




 本文深入探讨Redis的高级特性,包括事务的原子性与非回滚特性,布隆过滤器在大数据量集合查询中的应用,以及内存回收的不同策略,如LRU和随机回收。同时,提到了Redis的内存淘汰策略,确保在内存限制下维持高效性能。
本文深入探讨Redis的高级特性,包括事务的原子性与非回滚特性,布隆过滤器在大数据量集合查询中的应用,以及内存回收的不同策略,如LRU和随机回收。同时,提到了Redis的内存淘汰策略,确保在内存限制下维持高效性能。
一、前文回顾
在上一篇文章中,介绍了部分Redis的高级知识,今天这篇文章将继续一起学习Redis。
二、Redis高级部分
1、事务
熟悉关系型数据库的你一定知道什么是事务。事务的四大特性ACID
A:原子性,一个事务不可以再被分割。
C:一致性,要么成功要么失败。
I:隔离性,不同事务之间相互隔离不会影响。
D:事务结束后数据被永久的存下来。
但是Redis中的事务和我们通常认识的事务并不很相同,例如Redis中的如果在事务中出现错误并不会回滚,而是会继续执行。至于为什么这么做,Redis官方是这么说的
- Redis 命令只会因为错误的语法而失败(并且这些问题不能在入队时发现),或是命令用在了错误类型的键上面:这也就是说,从实用性的角度来说,失败的命令是由编程错误造成的,而这些错误应该在开发的过程中被发现,而不应该出现在生产环境中。
- 因为不需要对回滚进行支持,所以 Redis 的内部可以保持简单且快速。
(1)事务的使用方式
开启一个事务:MUILT
此时表示事务已经开启,接下来我们可以在这个事务中输入一系列的 命令
可以看到Redis服务器返回给我们的是一个QUEUED字符串,表示已经当前的命令已经添加到队列中去。
执行一个事务:EXEC
可以看到,2条指令被执行了。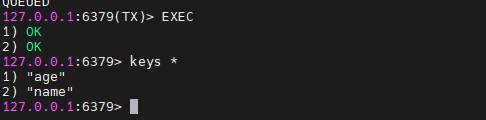
再回到刚才的话题,如果事务之间出错了并不会回滚,让我们来验证一下、错误分为两种,一种是执行在EXEC之前(例如输入了不存在的命令),另一种是命令在EXEC执行之后(简单的说语法是正确的,但是操作错误了,例如对字符串进行+1操作),针对这两种情况我们分别演示
执行在EXEC之前:
我们故意输错一个命令,此时可以看到Redis服务器返回的响应是事务被丢弃了,因为可错误。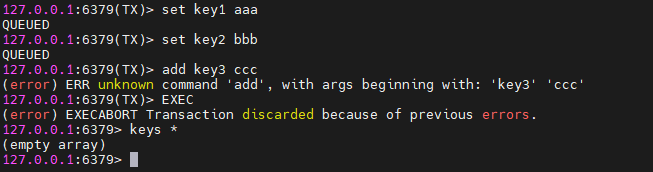
在EXEC执行之后
很明显字符串类型是不能加1的,但是“INCR key2”这条命令也被正常的添加到了队列中去,同时其他两条命令也正常的执行了。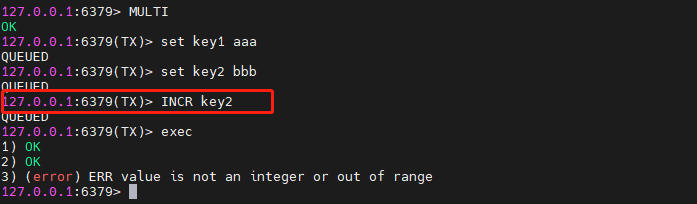
(2)多个Client开启事务
client1先开启 client2后开启。命令会依次执行(可以理解为在队列里),只有只想到exec的时候,才会开始执行事务里的命令。(谁先exec,谁先执行)
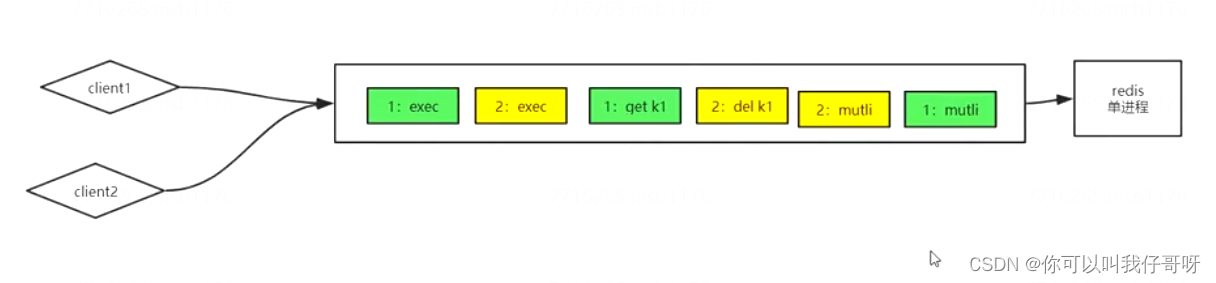
补充:
Mulit:开启事务
Exec:执行事务
Discard:取消事务
Watch:标记所有指定的key 被监视起来,在事务中有条件的执行(乐观锁)如果被监控的Key被修改了,后续的指令是不会执行的。
2、布隆过滤器
简介:布隆过滤器(Bloom Filter)是 1970 年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
布隆过滤器可以判断某个数据一定不存在,但是无法判断一定存在。所以有一定的误判率(因为存在哈西碰撞)
布隆过滤器的场景:
比如有如下几个需求:
①、原本有10亿个号码,现在又来了10万个号码,要快速准确判断这10万个号码是否在10亿个号码库中?
解决办法一:将10亿个号码存入数据库中,进行数据库查询,准确性有了,但是速度会比较慢。
解决办法二:将10亿号码放入内存中,比如Redis缓存中,这里我们算一下占用内存大小:10亿*8字节=8GB,通过内存查询,准确性和速度都有了,但是大约8gb的内存空间,挺浪费内存空间的。
②、接触过爬虫的,应该有这么一个需求,需要爬虫的网站千千万万,对于一个新的网站url,我们如何判断这个url我们是否已经爬过了?
解决办法还是上面的两种,很显然,都不太好。
③、同理还有垃圾邮箱的过滤。
那么对于类似这种,大数据量集合,如何准确快速的判断某个数据是否在大数据量集合中,并且不占用内存,布隆过滤器应运而生了。
简单的说:在大量数据中判断某些数据是否存在
注意点:
(1)如果出现了穿透了布隆过滤器但是数据库实际上是没有数据的情况,需要客户端把这个数据维护到布隆过滤器上。
(2)其他客户端在数据库增加了数据,也要写到布隆过滤器中(这里又涉及到了数据库和缓存的双写一致性问题,这个放在后面讲)
3、回收策略
我们知道Redis作为内存数据库最重要的一个特定就是非常快,这也是我们为什么使用Redis,但是事务总是具有双面性,Redis作为内存数据库不可能很大(当然了也有很大的内存数据库,这里不做讨论),所以一定会存在某种策略用于回收重复利用内存,Redis中有一下几种
- noeviction:返回错误当内存限制达到并且客户端尝试执行会让更多内存被使用的命令(大部分的写入指令,但DEL和几个例外)
- allkeys-lru: 尝试回收最少使用的键(LRU),使得新添加的数据有空间存放。
- volatile-lru: 尝试回收最少使用的键(LRU),但仅限于在过期集合的键,使得新添加的数据有空间存放。
- allkeys-random: 回收随机的键使得新添加的数据有空间存放。
- volatile-random: 回收随机的键使得新添加的数据有空间存放,但仅限于在过期集合的键。
- volatile-ttl: 回收在过期集合的键,并且优先回收存活时间(TTL)较短的键,使得新添加的数据有空间存放。
如果使用Redis作为数据库使用,一般使用noevition策略。
如果使用Redis作为缓存使用,一般在allkeys-lru和volatile-lru中选一个。4和5 太随意了不适合,6的话复杂度太高。
2和3 如何选型:
如果缓存里的key大量配置了过期时间则使用volatile-lru否则使用allkeys-lru
(注意,如果对于一个key发生了写的操作,会剔除过期时间,即原本key = key1,value = aaa,过期时间10s,然后将key1的value设置为bbb,此时过期时间就没了。可以理解为重新覆盖了一个key)
4、内存淘汰策略
想必你也知道,Redis中是可以设置某个key的过期时间的,那么时间到了是如何被删除的呢?这里就要提到Redis的内存淘汰策略了。
Redis keys过期有两种方式:被动和主动方式。
当一些客户端尝试访问它时,key会被发现并主动的过期。
当然,这样是不够的,因为有些过期的keys,永远不会访问他们。 无论如何,这些keys应该过期,所以定时随机测试设置keys的过期时间。所有这些过期的keys将会从密钥空间删除。
具体就是Redis每秒10次做的事情:
- 测试随机的20个keys进行相关过期检测。
- 删除所有已经过期的keys。
- 如果有多于25%的keys过期,重复步奏1.
这是一个平凡的概率算法,基本上的假设是,我们的样本是这个密钥控件,并且我们不断重复过期检测,直到过期的keys的百分百低于25%,这意味着,在任何给定的时刻,最多会清除1/4的过期keys。
这么做的目的是,牺牲一部分的内存空间来换去Redis更高的性能
三、小结
今天主要讲了一些Redis中相对高级的部分,下文将继续讲解该部分,包括持久化、以及其他内容。希望对你有所帮助。

















 1910
1910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









