







1. 什么是Wide & Deep Learning
Wide & Deep learning模型,是由谷歌在2016发表,并曾在Goole Play上进行实验。该模型通过联合训练广度线性模型和深度神经网络,来实现推荐系统的Memorization和Generalization。
Memorization和Generalization是什么?
Memorization:学习频繁的、共同出现的features(特征组合),个人理解为一种对已有的历史数据的记忆能力。所以基于Memorization的推荐更有主题性,与用户历史行为更直接相关。
Generalization:探索那些历史中没有或很少出现的新的特征组合,个人理解为一种推广的能力。基于Generalization的推荐更倾向于推荐的多样性。
为什么会提出Wide & Deep Learning?
logistic regression是一种简单的线性模型,它使用cross-product transformations(即多项式中二阶、高阶项)实现Memorization。使用颗粒更小的特征实现Generalization ,但是需要手动构建特征工程。
cross-product是不能对在历史数据中没有出现过的特征对进行推广并学习,为了解决这个问题,出现了FM和DNN。
FM和DNN,是基于Embedding的模型,它们都会针对每个query-item特征得到一个为稠密的低维的embedding向量(在FM中就是隐向量),该embedding向量就是特征的表现力。通过学习embedding向量,进而FM和DNN可以完成cross-product无法完成的任务,即可以学习历史数据中没有出现过的特征对。
然而,当query-item矩阵稀疏且高秩时,就很学习到针对item和query的有效的低纬度表示(即embedding向量)。
文章中举了一个例子,当用户有具有特定的偏好时候,那么大多数query-item对都是空的,但是embedding向量会导致对所query-item对的非零预测,因此可能会over-generalize的情况,并提出不太相关的推荐。然而,这种情况下,cross-product却能使用比较少的参数来记住这些偏好。
因此,Wide & Deep learning模型其实是将cross-product和DNN以并行的方式结合起来,并进行联合训练。那么,cross-product可以用较少的参数来补充DNN的不足,去记住用户偏好;而DNN可以自动构建高阶的特征组合,来预测用户未出现过的行为。
2.Wide & Deep结构
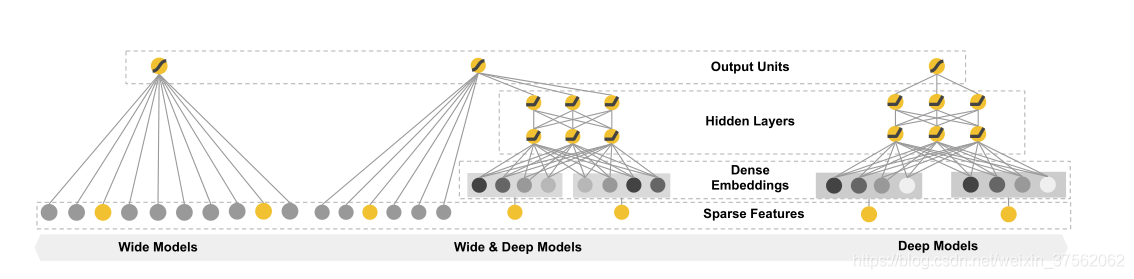
Figure 1: The spectrum of Wide & Deep models.
上图中,最左边为线性模型,最右边为神经网络模型,而中间的就是二者结合的Wide & Deep。
2.1 Wide 部分
该部分是一个广义的线性模型:
是一个d维特征向量。特征包括两部分,原始输入特征和变换后特征。变换后特征中最重要的一种就是cross-product。
2.2 Deep 部分
该部分是一个前馈神经网络。
在Embedd层中,categorical features特征(常为字符串),首先转为embedding vector,维度为O(10) 到 O(100)。
在Hidden层中,首先embedding vector被输入,经过ReLU激活后输入下一层,公式如下:
2.3 联合训练
首先我们需要明白,联合训练(joint training)和集成训练(ensemble)的区别。
集成训练中,不同模型在训练期间彼此隔离,不知道彼此存在,只在预测的时候将不同模型的输出值结合起来。联合训练与之相反,在训练期间会同时考虑各个部分,并同时优化各个模型所有参数。所以联合训练中,我们的wide部分只需要少部分的corss-product变换就可以补充神经网络的不足,而不需要一个庞大的线性模型。
预测公式
作为一个线性回归问题,预测公式为:
Y是0/1标签,是sigmoid函数,
是cross-product变换。
反向传播
在输出层中,wide部分和deep部分的最后输出结合起来,送入Logistic loss,再利用小批量随机优化方法(mini-batch stochastic optimization),将计算好的梯度反向传播只wide和deep部分。在实验中,文章使用了Followthe-regularized-leader (FTRL),其中L1正则化作为wide部分的优化器,AdaGrad作为deep部分的优化器。
3. 推荐系统实现
3.1 推荐系统概述
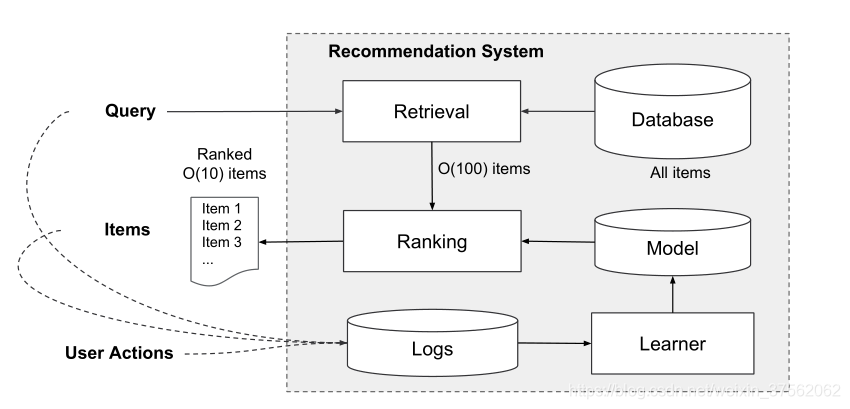
Figure 2: Overview of the recommender system
上图是推荐系统的概述。
Query:包括用户和上下文特征,会在用户访问app store时生成。
Retrieval:该模块会在庞大的Database选择出最适合Query的item(即app)列表,通常是机器学习模型和人类定义的规则的组合。
Ranking:对item列表进行打分并排序,分数常为
经过Ranking后的item列表,会有推荐系统返回给用户,我们称这个item列表为impression。用户可以在impression中的item进行点击或购买操作,这些行为就是User Actions。
user actions,query,以及impression都会作为训练的数据,送入Logs日志系统。
文章中举了一些特征的例子,比如用户特征有country、language、demographics等,上下文特征中有device, hour of the
day, day of the week等,impression特征有app age、historical statistics of an app等。
3.2 推荐系统实现
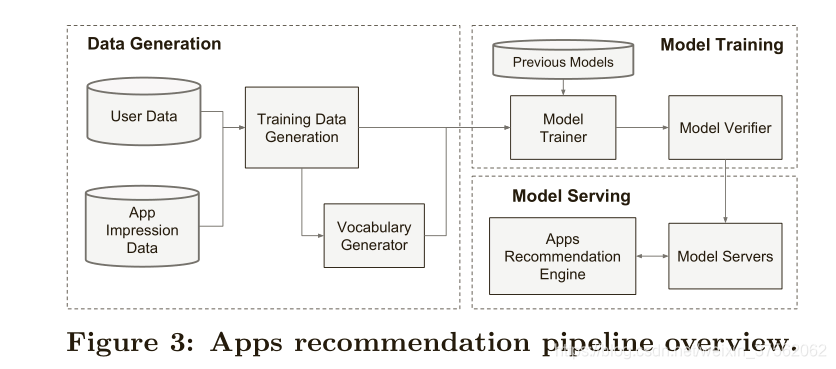
由上图,我么可以看到,整个系统实现分为3个阶段:Data Generation、Model Tranining、Model Serving
Data Generation
在这个阶段,user和app impression数据会用于生成训training data。每个例子对应一个impression。label是app acquisition:如果安装了app,则为1,否则为0。
这里需要注意的是,wide部分和deep部分并不共享输入层的所有数据,他们有着自己分别的输入。也就是说,wide的高阶特征组合是人工手动组合的。
Categorical feature(字符串)会映射到整数id,在Vocabularies存储着映射关系。
Continuous features (数字)会映射到其累积分布函数被规范化为[0,1],并将其划分为
分位数.在
training data和Vocabularies生成后会送入Model Training模块。
Model Tranining
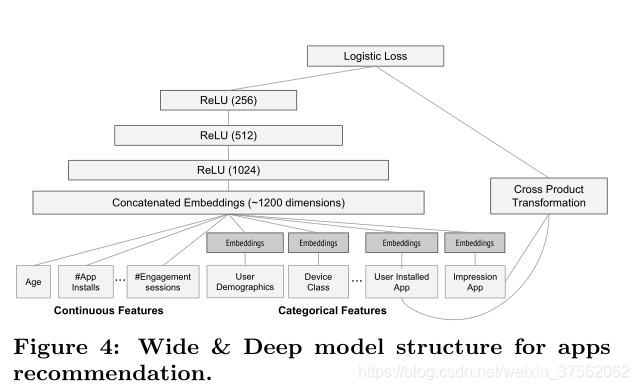
具体的模型结构如上图。
输出层,接受training data和vocabularies,并生成稀疏和稠密特征。
wide部分,对User Installed APP 和 Impressin APP特征进行Cross-Product变换。
deep部分,先需要把Categorical feature转换为32维的embedding向量,然后将embedding向量和Continuous features拼接,接着送入3个ReLU层,最后 送入logistic output unit.
此外,每次一组新的训练数据到达时,都需要对模型进行重新训练。然而,每次从头开始的再培训都会在计算上耗费大量的时间,并且会延迟从数据到达到为更新的模型提供服务的时间。为了应对这一挑战,文章中提到实现了一个热启动系统,该系统使用前一个模型的embeddings和线性模型权重初始化新模型。
Model Serving
一旦模型经过训练和验证,我们就将其加载到模型服务器中。对于每个请求,服务器从应用程序检索系统和用户功能接收一组应用程序候选,以对每个应用程序进行评分。然后,应用程序从最高的分数到最低的排名,我们按此顺序向用户显示应用程序。分数是通过在广度和深度模型上运行正向推理传递来计算的。
为了在10毫秒的时间内满足每个请求,我们使用多线程并行来优化性能,方法是并行运行较小的批,而不是在一个批处理推断步骤中对所有候选应用进行评分。
4. 总结
Wide & Deep模型,在Wide部分中使用cross-product来记忆稀疏特征的组合,实现memorization;在Deep部分中通过embedding向量推广到历史中没有的特征组合,实现cross-product。Wide和Deep部分进行联合训练,但是不共享输入特征,Wide部分需要手工构建特征组合。

















 3349
3349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









