




 本文详细描述了如何使用YOLOv8在Ubuntu18.04系统上进行服务器训练,包括从LabelMe标注工具导出数据、转换为YOLO格式,以及如何划分训练集和验证集。最后介绍了在AutoDL平台上配置模型、下载权重和进行实时物体检测的过程。
本文详细描述了如何使用YOLOv8在Ubuntu18.04系统上进行服务器训练,包括从LabelMe标注工具导出数据、转换为YOLO格式,以及如何划分训练集和验证集。最后介绍了在AutoDL平台上配置模型、下载权重和进行实时物体检测的过程。
YOLO v8 服务器 训练过程记录 外置摄像头实时检测
目标:训练自己的数据集
炼丹炉: Auto DL
本地电脑: Ubuntu 18.04 系统
任务: 检测 + 分割
第一步:建立yolov8 数据库
标注工具:
格式转换工具:
(1)json 2 txt 代码
(2)数据分割 代码
import json
import os
import shutil
import random
# Convert label to idx
with open("labels.txt", "r") as f:
classes = [c.strip() for c in f.readlines()]
idx_dict = {c: str(i) for i, c in enumerate(classes)}
def convert_labelmes_to_yolo(labelme_folder, output_folder):
label_folder = os.path.join(output_folder, "labels")
os.makedirs(label_folder, exist_ok=True)
image_folder = os.path.join(output_folder, "images")
os.makedirs(image_folder, exist_ok=True)
for root, dirs, files in os.walk(labelme_folder):
for file in files:
file_path = os.path.join(root, file)
if os.path.splitext(file)[-1] != ".json":
shutil.copy(file_path, image_folder)
print(f"Copied {file_path} to {image_folder}")
else:
with open(file_path, 'r') as f:
labelme_data = json.load(f)
image_filename = labelme_data["imagePath"]
image_filename = image_filename[16:]
# 这里因为 json文件中的imagePath路径不对,json中imagepath的路径应该是"imagePath": "DOWN0906_000.jpg" 才对。
# 但是,我在标注的时候将json文件和原图像文件分开放了。labelme在标注的时候就会寻找图片下相应路径写入json文件,路径如下:
# "imagePath": "../picture_0906/DOWN0906_000.jpg"。
# 上面使用切片操作,去掉前面的16个字符,就可以正常运行了。
image_width = labelme_data["imageWidth"]
image_height = labelme_data["imageHeight"]
txt_filename = os.path.splitext(image_filename)[0] + ".txt"
txt_path = os.path.join(label_folder, txt_filename)
with open(txt_path, 'w') as f:
for shape in labelme_data["shapes"]:
label = shape["label"]
points = shape["points"]
class_idx = idx_dict.get(label)
if class_idx is not None:
f.write(class_idx)
for point in points:
x = point[0] / image_width
y = point[1] / image_height
f.write(f" {x} {y}")
f.write("\n")
print(f"Converted {file} to {txt_path}")
print("转换成功")
def split_data(output_folder, dataset_folder):
random.seed(0)
split_rate = 0.2 #验证集占比
origin_label_path = os.path.join(output_folder, "labels")
origin_image_path = os.path.join(output_folder, "images")
train_label_path = os.path.join(dataset_folder, "train", "labels")
os.makedirs(train_label_path, exist_ok=True)
train_image_path = os.path.join(dataset_folder, "train", "images")
os.makedirs(train_image_path, exist_ok=True)
val_label_path = os.path.join(dataset_folder, "val", "labels")
os.makedirs(val_label_path, exist_ok=True)
val_image_path = os.path.join(dataset_folder, "val", "images")
os.makedirs(val_image_path, exist_ok=True)
images = os.listdir(origin_image_path)
num = len(images)
eval_index = random.sample(images,k=int(num*split_rate))
for single_image in images:
origin_single_image_path = os.path.join(origin_image_path, single_image)
single_txt = os.path.splitext(single_image)[0] + ".txt"
origin_single_txt_path = os.path.join(origin_label_path, single_txt)
if single_image in eval_index:
#single_json_path = os.path.join(val_label_path,single_json)
shutil.copy(origin_single_image_path, val_image_path)
shutil.copy(origin_single_txt_path, val_label_path)
else:
#single_json_path = os.path.join(train_label_path,single_json)
shutil.copy(origin_single_image_path, train_image_path)
shutil.copy(origin_single_txt_path, train_label_path)
print("数据集划分完成")
with open(os.path.join(dataset_folder,"data.yaml"),"w") as f:
f.write(f"train: {dataset_folder}\n")
f.write(f"val: {val_image_path}\n")
f.write(f"test: {val_image_path}\n\n")
f.write(f"nc: {len(classes)}\n")
f.write(f"names: {classes}\n")
labelme_folder = "labelme_folder" #labelme生成的标注文件所在的文件夹
output_folder = "output_dir" #存储yolo标注文件的文件夹
dataset_folder = "dataset" #存储划分好的数据集的文件夹
convert_labelmes_to_yolo(labelme_folder, output_folder)#将labelme标注文件转换为yolo格式
split_data(output_folder, dataset_folder)#划分训练集和验证级
分割文件最终结果:

第三步:在线服务器配置
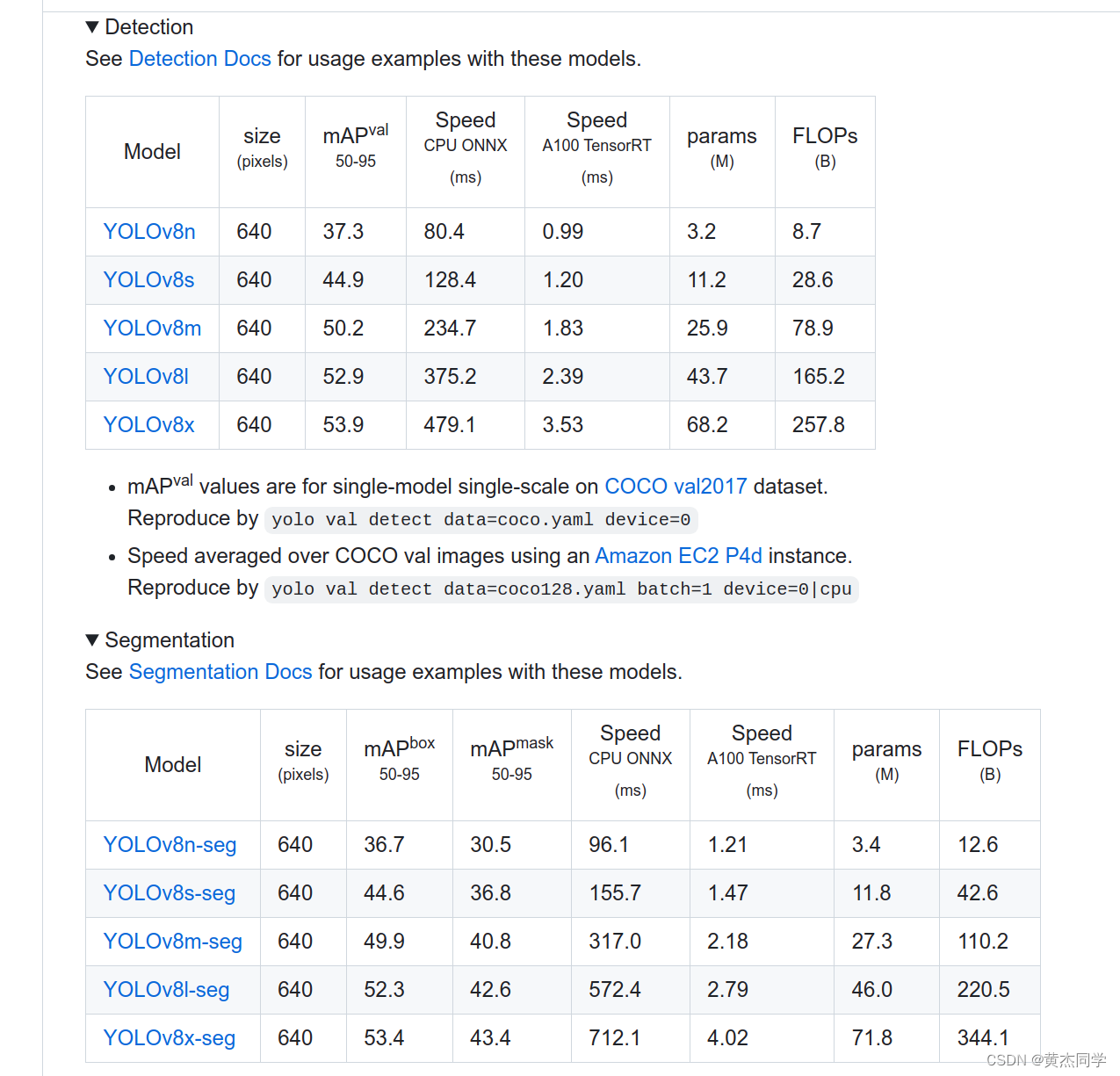
(1)下载源代码 以及 相关权重文件
git clone https://github.com/ultralytics/ultralytics.git
https://github.com/ultralytics/ultralytics 权重文件全这里里面,根据自己的需求下载
(2)压缩数据 和 源代码及权重文件
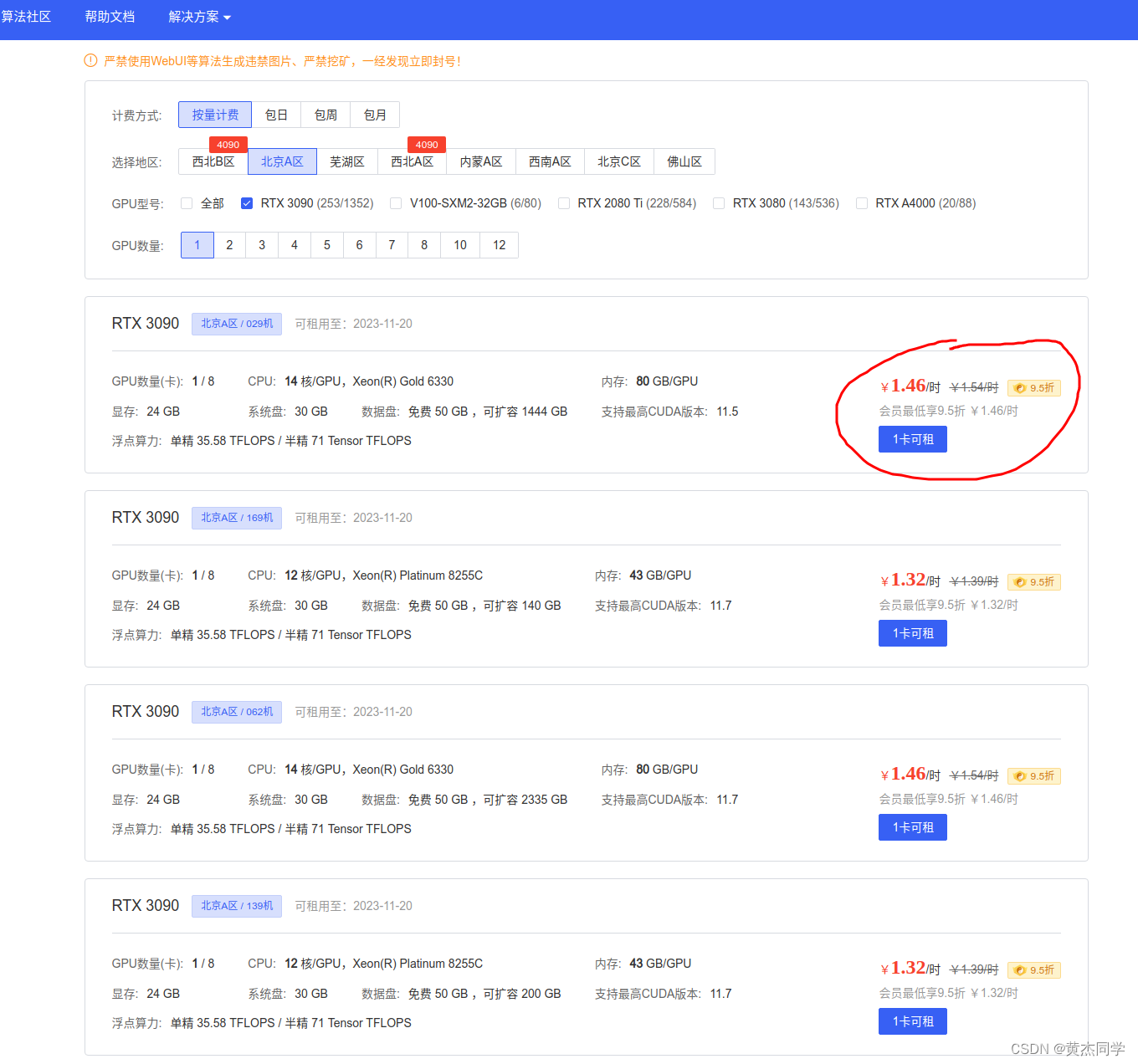
(3)购买算力 以及 配置cuda 和 pytorch 环境
Auto DL 地址
https://www.autodl.com/market/list
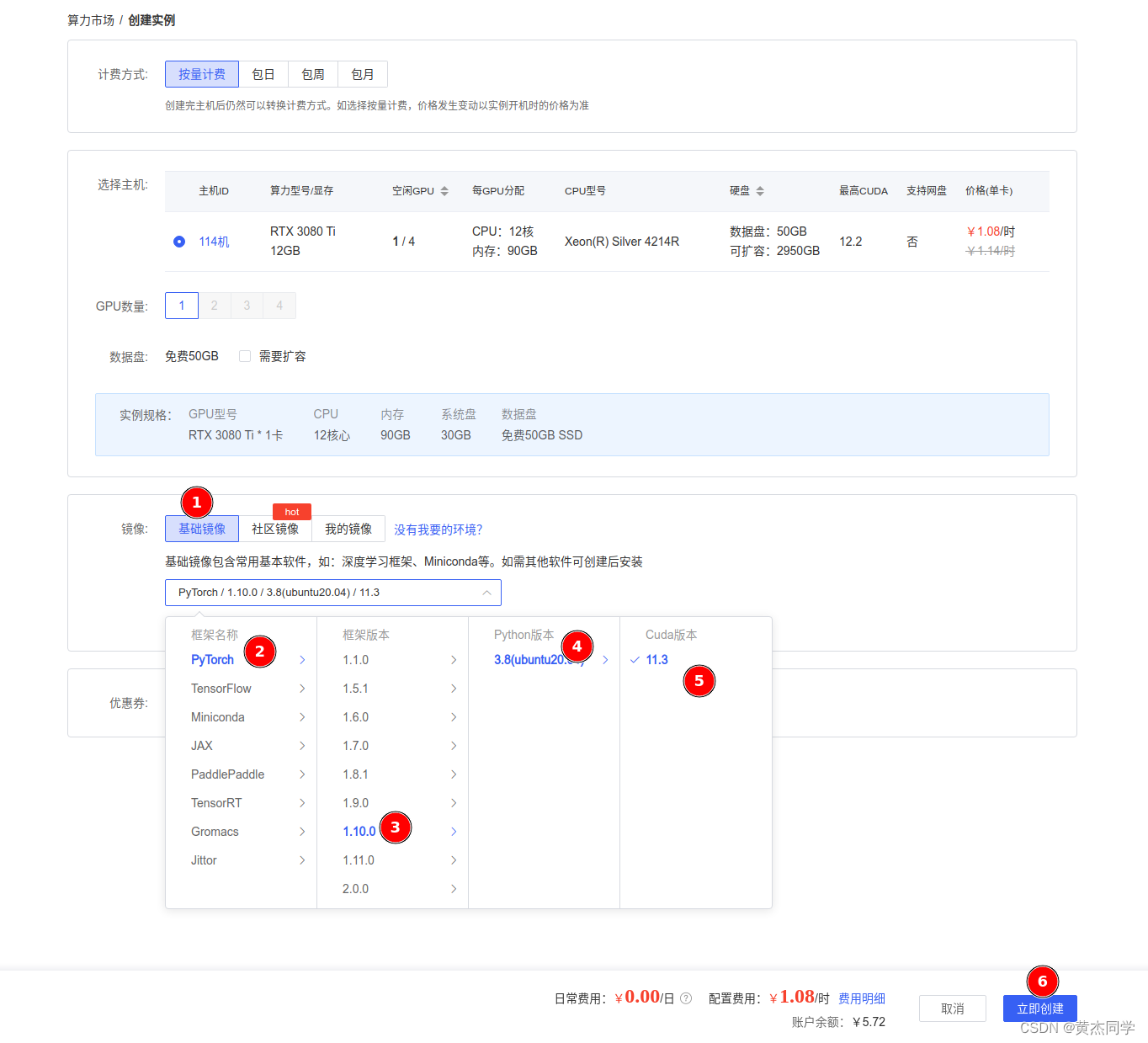
基础环境配置
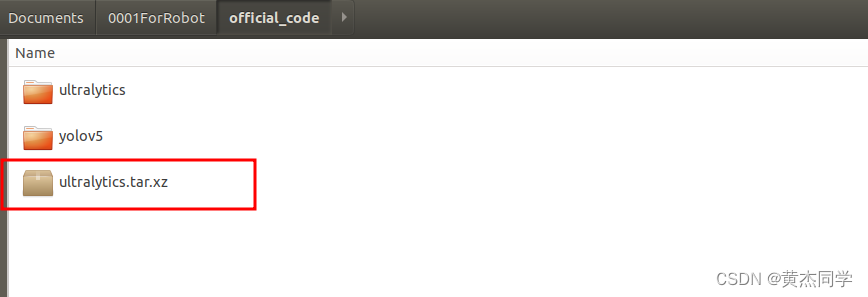
(3) 上传数据和源文件
- 上传 源代码文件
- 上传数据

- dataset 文件格式
dataset
├─train
│ ├─images
│ │ ├─ 111.jpg
│ │ ├─ 112.jpg
│ │
│ └─labels
│ ├─ 111.txt
│ └─112.txt
│
└─val
├─images
│ ├─ 012.jpg
│ ├─ 013.jpg
│
└─labels
├─ 012.txt
└─013.txt
- 上传 权重参数 (到对应的github网页上也下载自己需要的权重文件,再上传到ultralytics文件夹下就可以)
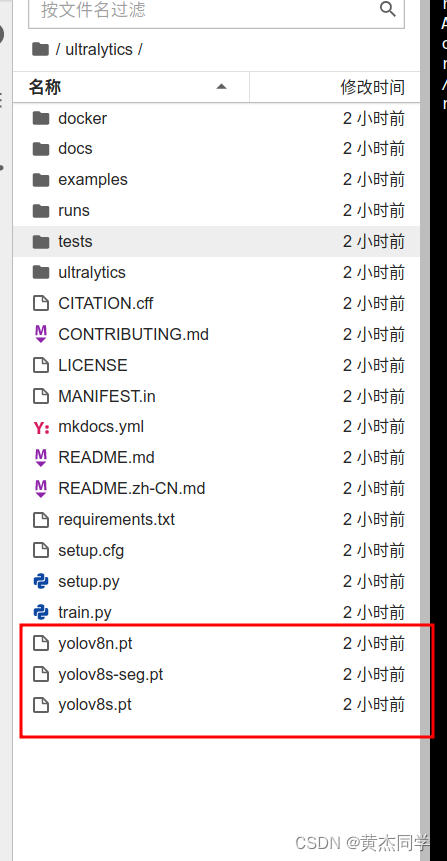
(4)解压文件
tar -xvf xxxx.tar,xz
(5)注意:数据和源文件位置
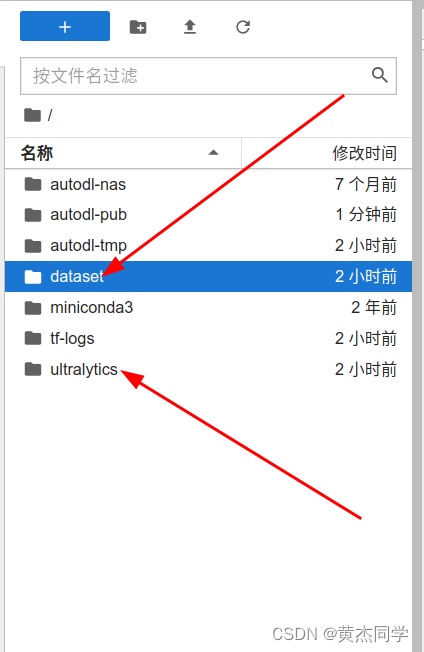
第三步:配置文件设置
(1)数据配置文件设置:
- mydata-seg.yaml设置
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../dataset # dataset root dir
train: train/images # train images (relative to 'path') 128 images
val: val/images # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
names:
0: data1
1: data2
(2)存放位置
/root/ultralytics/ultralytics/cfg/datasets
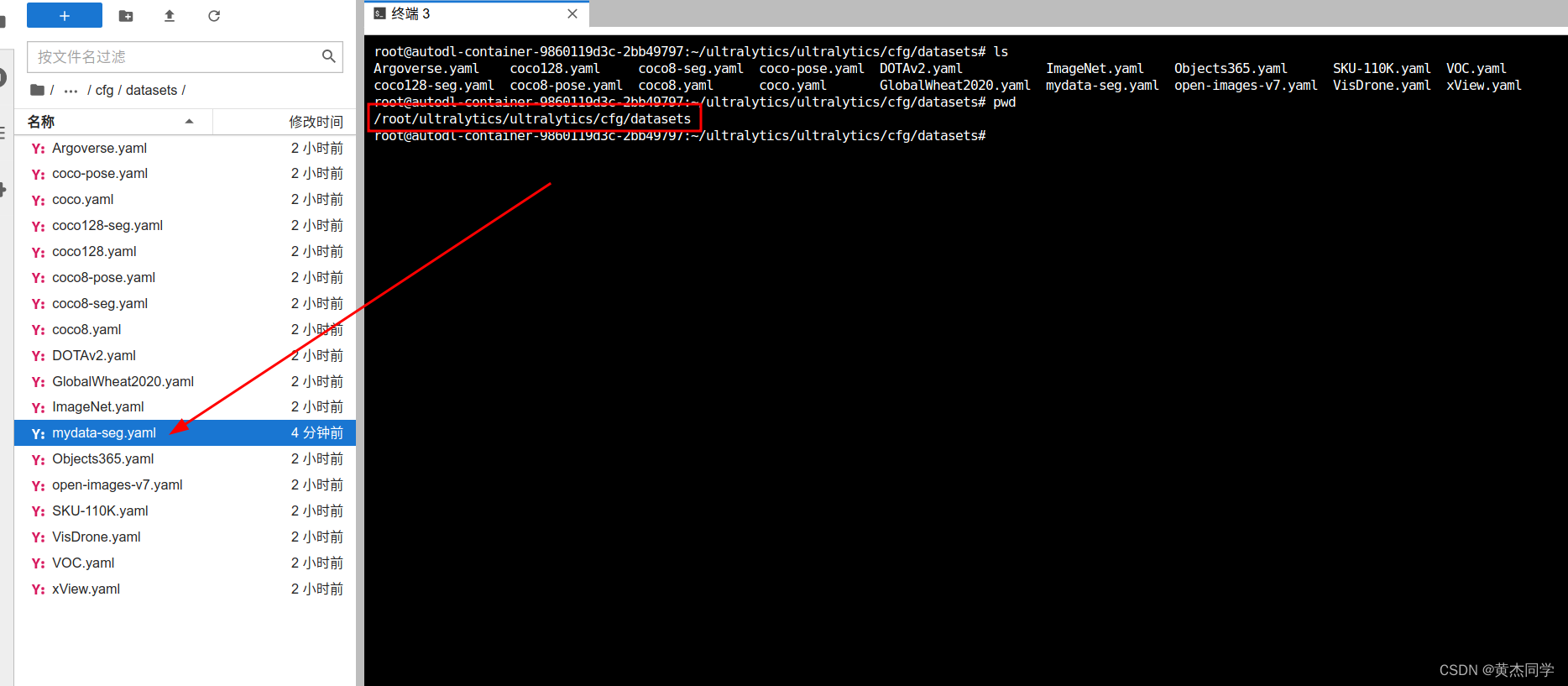
(2)训练文件设置:
- train.py
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8s-seg.yaml') # build a new model from YAML
model = YOLO('yolov8s-seg.pt') # load a pretrained model (recommended for training)
model = YOLO('yolov8s-seg.yaml').load('yolov8s.pt') # build from YAML and transfer weights
# Train the model
results = model.train(data='mydata-seg.yaml', epochs=300, imgsz=640)
(4)训练文件存放位置(放在ultratics文件夹下就可以)
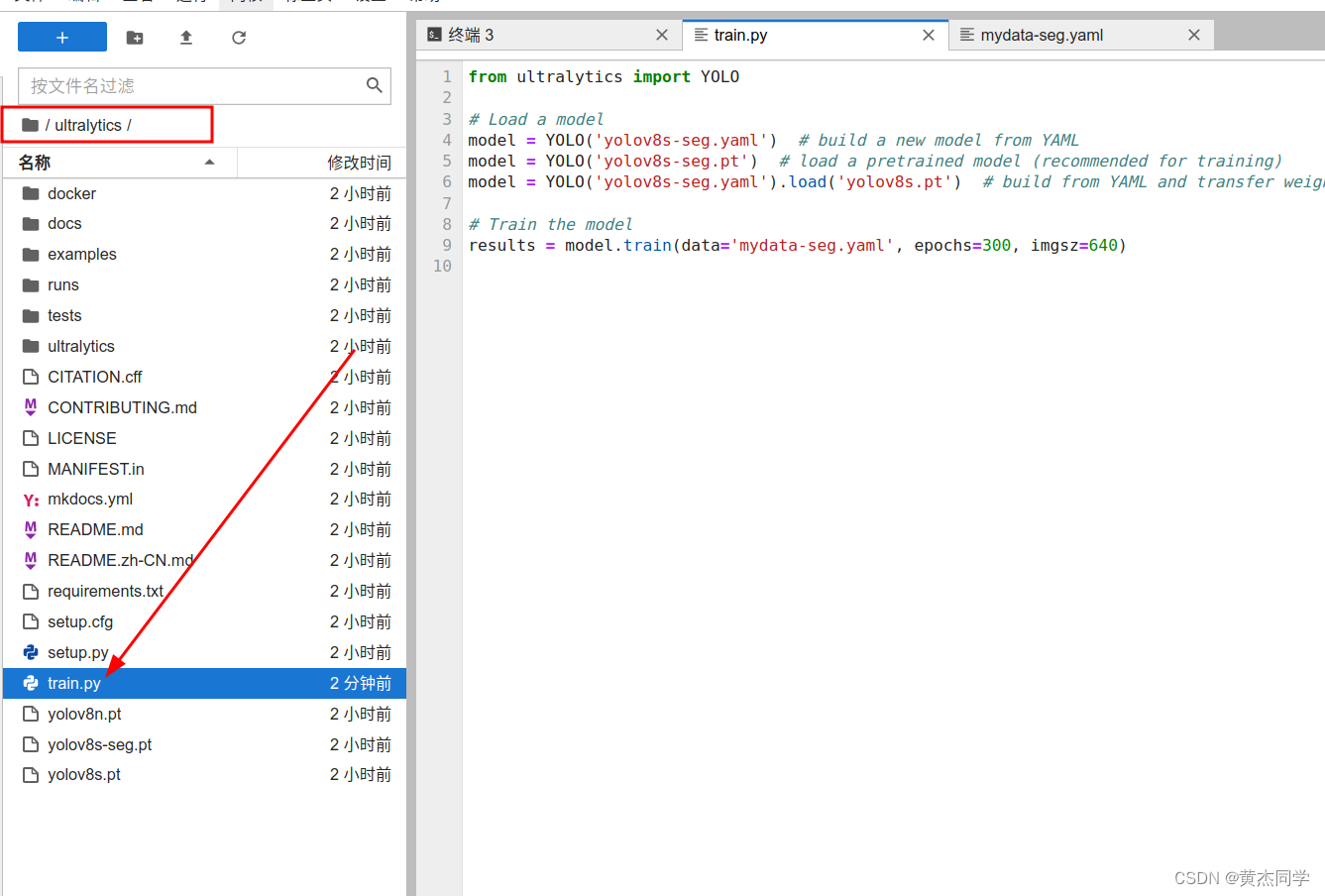
(6)安装必要依赖包(在ultralyics 文件夹下输入指令)
pip install -r requirements.txt
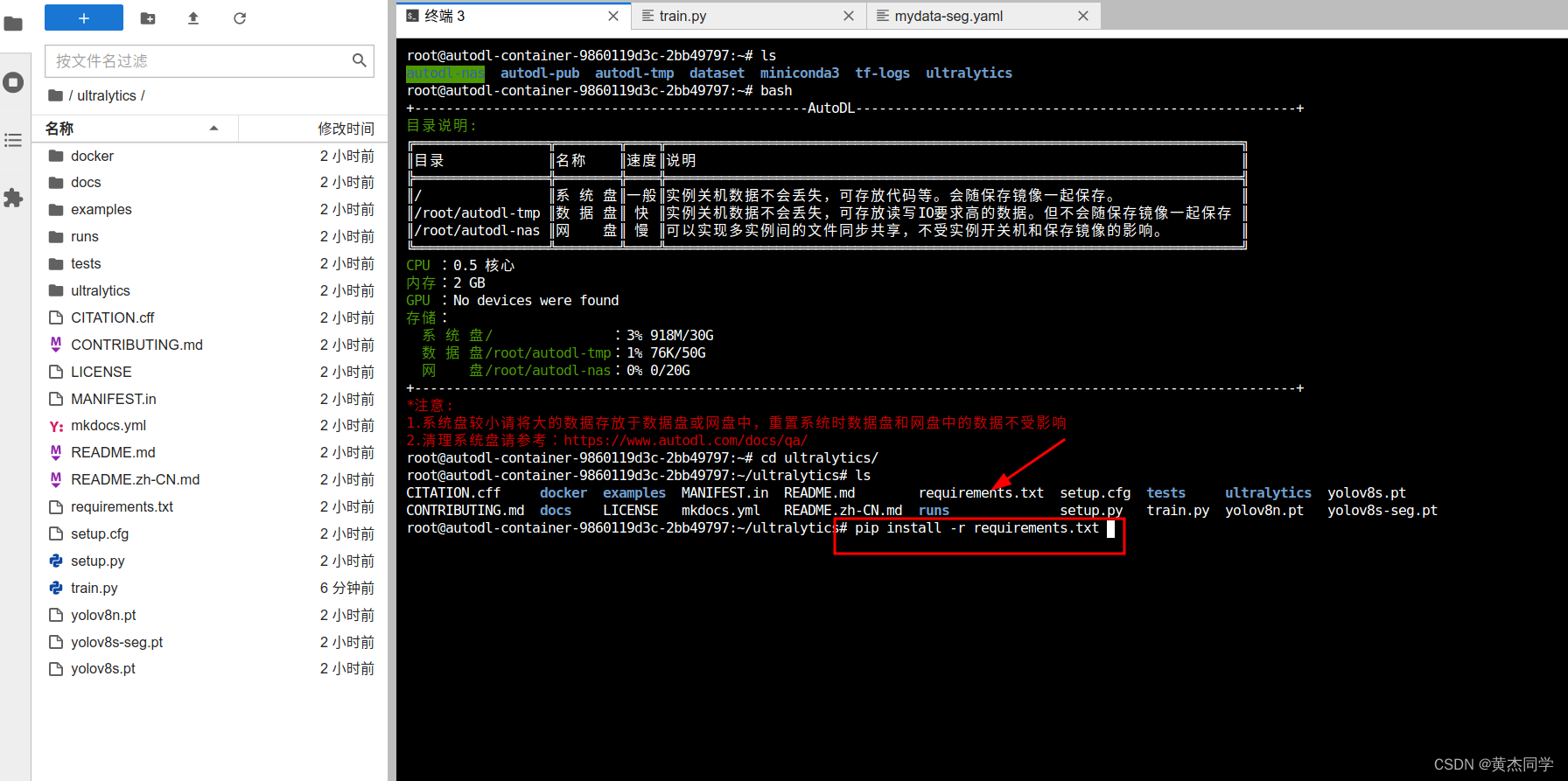
第四步:训练(同样在 ultralyics 文件夹下)
python train.py
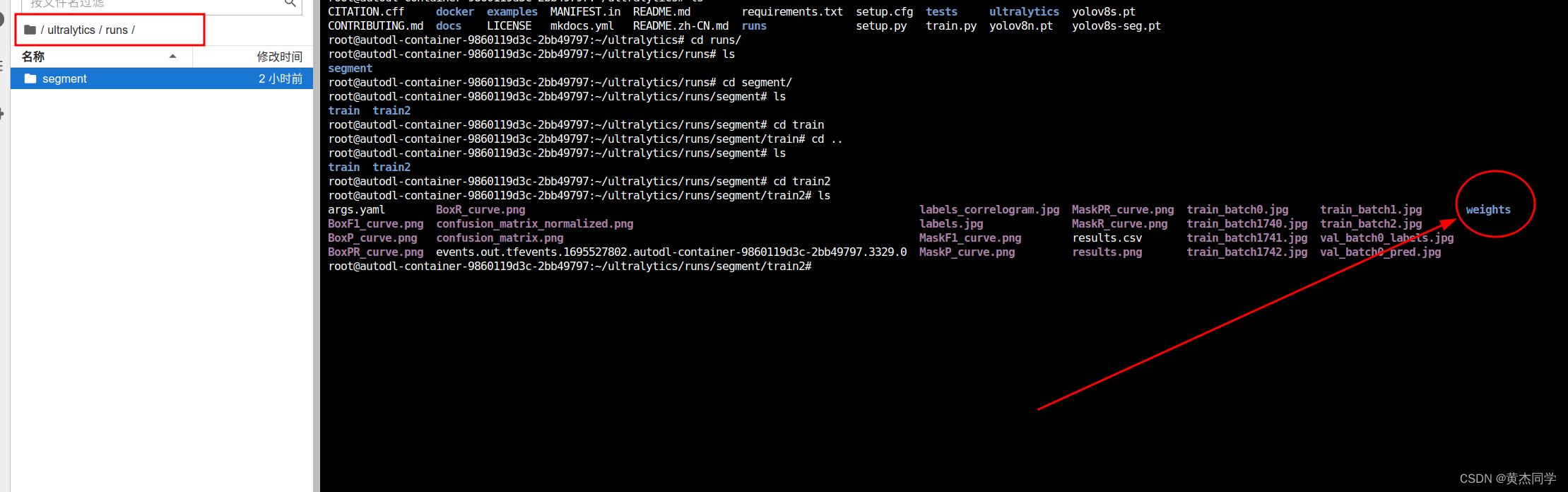
第五步:下载权重参数
在runs文件下找到最新生成的文件,所有权重文件都在那里面。
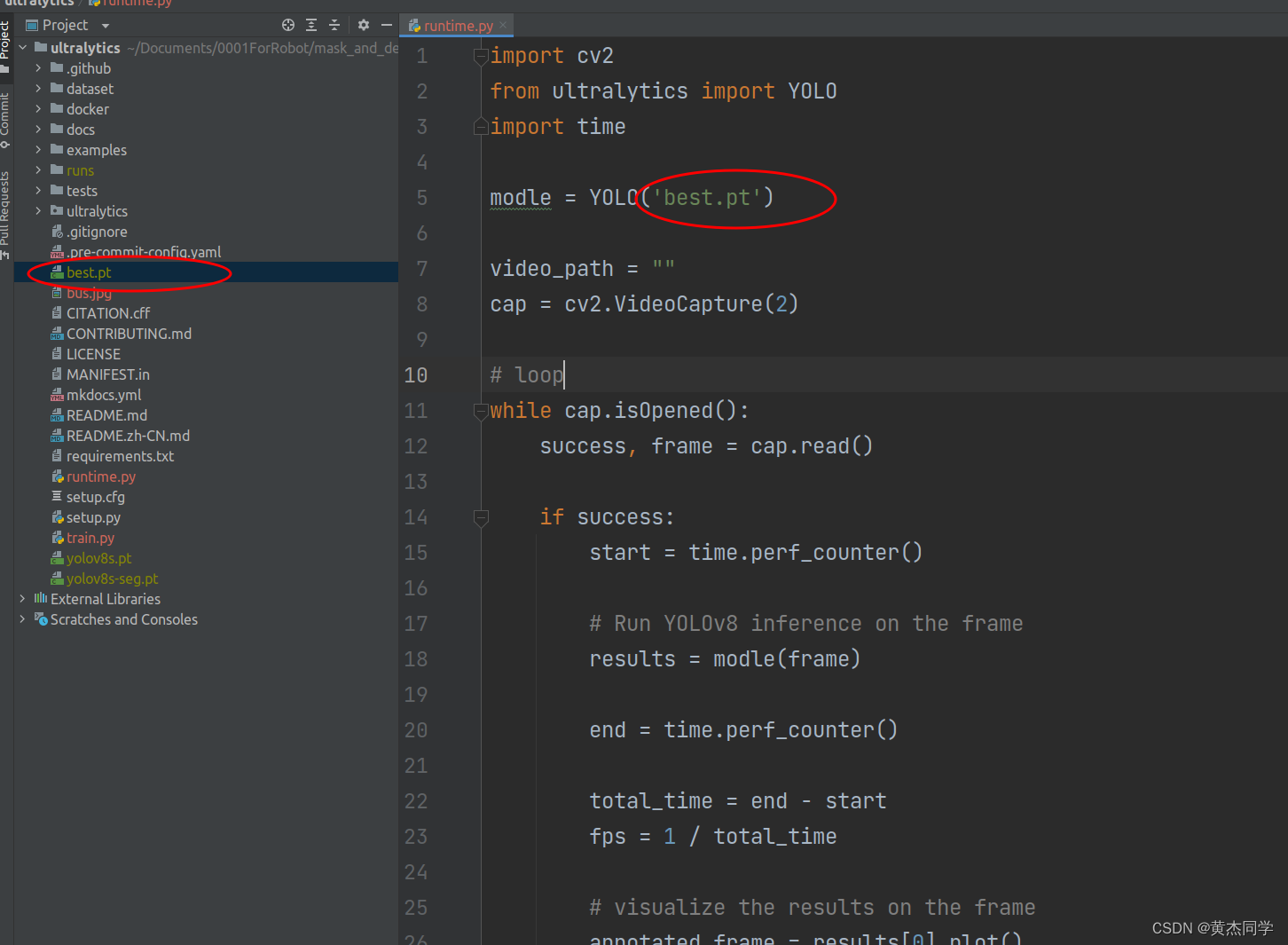
第六步:实现检测物体
将下载好的 best.pt 权重参数,放置在本地ultralyics 文件夹下,执行下面的文件,即可实时检测物体。
-
文件位置
-
实时检测代码
import cv2
from ultralytics import YOLO
import time
modle = YOLO('best.pt')
video_path = ""
cap = cv2.VideoCapture(2) # 更改数字,切换不同的摄像头
# loop
while cap.isOpened():
success, frame = cap.read()
if success:
start = time.perf_counter()
# Run YOLOv8 inference on the frame
results = modle(frame)
end = time.perf_counter()
total_time = end - start
fps = 1 / total_time
# visualize the results on the frame
annotated_frame = results[0].plot()
# display the annotated frame
cv2.imshow("YOLOv8 Inference:", annotated_frame)
# Break the loop if 'q' is pressed
if cv2.waitKey(1) & 0xFF == ord('q'):
break
else:
# Break the loop if the end of the video is reached
break
# Release the video capture object and close the display windows
cap.release()
cv2.destroyAllWindows()
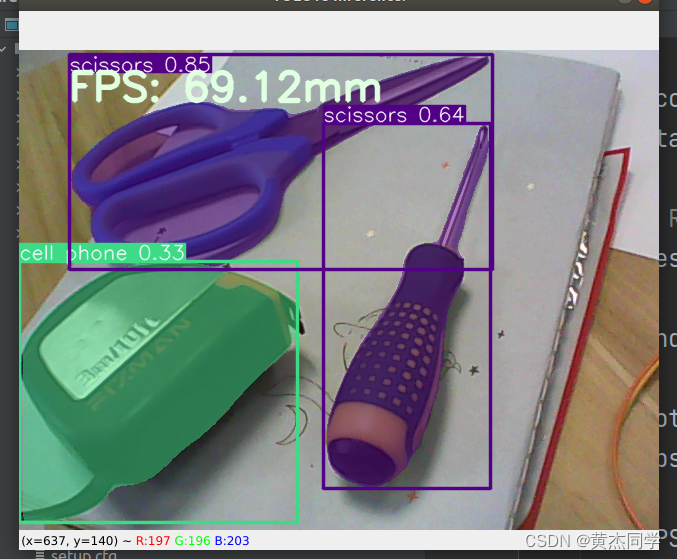
- 实时检测结果
参考文章
- https://zhuanlan.zhihu.com/p/651725860
- https://docs.ultralytics.com/tasks/segment/#predict
- https://docs.ultralytics.com/tasks/segment/#export
- https://github.com/ultralytics/ultralytics


















 3939
3939

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









