







1. 什么是hbase
列式的,分布式的,nosql数据库
HBASE是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBASE技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBASE的目标是存储并处理大型的数据,更具体来说是仅需使用普通的硬件配置,就能够处理由成千上万的行和列所组成的大型数据。
HBASE是Google Bigtable的开源实现,但是也有很多不同之处。比如:Google Bigtable利用GFS作为其文件存储系统,HBASE利用Hadoop HDFS作为其文件存储系统;Google运行MAPREDUCE来处理Bigtable中的海量数据,HBASE同样利用Hadoop MapReduce来处理HBASE中的海量数据;Google Bigtable利用Chubby作为协同服务,HBASE利用Zookeeper作为对应。
为什么会出现hbase?
假设一个文件夹下面有一百万个小文件,每个文件1k,那么在hdfs底层存储的时候,他占用的空间可能还没有128M,所以DataNode是没有什么问题的,但是NameNode存的是元数据,100万个文件的元数据会让NameNode崩掉。所以他不会写到hdfs中去,而会写道hbase中去,hbase中也有主从的概念,当一条条数据过来的时候首先会缓存在hbase的从节点中,存于他的内存,当他达到128M的时候的时候,一起写入hdfs中,这样hdfs中只有就只有一条元数据的信息。hbase他其实就是一个缓存层。
2.Hive和hbase的区别:
Hbase和Hive在大数据架构中处在不同位置,Hbase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是配合使用。
- Hbase: Hadoop database 的简称,也就是基于Hadoop数据库,是一种NoSQL数据库,主要适用于海量明细数据(十亿、百亿)的随机实时查询,如日志明细、交易清单、轨迹行为等。
- Hive:Hive是Hadoop数据仓库,严格来说,不是数据库,主要是让开发人员能够通过SQL来计算和处理HDFS上的结构化数据,适用于离线的批量数据计算。通过元数据来描述Hdfs上的结构化文本数据,通俗点来说,就是定义一张表来描述HDFS上的结构化文本,包括各列数据名称,数据类型是什么等,方便我们处理数据,当前很多SQL ON Hadoop的计算引擎均用的是hive的元数据,如Spark SQL、Impala等;基于第一点,通过SQL来处理和计算HDFS的数据,Hive会将SQL翻译为Mapreduce来处理数据;
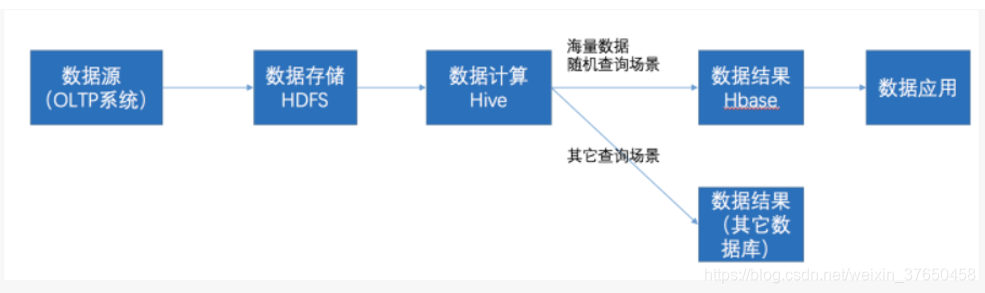
在大数据架构中,Hive和HBase是协作关系,数据流一般如下图:
- 通过ETL工具将数据源抽取到HDFS存储;
- 通过Hive清洗、处理和计算原始数据;
- HIve清洗处理后的结果,如果是面向海量数据随机查询场景的可存入Hbase
- 数据应用从HBase查询数据;
3.与传统数据库的对比
1、传统数据库遇到的问题:
1)数据量很大的时候无法存储
2)没有很好的备份机制
3)数据达到一定数量开始缓慢,很大的话基本无法支撑
2、HBASE优势:
1)线性扩展,随着数据量增多可以通过节点扩展进行支撑
2)数据存储在hdfs上,备份机制健全
3)通过zookeeper协调查找数据,访问速度块。
hbase集群中的角色
1、一个或者多个主节点,Hmaster
2、多个从节点,HregionServer
4.安装habse:
汪先生按的版本是0.9x的版本,还是搭建在这个hadoop集群上。
1.上传解压安装文件并重命名:
2.修改环境变量(每台机器都要执行) 记住一定要加apps,就是目录一定要对
在master机器上执行下面命令:
su – root
vi/etc/profile
添加内容:
| export HBASE_HOME=/home/hadoop/hbase export PATH=$PATH:$HBASE_HOME/bin |
执行命令:
source /etc/profile
su – hadoop
在其他机器上执行上述操作。
修改过一定要执行:source /etc/proflie
3.配置hbase的配置文件:

1.Hbase-env.sh:
export JAVA_HOME=/usr/local/jdk1.7.0_71
export HBASE_CLASSPATH=/apps/hbase/conf
export JAVA_CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HBASE_OPTS="-XX:+UseConcMarkSweepGC"
export HBASE_MANAGES_ZK=false
配置是否适用自己的zookeeper:

2.Regionservers:
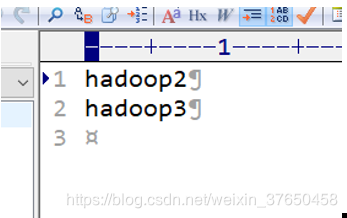
配置从节点:我的是hadoop1,hadoop2,hadoop3
3.hbase-site.xml:
<configuration>
<property>
<name>hbase.master</name>
<value>hadoop1:60000</value>
</property>
<property>
<name>hbase.master.maxclockskew</name>
<value>180000</value>
</property>
<property>
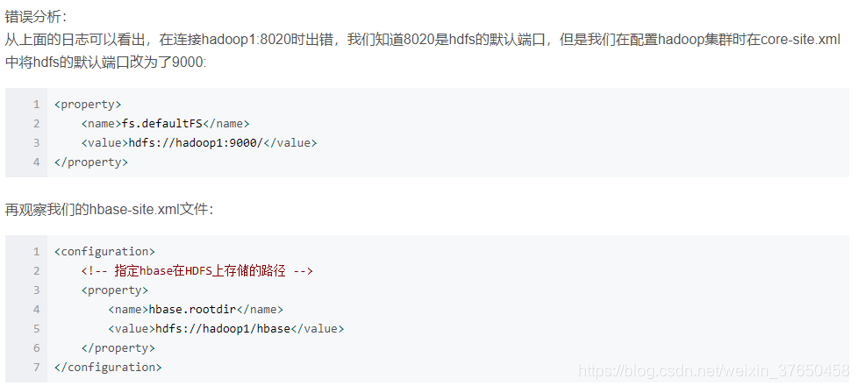
<name>hbase.rootdir</name>
<value>hdfs://hadoop1:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>zookeeper1</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/hbase/tmp/zookeeper</value>
</property>
</configuration>


以上就是hbase的配置,配置完了以后需要配置hadoop:
4.core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hdpdata</value>
</property>
</configuration>
5. hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
6.Hosts文件:
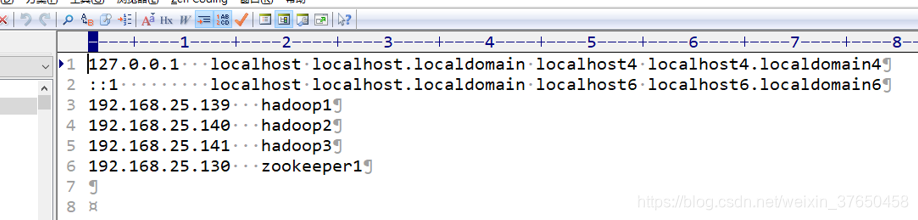
把hadoop的hdfs-site.xml和core-site.xml 放到hbase/conf下
4.分发到其他节点 注意目录一定要对

5.启动:

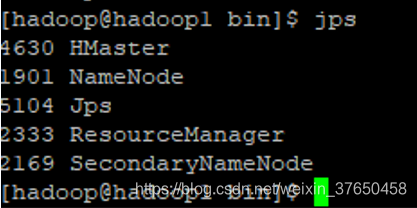
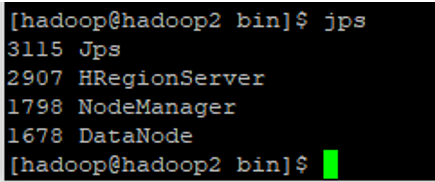
问题:
1.无法加载主类,一看目录不正确,修改profile文件,完了记住刷新配置文件
修改了之后一定记得刷新配置文件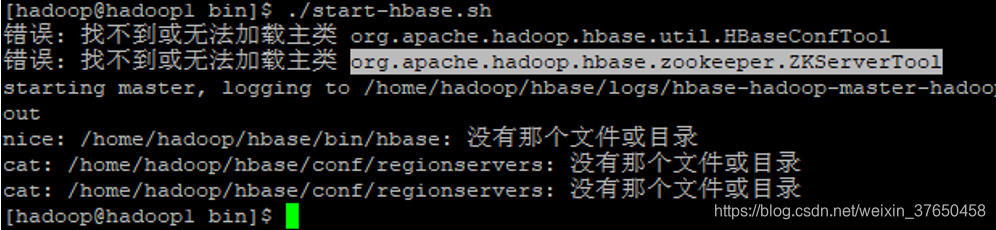
其次是hmaster启动后自动消失的问题,可能是zookeeper缓存过其他版本的hbase的信息,导致这个问题
那个就要删除zookeeper的hbase节点再重启zookeeper
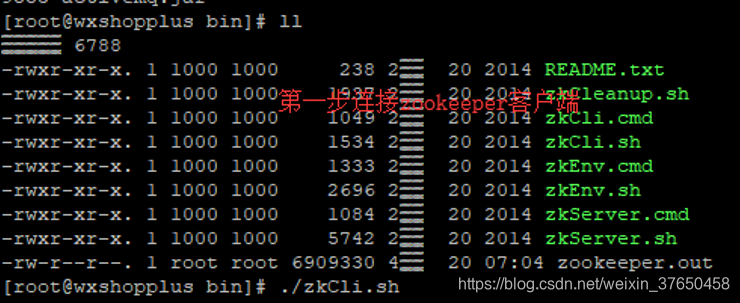
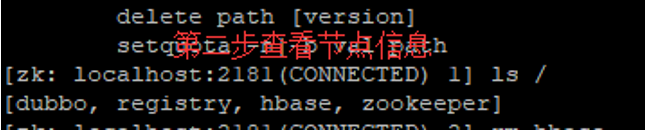

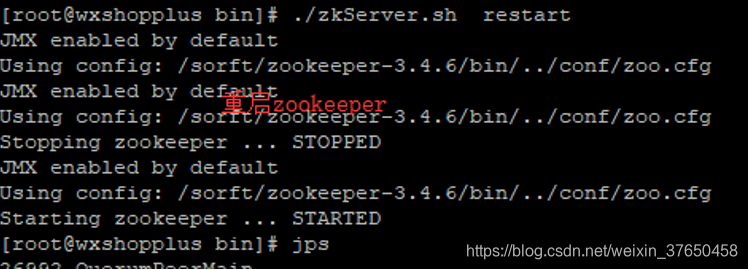
然后发现问题仍然没有解决
最后是这个问题,就加上端口设置就能成功访问:
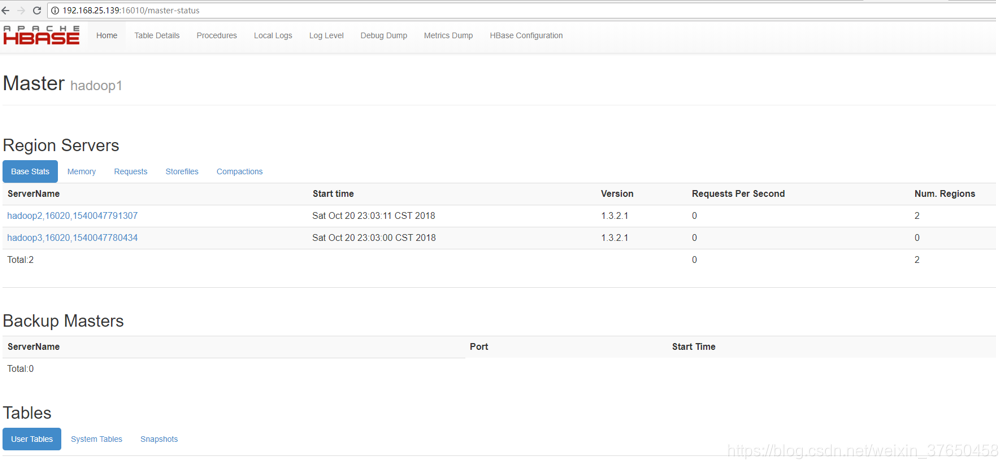
访问:http://192.168.25.139:16010/master-status
还要注意一个版本兼容问题,即hadoop的版本是否与hbase兼容,hbase是否与jdk兼容
问题处理:
Unhandled Java exception: java.lang.IncompatibleClassChangeError: Found class jline.Terminal, but interface was expected
问题原因:/usr/java/hadoop-2.6.5/share/hadoop/yarn/lib/jline-0.9.94.jar 版本低了
解决办法: 替换hadoop的jline jar 包 hadoo/share/hadoop/yarn/lib/的下面,如下
rm -rf /usr/java/hadoop-2.6.5/share/hadoop/yarn/lib/jline-0.9.94.jar
cp /usr/java/apache-hive-2.1.1-bin/lib/jline-2.12.jar /usr/java/hadoop-2.6.5/share/hadoop/yarn/lib/
7.启动多个HMaster
./hbase-daemon.sh start master


















 2908
2908

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











