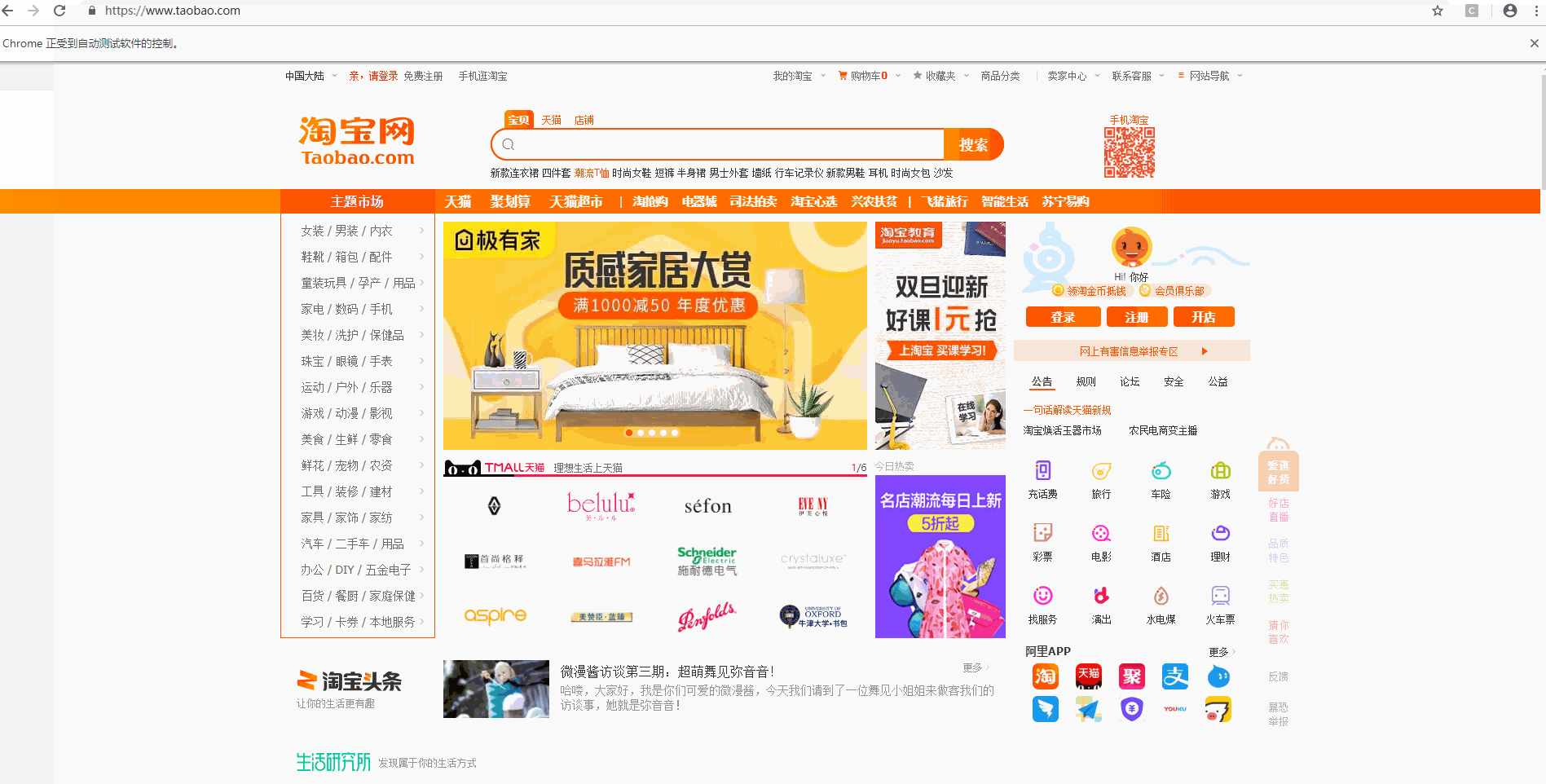
如下面所示,有头模式会自动打开网页,且窗口实现了最大化(避免小窗口遮挡一些重要的按钮)
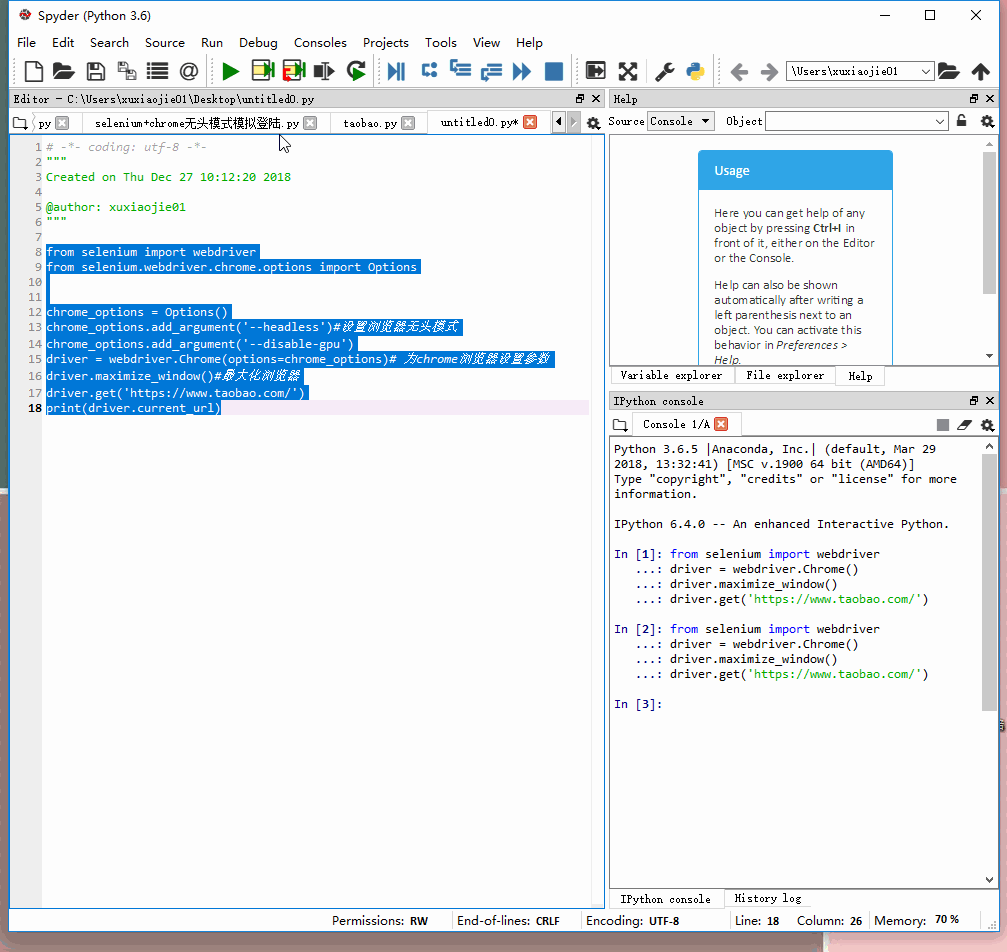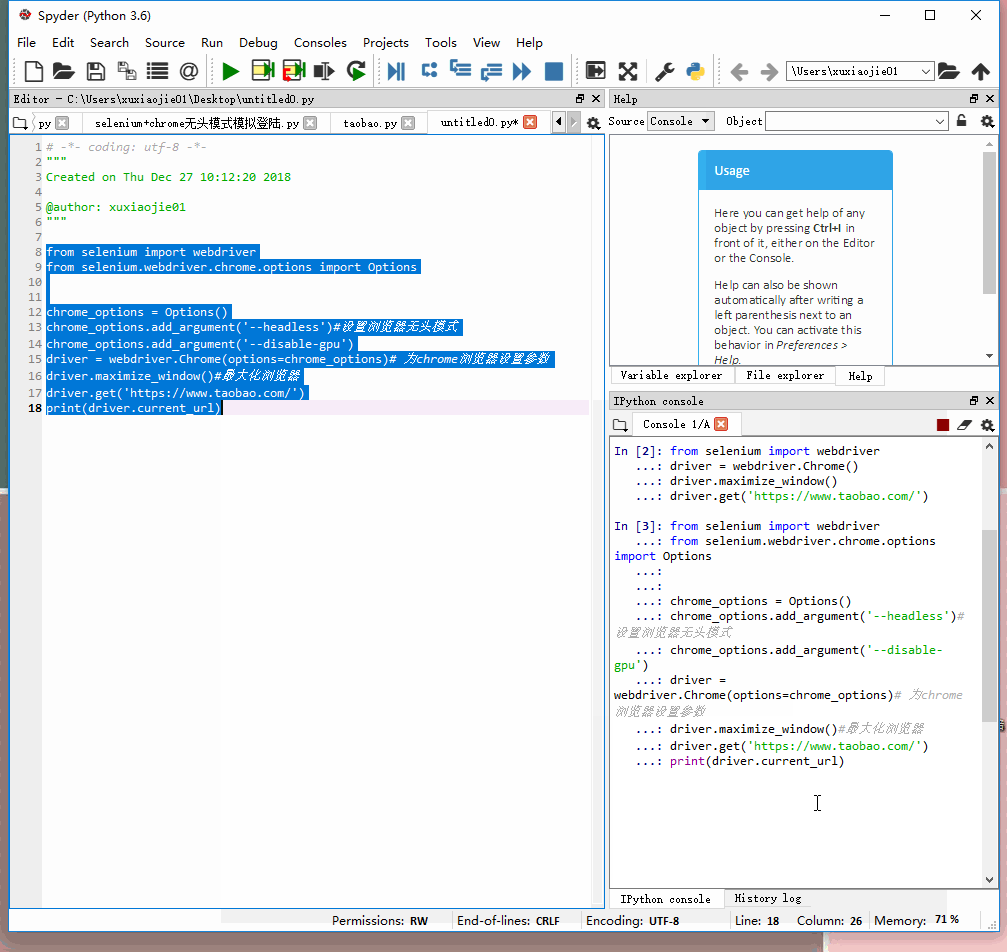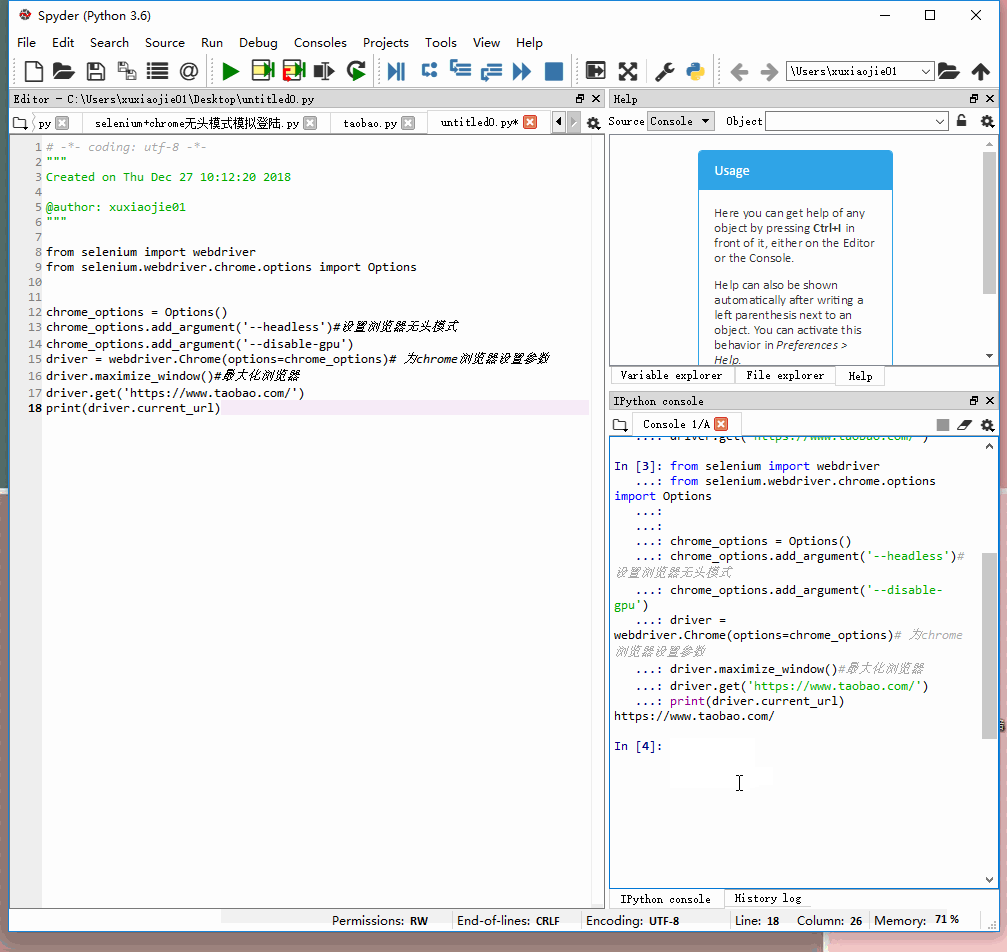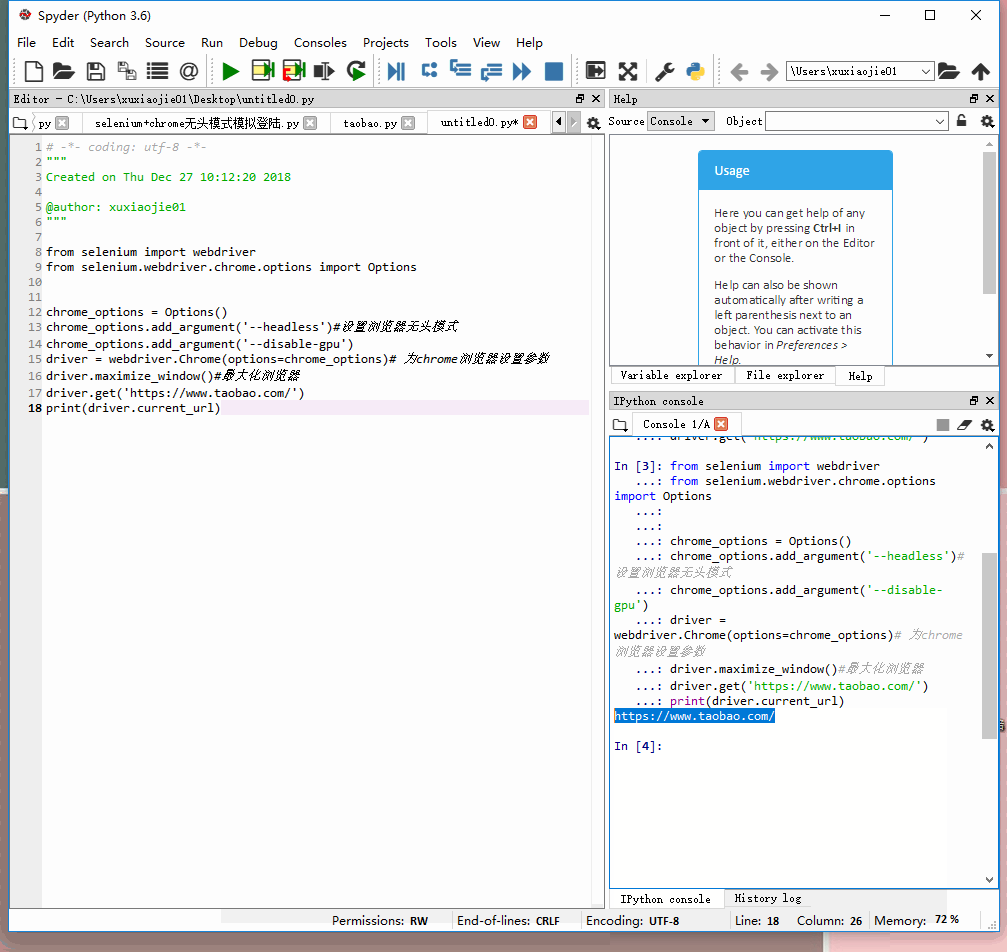
无头模式:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless') #设置浏览器无头模式
chrome_options.add_argument('--disable-gpu') #避免一些报错
driver = webdriver.Chrome(options=chrome_options) #为chrome浏览器设置参数
driver.maximize_window() #最大化浏览器
driver.get('https://www.taobao.com')
print(driver.current_url) #打印下当前页看还不是默默的打开了
如下面所示,无头模式不会自动打开网页(默默的)
爬网页信息需要登录怎么办?
现在爬淘宝网页需要登录才能浏览商品信息,使用selenium也是这样
from selenium import webdriver #调用selenium的webdriver
driver = webdriver.Chrome()
driver.maximize_window()
driver.get('https://www.taobao.com/') #请求淘宝网
driver.find_element_by_xpath('//*[@id="q"]').clear() #将搜索输入框里的内容清空
driver.find_element_by_xpath('//*[@id="q"]'). 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1972
1972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









