






 该文介绍了如何使用Python的数据科学库,包括numpy、pandas、scipy和matplotlib,进行数据处理和可视化。文章详细展示了KMeans聚类算法的应用,对航空数据进行预处理、标准化,然后通过KMeans进行客户分群,并利用雷达图展示结果。
该文介绍了如何使用Python的数据科学库,包括numpy、pandas、scipy和matplotlib,进行数据处理和可视化。文章详细展示了KMeans聚类算法的应用,对航空数据进行预处理、标准化,然后通过KMeans进行客户分群,并利用雷达图展示结果。
一、安装依赖
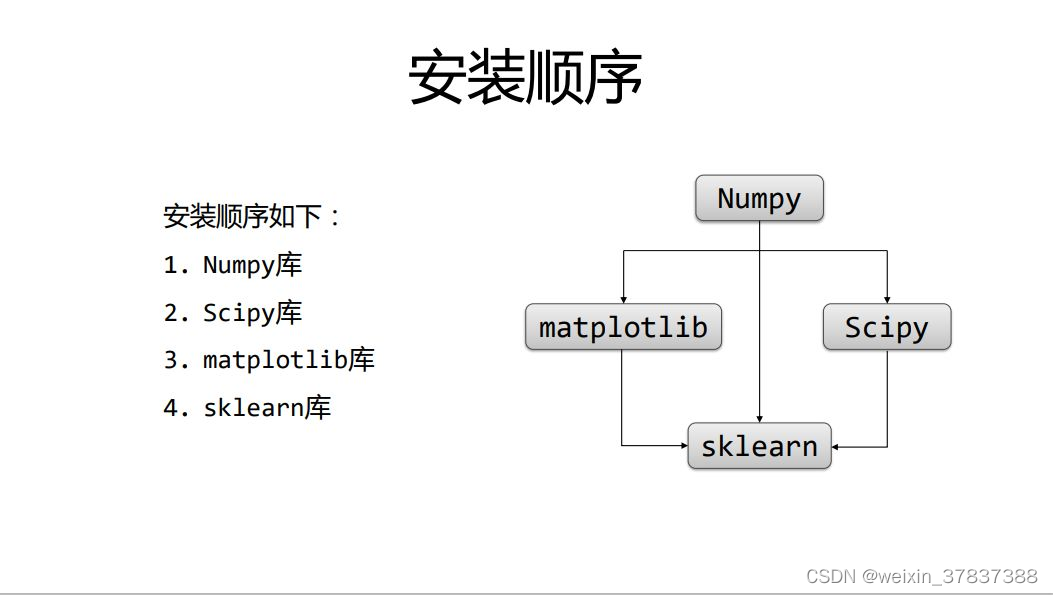
1.数值计算扩展
pip install numpy -U
2.核心数据分析支持库
pip install pandas
3.scipy Python 算法库和数学工具包 教程
pip install scipy -i https://pypi.tuna.tsinghua.edu.cn/simple
4.2D绘图库-主要用于二维绘图,它能让使用者很轻松地将数据图形化,并且提供多样化的输出格式。
pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
5.机器学习库
pip install scikit-learn
二、项目实现
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans#导入K-Means聚类分析模块
from sklearn.preprocessing import StandardScaler#
def plot(kmeans_model=None, columns=None):
'''
此函数用户绘制客户分群结果的雷达图
:param kmeans_model: 聚类的结果
:param columns: 各特征的明亨
:return: 客户分群的雷达图
'''
# 中文和负号的正常显示
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
plt.style.use('ggplot') # 使用ggplot的绘图风格
N = len(columns) # 特征数
angles = np.linspace(0, 2 * np.pi, N, endpoint=False) # 设置雷达图的角度,用于平分切开一个圆面
'''
绘图
'''
feature = columns # 特征名称
fig = plt.figure(figsize=(11, 11))
ax = fig.add_subplot(1,1,1, polar=True) # 这里一定要设置为极坐标格式
ax.set_thetagrids(angles * 180 / np.pi, feature) # 添加每个特征的标签
ax.set_ylim(kmeans_model.cluster_centers_.min(), kmeans_model.cluster_centers_.max()) # 设置雷达图的范围
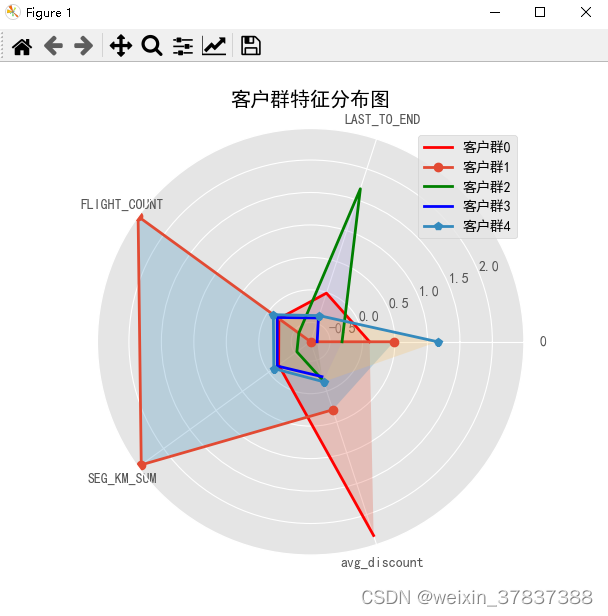
plt.title('客户群特征分布图') # 添加标题
ax.grid(True) # 添加网格线
sam = ['r-', 'o-', 'g-', 'b-', 'p-'] # 样式
lab = []
for i in range(len(kmeans_model.cluster_centers_)): # 依次绘制每个类中心的图像
values = kmeans_model.cluster_centers_[i] # 类中心取值
ax.plot(angles, values, sam[i], linewidth=2) # 绘制折线图
ax.fill(angles, values, alpha=0.25) # 填充颜色
lab.append('客户群' + str(i))
plt.legend(lab)
plt.show() # 显示图形
airline_data=pd.read_csv(r'D:\gitee\python\hangkonggskh\air_data.csv')
exp1=airline_data['SUM_YR_1'].notnull()#第一年为空
exp2=airline_data['SUM_YR_2'].notnull()#第二年为空
airline_notnull=airline_data[exp1&exp2]#取出票价收不为空的记录(62299)
index1=airline_notnull['SUM_YR_1']==0 #第一年的票价收入等于0
index2=airline_notnull['SUM_YR_2']==0
index3=airline_notnull['avg_discount']!=0 #平均折扣率不等于0
index4=airline_notnull['SEG_KM_SUM']>0#
airline=airline_notnull[-(index1 & index2 & index3 & index4)] #去除不符合逻辑的记录
L=pd.to_datetime(airline['LOAD_TIME'])-pd.to_datetime(airline['FFP_DATE'])
L=L.dt.days/30#入会时长(以月为单位)
airline_features=pd.concat((L,airline[['LAST_TO_END','FLIGHT_COUNT','SEG_KM_SUM','avg_discount']]),axis=1)
data=StandardScaler().fit_transform(airline_features)#数据标准化
KMeans(n_clusters=5).fit(data)
kmeans_model=KMeans(n_clusters=5).fit(data)#K-Means聚类分析
plot(kmeans_model=kmeans_model,columns=airline_features.columns)
kmeans_model.labels_ #每个样本的聚类标签
kmeans_model.cluster_centers_ #中心的坐标
airline_features['label']=kmeans_model.labels_#记录各样本的类别标签
airline_features.to_csv('airline_features.csv',index=None)#将数据以CSV文件形式写出
实现效果

















 534
534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









