







本文是
第一部分数据处理:
数据下载:开源能源系统数据
from pandas import read_csv
from datetime import datetime
from matplotlib import pyplot
# load data
dataset = read_csv('raw1.csv', parse_dates = [0], index_col=0)
dataset.drop('CY_load_entsoe_transparency', axis=1, inplace=True)
dataset.drop('CY_wind_onshore_generation_actual', axis=1, inplace=True)
# manually specify column names
dataset.columns = ['LET', 'SGA', 'WOfGA', 'WOnGA']
dataset.index.name = 'date'
# mark all NA values with 0
dataset['LET'].fillna(0, inplace=True)
dataset['SGA'].fillna(0, inplace=True)
dataset['WOfGA'].fillna(0, inplace=True)
dataset['WOnGA'].fillna(0, inplace=True)
# drop some rows
dataset = dataset[456:35544]#取[456:35544]两年的数据
# summarize first 5 rows
print(dataset.head(5))
# save to file
dataset.to_csv('use.csv')
# load dataset
dataset = read_csv('use.csv', header=0, index_col=0)
values = dataset.values
print(values)
groups = [0, 1, 2, 3]
i = 1
# plot each column
pyplot.figure()
for group in groups:
pyplot.subplot(len(groups), 1, i)
pyplot.plot(values[456:1000, group])
pyplot.title(dataset.columns[group], y=0.5, loc='right')
i += 1
pyplot.show()
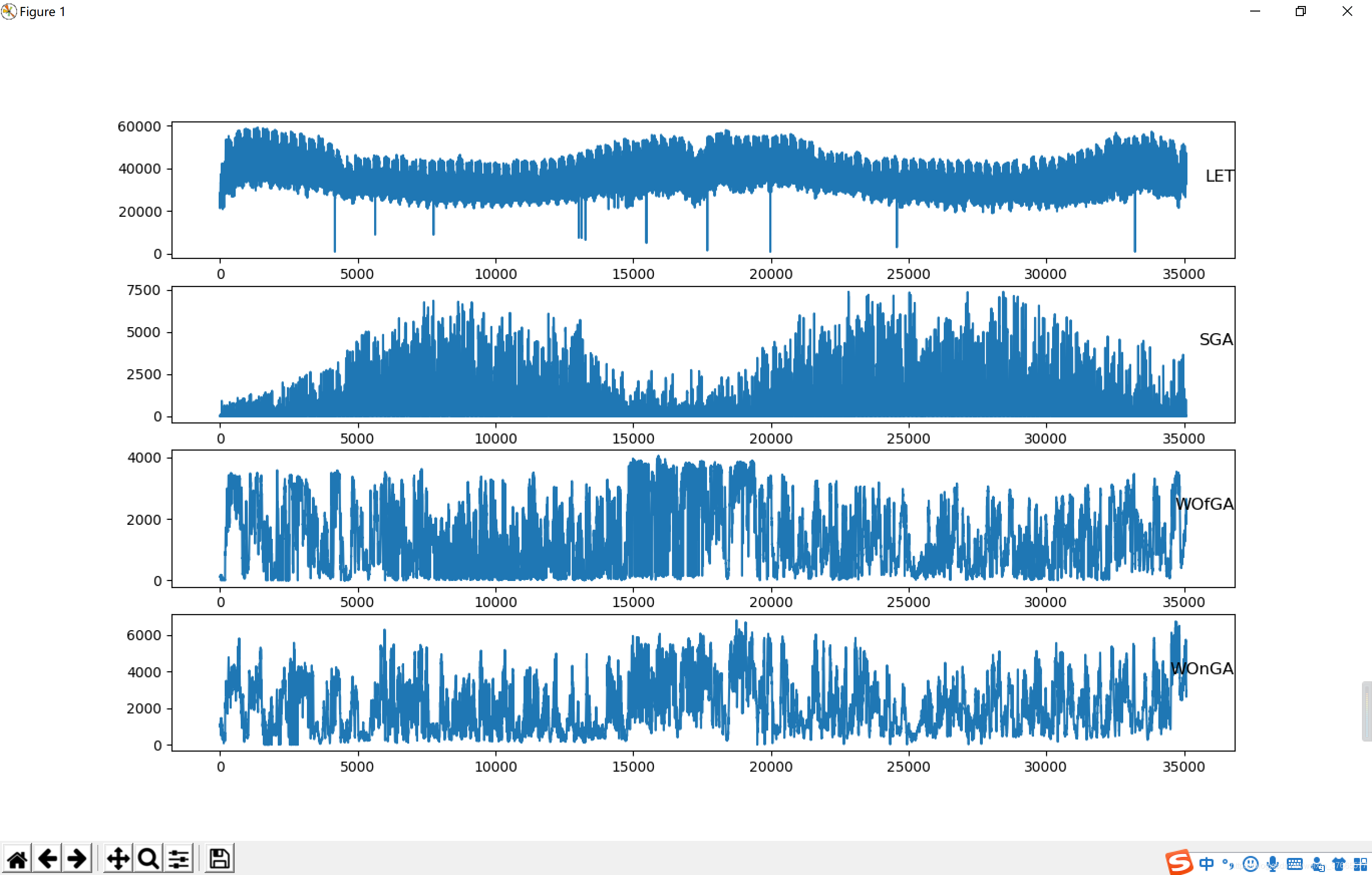
画出两年的趋势
可以看出有些数据很明显是错误的
这个数据有两年半年完整的数据把15-17年的画出来,趋势更明显
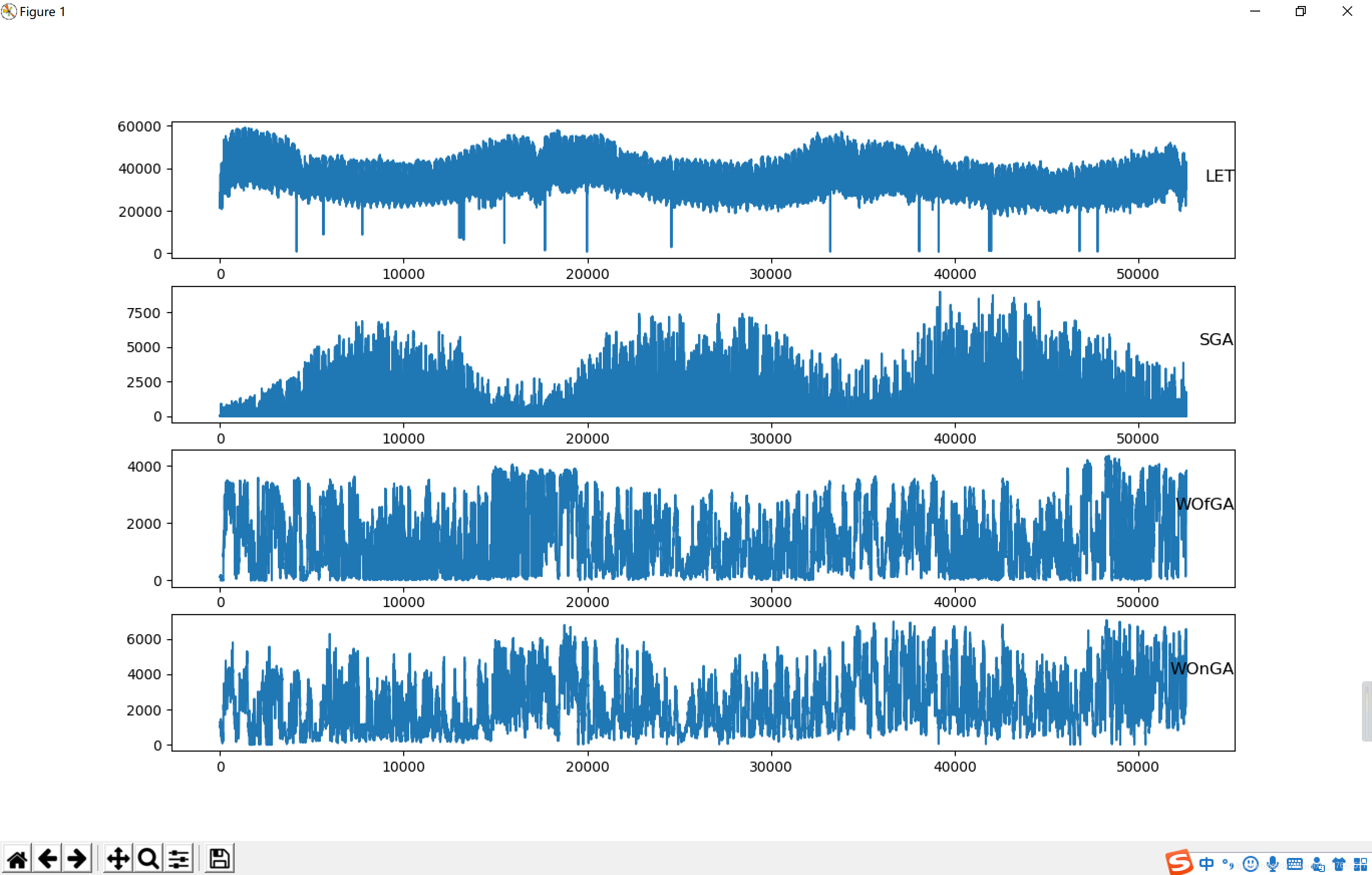
这里应该加上数据处理
接下来就是搭建网络和预测
from math import sqrt
from numpy import concatenate
from matplotlib import pyplot
from pandas import read_csv
from pandas import DataFrame
from pandas import concat
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import mean_squared_error
from keras.models import Sequential
from keras.models import load_model
from keras.layers import Dense
from keras 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









