







原创: Lebhoryi@rt-thread.com
时间: 2020/04/15
文章目录
0x00 Paper
作者提出的
memory consumption, 之前的优化方向memory footprint, 两者没能理解什么是group depthwise separable convolution,更低参数数量的时候用了GDSC
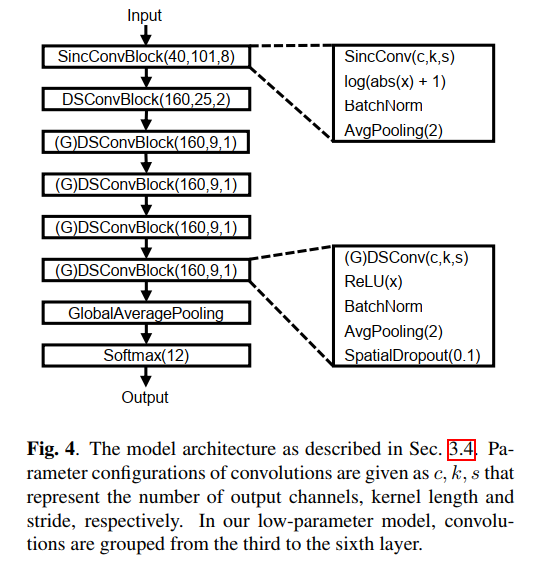
什么是SincNet,本文的第一层用了SincNet的第一层
- 作者第一次将SincNet使用到了KWS任务中,之前都是用在ASR上
- 可以直接把原始音频作为输入,跳过提取mfcc特征这个步骤
- 使用了group DSCconv,有效降低了参数的数量
- 测试的平台是用电池的嵌入式设备
- 没有开源,不过用SincNet直接读取原始音频进行训练是一个很nice的idea
0x01 为了解决什么问题
- 问题:
- KWS 存在硬件设备和功耗受限的问题
- 目的
- 为了解决功耗和内存消耗
- 解决
- 使用参数化的Sinc卷积来提取光谱特征
- 直接对原始音频数据进行分类,消除了比较耗电的音频预处理和数据传输步骤(没理解,为啥耗电,什么是数据传输步骤)
- Power-consuming audio preprocessing and data transfer steps are eliminated by directly classifying from raw audio.
- 结果
- 在Google’s Speech Commands 测试集上准确率高达96.4%
- only 62k parameters
0x02 提出了哪些创新点
之前的工作优化方向在于优化每秒计算的内存和操作数
2.1 提出了一个更加节能的神经网络
- 通过观察内存功耗来调整神经网络,实现微控制器的节能
2.2 使用了SincConvs
-
第一次把这个网络结构使用到KWS上,之前都是用作语音识别
-
使用了DSConvs减少计算量
2.3 参数少,性能好
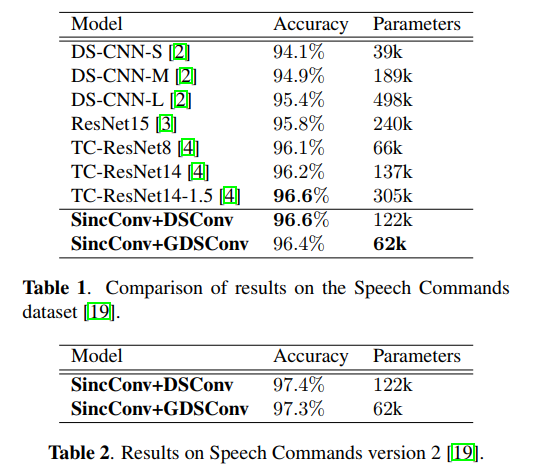
- 对比于TC-ResNet 305k参数,96.6% acc,本文的只有 122k,96.6%acc
- 最少只有62k parameters
0x03 网络
3.1 需求
- 低电量消耗
- 假设内存消耗和电池消耗相关
- 内存消耗观察电池消耗
- 方法
- 参数减少
- 量化
- 模型压缩
- 优化数据流
- 实时性
- 低内存占用
- 高准确率
3.2 网络结构
- 第一层使用了SincNet的第一层,叫做SincConv
- 可以直接把原始音频作为网络的输入,而不是MFCC作为网络的输入
- s i n c ( x ) = s i n ( x ) / x sinc (x) = sin(x) / x sinc(x)=sin(x)/x
- 一个sinc可以作为一个矩形,两个可以做为带通滤波器使用,没有能理解透彻
- One sinc function in the time domain represents a rectangular function in the spectral domain, therefore two sinc functions can be combined to an ideal band-pass filter
- 使用Groping 之前,参数量是122k,使用之后是62k


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









