







 在开发一个仿知乎的在线问答系统时,遇到`jinja2.exceptions.UndefinedError: 'None' has no attribute 'id'`的错误。问题出现在无评论数据的文章请求评论接口时。通过分析发现,接口需要问题ID来获取默认评论。尝试了前端判空处理和返回固定有评论的数据等方法无效。最终,通过查阅Jinja2模板笔记,设置模板变量默认值解决了问题,使系统访问恢复正常。
在开发一个仿知乎的在线问答系统时,遇到`jinja2.exceptions.UndefinedError: 'None' has no attribute 'id'`的错误。问题出现在无评论数据的文章请求评论接口时。通过分析发现,接口需要问题ID来获取默认评论。尝试了前端判空处理和返回固定有评论的数据等方法无效。最终,通过查阅Jinja2模板笔记,设置模板变量默认值解决了问题,使系统访问恢复正常。
前言:
最近在写一个仿知乎的,在线问答系统,用flask,在造数据,对接前端的时候,报了一个错,这个错很诡异……
jinja2.exceptions.UndefinedError: 'None' has no attribute 'id'
pycharm控制台:


找到所在的视图函数,进行debug :
得到answer的对象是None

在前端js的逻辑里面,加入了判空处理:
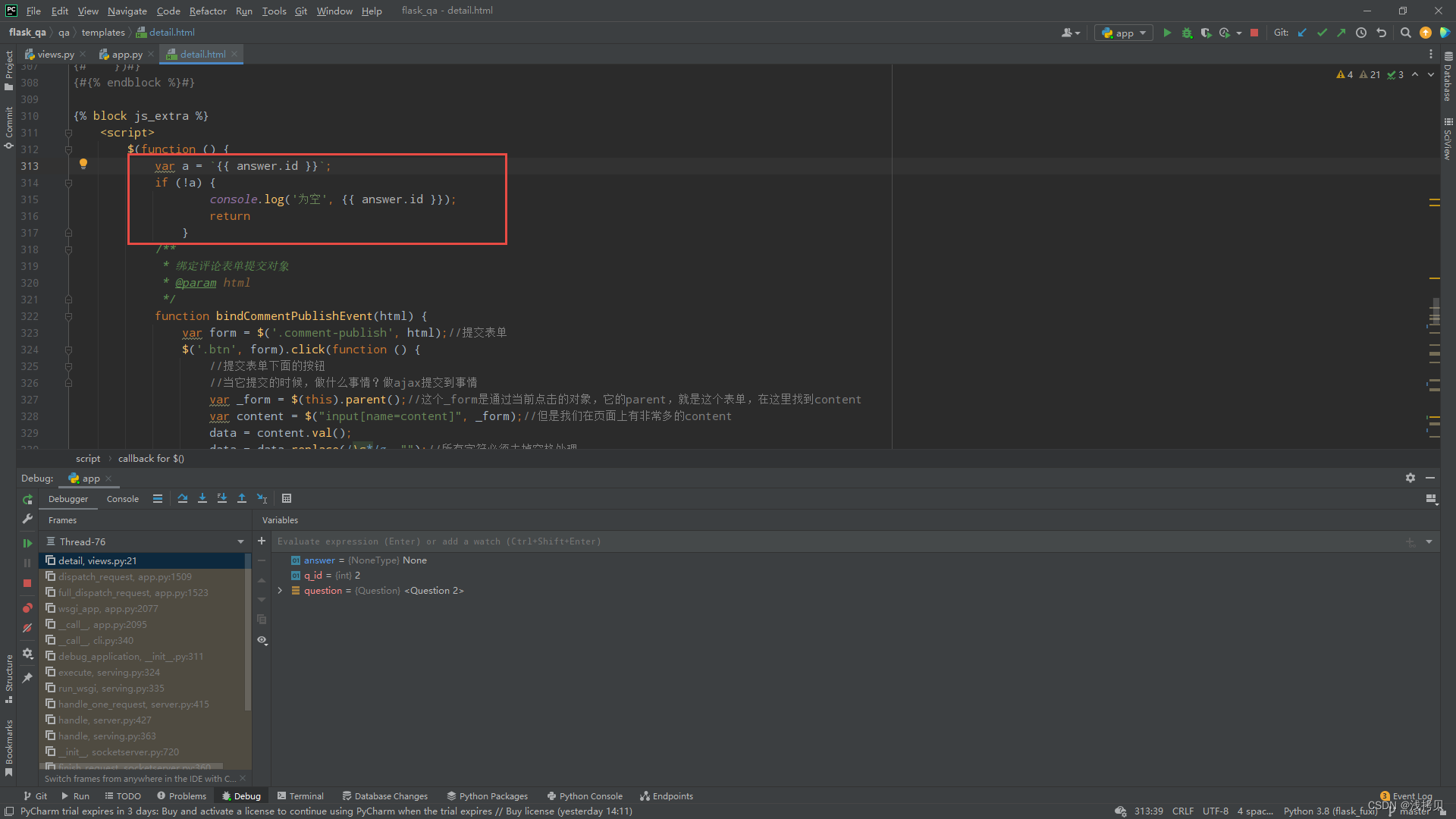
还是会报错……
分析:
1.创建一个有评论数据的文章,进入debug,是不会报错的
2.在进入没有评论数据的文章,会报错
百思不得其解 ……
报错的问题是:在请求评论数据的异步接口中,需要一个问题的id(根据问题的id,获取到该问题下的第一条评论内容,作为默认加载项)
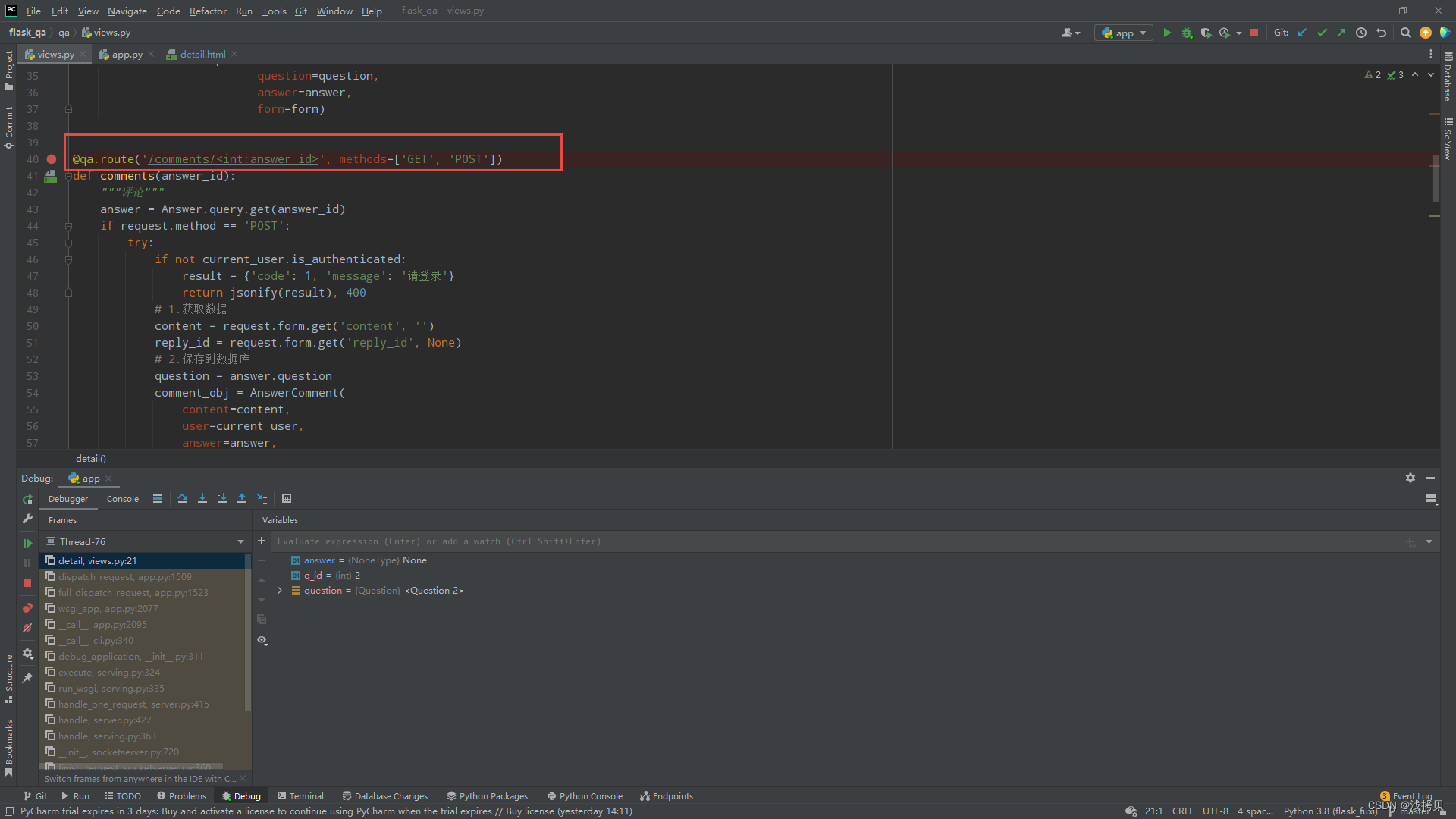
尝试过思路:
1.在返回数据的时候,默认返回有评论数据的文章(这个被否决,因为文章必须是有没有评论,都要返回前端显示)
2.在前端js加载的时候,判断是否为空,不为空则可以进行异步请求(尝试过,可还会报错)
最后,翻查了学过的jinjia2模板笔记中,有设置模板变量默认值的……
问题搞定
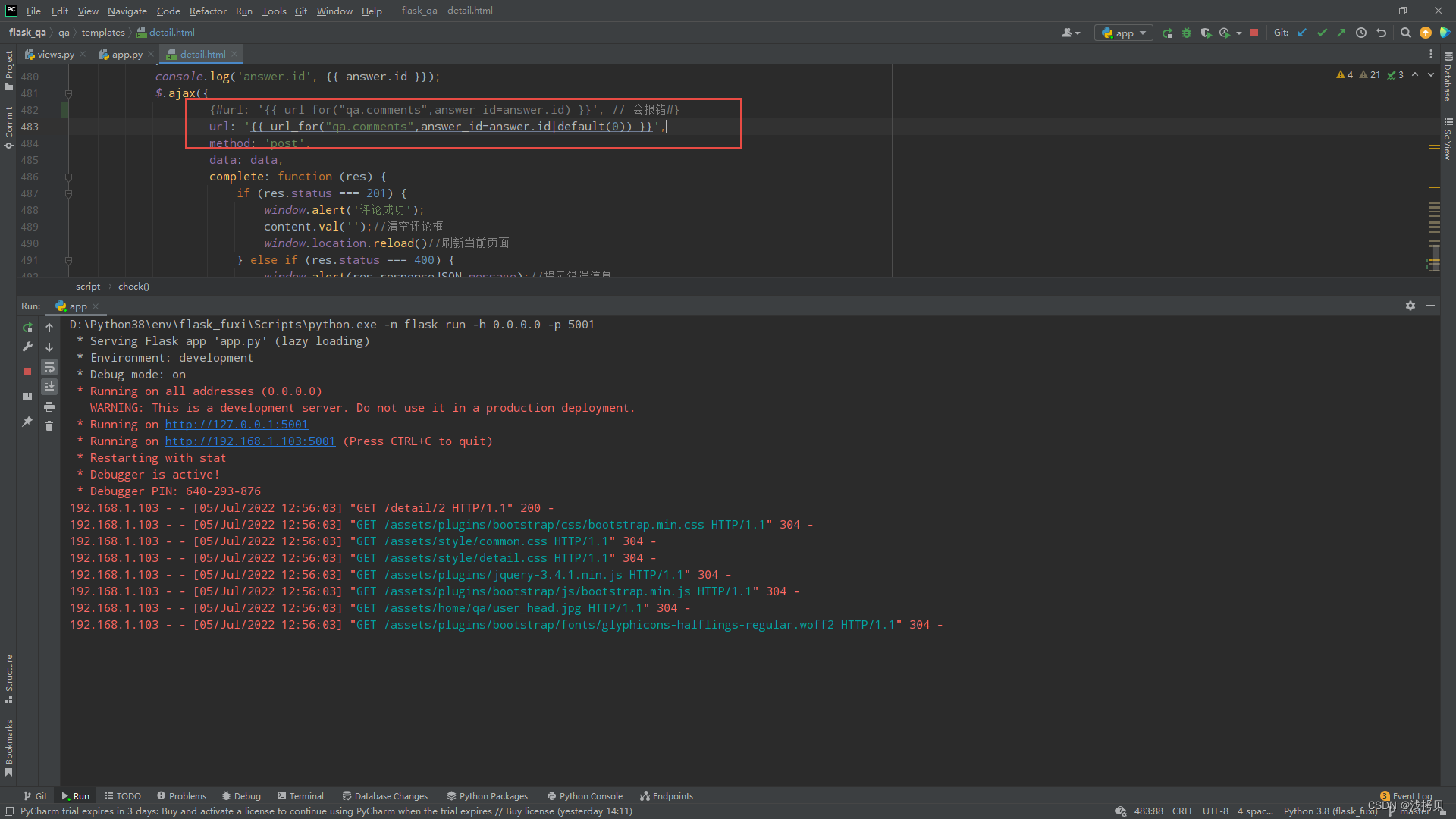
访问正常:

















 30万+
30万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









