



一、LRU
LRU是最近使用,和访问频率没关系,只要是最近使用过,就放在队列后面,满了就把前面的删掉。
实现原理
ReferenceEntry<K, V> accessQueue;
当我们get(Key) 去访问缓存时,accessQueue删除对应的Key,
在把Key追加到accessQueue的尾部。所以经常访问都一直排在后面。
如果满了,就把头部的第一个删了。
二、FIFO
FIFO算法原理:FIFO算法类似于队列,新数据插入到队列尾部,当缓存空间不足时,淘汰队列头部的数据。注意这个和LRU不同的点在于,放问存在的元素,不会改变他在队列的位置,LRU是访问存在的元素会移动到队尾。
基本操作:
"插入":新数据项被添加到队列尾部。
"访问":访问缓存中的数据项不会改变它在队列中的位置。
"淘汰":当缓存已满时,淘汰队列头部的数据项。
三、LFU
LFU是按访问频率最低的删除,所有数据在cache集合,还要有一个Map记录每个Key的访问次数。就比如下面的结构。
// 简化版的LFU思想
Map<Key, Value> cache;
Map<Key, Integer> accessCount; // 记录每个key的访问次数
四、SLRU
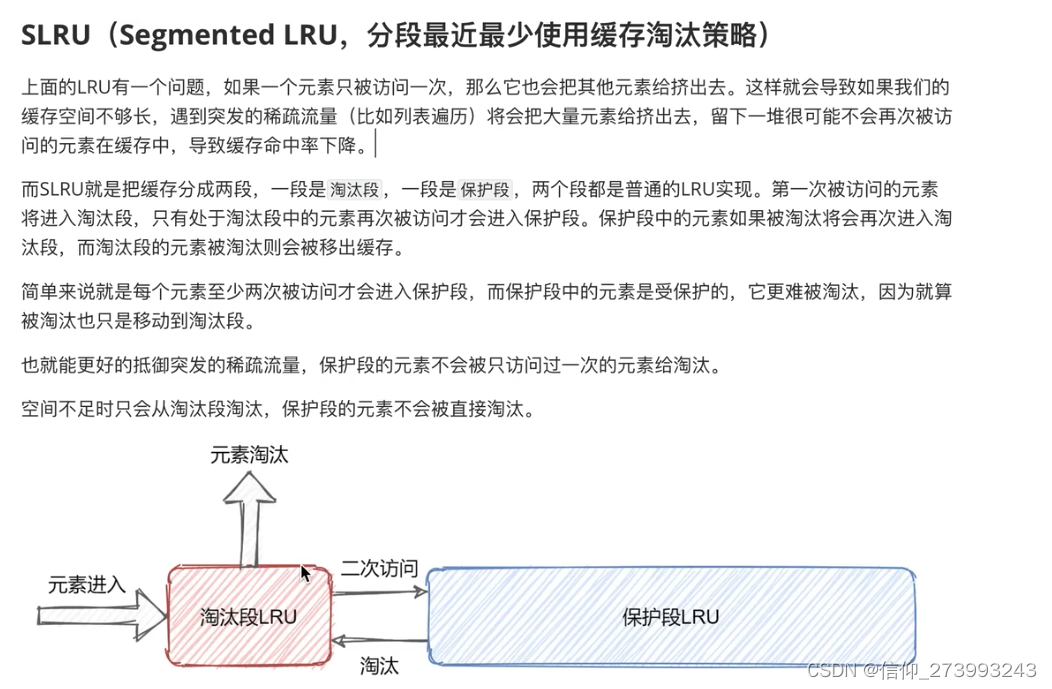
可以这么理解:先进入淘汰段,淘汰段也是一个LRU算法,当淘汰段满了,移除最早进来的,如果有重复的就会进入保护段,当保护段满了,进了新的元素,会吧数据挤到淘汰段里面去。
五、近似计数器
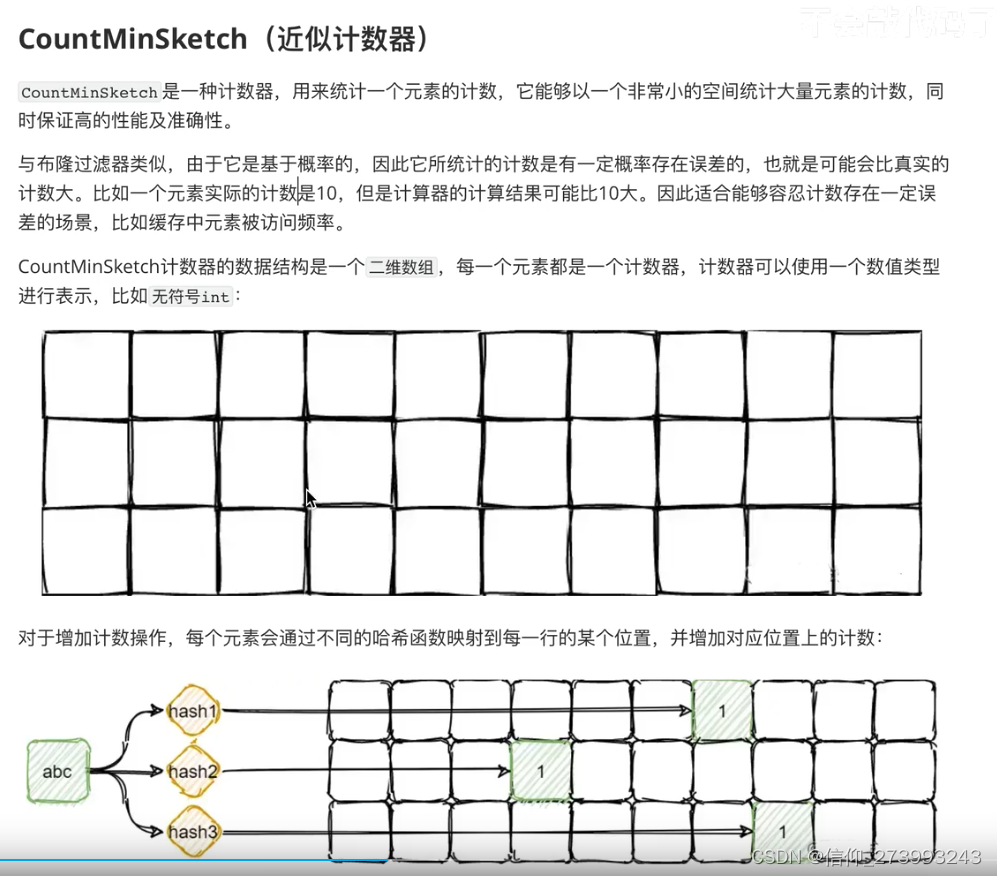
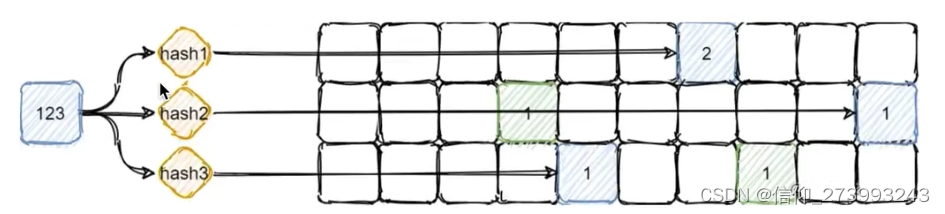
对一个数进行多次Hash运行,得到对应的下标位置,然后将下标位置加1,当统计某个key的出现次数时,只需要找到他所有的下标位置所对应的数,取出最小的那一个。

三、window-Tiny-LFU (W-T-LFU)

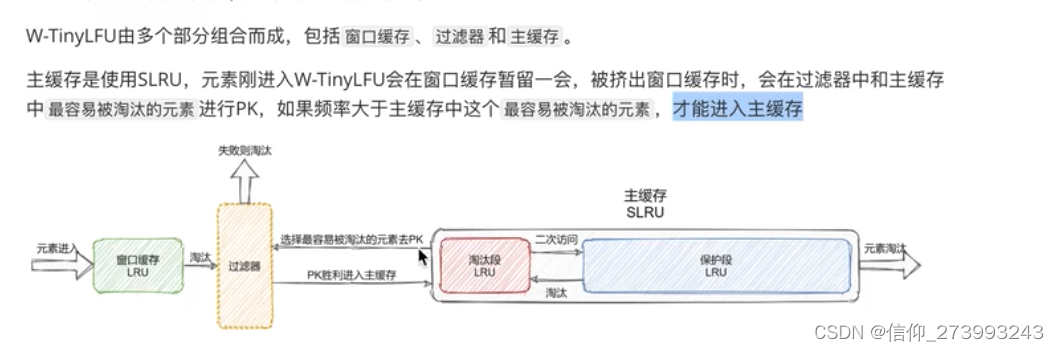
元素先进入窗口缓存,窗口缓存数据比较少,使用LRU,被挤出的元素,和淘汰段LRU的元素比对,怎么比对,从LRU最容易淘汰的元素比较,然后找到这个元素在布隆过滤最少的数值,对比。如果输了,就淘汰,赢了,就进入淘汰段。




















 784
784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











