




 本文详细解析了语音数据预处理的全过程,包括wav文件的查找、排序与基本信息提取,如说话人ID、句子编号等。同时,介绍了如何利用脚本进行语音文件与文本的匹配,生成用于语音识别训练的必要文件。
本文详细解析了语音数据预处理的全过程,包括wav文件的查找、排序与基本信息提取,如说话人ID、句子编号等。同时,介绍了如何利用脚本进行语音文件与文本的匹配,生成用于语音识别训练的必要文件。
万丈高山,从平路走起。
local/thchs-30_data_prep.sh
创建 train,dev,test三个文件夹用来存储数据
mkdir -p data/{train,dev,test}
根据原始数据,生成标题中的文本,涉及到的一些指令总结下,主要是下面这句话中的:
for nn in `find $corpus_dir/$x -name "*.wav" | sort -u | xargs -I {} basename {} .wav`; do
- 第一步是找到原始数据中的所有wav文件,并输出绝对路径
- 第二步是根据上一步得到的路径来进行排序,-u指的是去掉重复行
- 第三步是输出文件的basename(去掉wav), -I 表示逐行操作。
所以上述代码出来的是所有的wav文件的文件名。
spkid=`echo $nn | awk -F"_" '{print "" $1}'`
对于类似于 A11_0 这样的文件,以 “_” 区分开,会分成两个部分, A11和0,spkid读取A11,也就是说话人的id。
spk_char=`echo $spkid | sed 's/\([A-Z]\).*/\1/'`
spk_num=`echo $spkid | sed 's/[A-Z]\([0-9]\)/\1/'`
utt_num=`echo $nn | awk -F"_" '{print $2}'`
这段代码,是分别在spkid中读取A-Z的字母片段和0-9的数字片段,对于A11, spk_char=“A”, spk_num=“11”,最后一行读取的是某个说话人说的第几句话的索引。
echo $uttid $corpus_dir/$x/$nn.wav >> wav.scp
echo $uttid $spkid >> utt2spk
echo $uttid `sed -n 1p $corpus_dir/data/$nn.wav.trn` >> word.txt
echo $uttid `sed -n 3p $corpus_dir/data/$nn.wav.trn` >> phone.txt
以上几句是将读取的文件名 文件的绝对路径写到wav.scp,每句话对应的说话人写到 utt2spk,对应的word和phone写到对应的文本中。语料库中的关于语音文本的内容如下截图:

cp word.txt text
sort wav.scp -o wav.scp
sort utt2spk -o utt2spk
sort text -o text
sort phone.txt -o phone.txt
这几句代码的意思是将所有之前存起来的文本文件都排个序,还输出到原来的文件中去。顺便还给word.txt做了个备份。
所以对于生成后续程序需要的这些文本基本上搞定了,还差最后一个,对应某个说话人的所有语句还没有搞定。对于这个任务,搞定的代码如下:
utils/utt2spk_to_spk2utt.pl data/train/utt2spk > data/train/spk2utt
utils/utt2spk_to_spk2utt.pl data/dev/utt2spk > data/dev/spk2utt
utils/utt2spk_to_spk2utt.pl data/test/utt2spk > data/test/spk2utt
这里面调用了utils中的一个perl脚本写的文件。就是根据之前生成的utt2spk,来得到spk2utt。对应的utt2spk_to_spk2utt.pl 内容如下:
if ( @ARGV > 1 ) {
die "Usage: utt2spk_to_spk2utt.pl [ utt2spk ] > spk2utt";
}
#外部传参的数量不能大于1,得按照它给的格式来写
while(<>){
@A = split(" ", $_);
@A == 2 || die "Invalid line in utt2spk file: $_";
($u,$s) = @A;
if(!$seen_spk{$s}) {
$seen_spk{$s} = 1;
push @spklist, $s;
}
push (@{$spk_hash{$s}}, "$u");
}
foreach $s (@spklist) {
$l = join(' ',@{$spk_hash{$s}});
print "$s $l\n";
}
看了半天没看懂,大概是那么个意思,其实用python来写也不难。我用python写了一个。虽然没有用过perl,存在即是道理,时间上也够去了解这么多。
python代码如下:
import os
import sys
op = sys.argv[1]
tp = sys.argv[2]
cons = open(op).readlines()
kv = {}
for c in cons:
k, v = c.split()
if v not in kv:
kv[v] = [k]
else:
kv[v].append(k)
with open(tp, 'w') as f:
for k in kv:
f.write(k)
for v in kv[k]:
f.write(' '+ v)
f.write('\n')
最后生成一堆文本的shell脚本还有几行代码:
echo "creating test_phone for phone decoding"
(
rm -rf data/test_phone && cp -R data/test data/test_phone || exit 1
cd data/test_phone && rm text && cp phone.txt text || exit 1
)
这段代码就是说将之前生成的text文件夹里面的东西都拷贝到test_phone里面。如下所示:
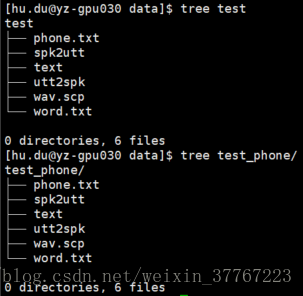
以上就是run.sh里面这一行代码所起的作用。
local/thchs-30_data_prep.sh $H $thchs/data_thchs30 || exit 1;
这段结束……再见~

















 846
846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









