



本文是在Atlas Duo 300I 推理卡上部署LLM推理服务的一次尝试,完整的安装文档参考Ascend 官方。安装过程中遇到问题可以在社区提问,目前该推理卡对新模型的支持不是太好,且实测下来性能不及3090(吐槽:显存虚报,标记48GB实际只有44GB;算力140TFLOAPS,但推理速度来看远低于3090)。如果用于大模型训练或推理,直接使用910。
安装的流程为:
step1:安装驱动和固件
step2:下载mindIE镜像并启动容器
step3:安装CANN等软件
step4:使用mindie-service部署大模型推理服务
由于物理安装比较麻烦,官方提供了镜像,镜像申请后按照相关步骤下载即可,包含cann、mindie和TATB-Models,这样安装起来比较方便。
1. 安装驱动和固件
参考文档选择安装场景-软件安装-CANN商用版8.0.RC2.2开发文档-昇腾社区进行安装,由于我的机器已经安装好,就不进行说明。如果使用npu-smi info出现卡的信息,则证明安装正常。

2. 下载镜像
进入mindie 镜像页,登录后申请下载,我是24h内就通过了,通过后下载对应版本的镜像包即可。
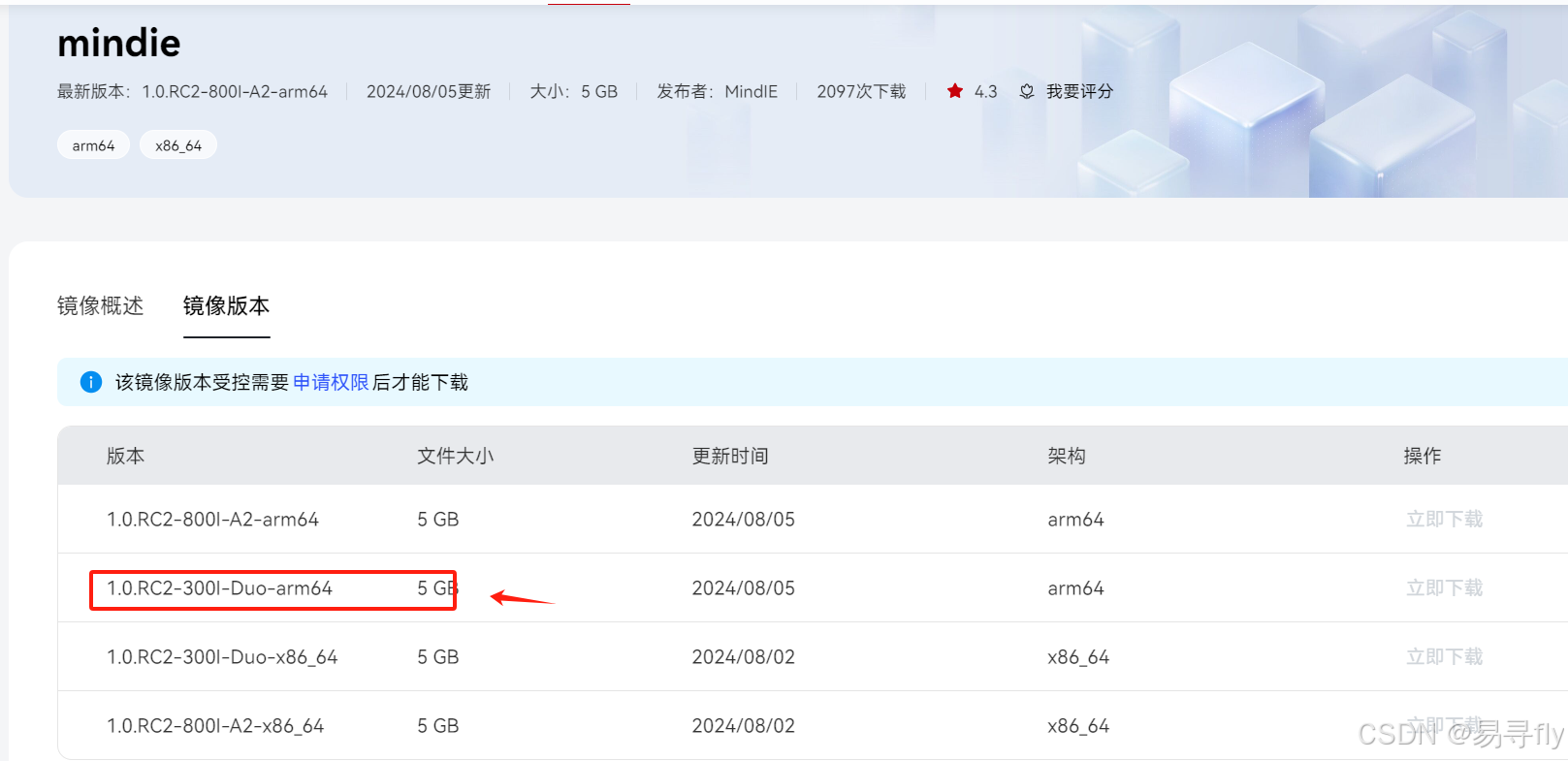
下载后镜像如下图所示,加载后约7GB。

使用如下命令启动容器,注意根据自己的实际情况修改相关目录
docker run -itd --ipc=host --net=host \
--name=llm_infer \
--device=/dev/davinci_manager \
--device=/dev/devmm_svm \
--device=/dev/hisi_hdc \
--privileged=true \
-v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/share/zoneinfo/Asia/Shanghai:/etc/localtime \
-v /home/models:/home/models \
{image_id} /bin/bash# {image_id} 是自己的镜像id,也可以使用{image_name}:{TAG}
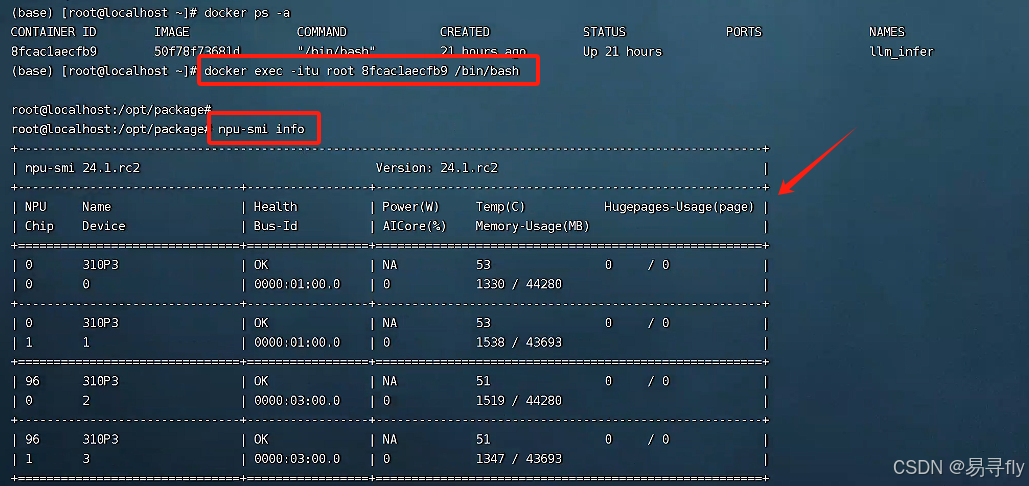
进入容器,并检查在容器中是否可以正常使用npu
# 进入容器命令
docker exec -itu root {container_id} /bin/bash
# 查看npu信息
npu-smi info
3. 安装CANN等相关软件
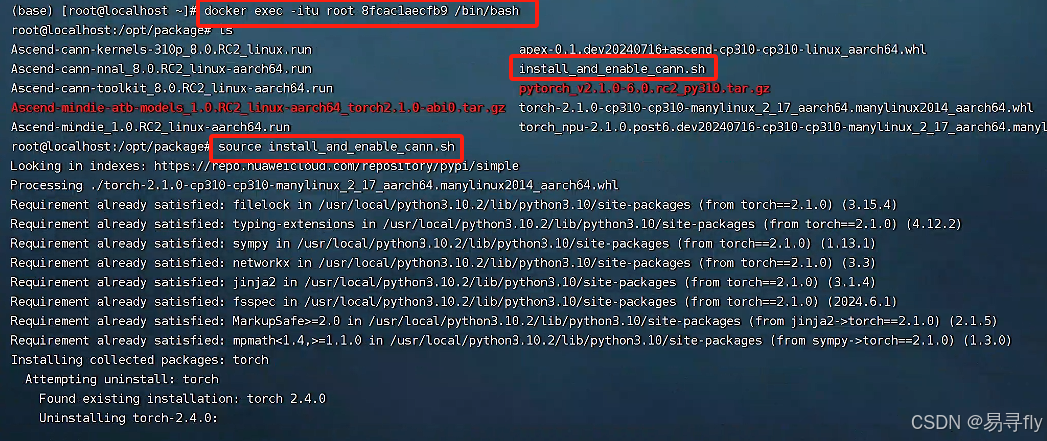
进入容器并安装cann,命令及相关结果如下
# 进入/opt/package 目录,可以看见所有的安装包及安装脚本
# 运行安装脚本
source install_and_enable_cann.sh
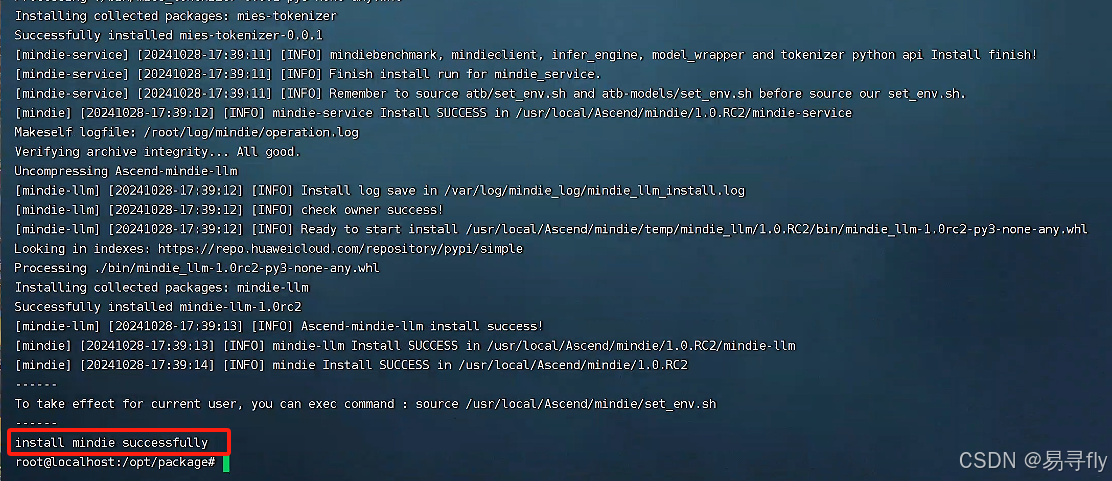
如果最终界面如下图所示,则表示安装成功
安装后相关软件目录位于/usr/local/Ascend下,如下图所示,可以看见安装后的ascend-toolkit、llm_model、mindie和nnal。

推理Qwen1.5模型测试,如果想测试其他模型可查看MindIE支持模型列表。这里列出的模型一般是没问题的,但不同的推理卡可能会有不同的支持(如我测试Llama3时就发现目前是无法使用的,mask搞错了。)。
# 打开llm_model 所在目录
cd /usr/local/Ascend/llm_model/
# 运行测试脚本
python examples/run_pa.py --model_path /home/models/Qwen1.5-14B-Chat/

!!注意相关的环境变量在容器重启后会失效,为避免每次重复添加环境变量,可将其添加到文件 "~/.bashrc" 最后,这样容器重启就会自动生效
source /usr/local/Ascend/ascend-toolkit/set_env.sh
source /usr/local/Ascend/nnal/atb/set_env.sh
source /usr/local/Ascend/mindie/set_env.sh
source /usr/local/Ascend/llm_model/set_env.sh
4. 使用mindie-servic部署LLM推理服务
进入mindie目录(/usr/local/Ascend/mindie/latest/mindie-service)
step1. 修改conf/config.json文件,注意
1.修改httpsEnabled的值为false
2.npuDeviceIdsxiu的值修改为其中一块NPU
3.modelName和modelWeightPath进行修改
完整的配置如下,如果启动还有问题请对照进行修改。详细的参数意思可参考官方文档。
{
"OtherParam" :
{
"ResourceParam" :
{
"cacheBlockSize" : 128
},
"LogParam" :
{
"logLevel" : "Info",
"logPath" : "logs/mindservice.log"
},
"ServeParam" :
{
"ipAddress" : "127.0.0.1",
"managementIpAddress" : "127.0.0.2",
"port" : 1025,
"managementPort" : 1026,
"maxLinkNum" : 1000,
"httpsEnabled" : false,
"tlsCaPath" : "security/ca/",
"tlsCaFile" : ["ca.pem"],
"tlsCert" : "security/certs/server.pem",
"tlsPk" : "security/keys/server.key.pem",
"tlsPkPwd" : "security/pass/mindie_server_key_pwd.txt",
"tlsCrl" : "security/certs/server_crl.pem",
"managementTlsCaFile" : ["management_ca.pem"],
"managementTlsCert" : "security/certs/management_server.pem",
"managementTlsPk" : "security/keys/management_server.key.pem",
"managementTlsPkPwd" : "security/pass/management_mindie_server_key_pwd.txt",
"managementTlsCrl" : "security/certs/management_server_crl.pem",
"kmcKsfMaster" : "tools/pmt/master/ksfa",
"kmcKsfStandby" : "tools/pmt/standby/ksfb",
"multiNodesInferPort" : 1120,
"interNodeTLSEnabled" : true,
"interNodeTlsCaFile" : "security/ca/ca.pem",
"interNodeTlsCert" : "security/certs/server.pem",
"interNodeTlsPk" : "security/keys/server.key.pem",
"interNodeTlsPkPwd" : "security/pass/mindie_server_key_pwd.txt",
"interNodeKmcKsfMaster" : "tools/pmt/master/ksfa",
"interNodeKmcKsfStandby" : "tools/pmt/standby/ksfb"
}
},
"WorkFlowParam" :
{
"TemplateParam" :
{
"templateType" : "Standard",
"templateName" : "Standard_llama"
}
},
"ModelDeployParam" :
{
"engineName" : "mindieservice_llm_engine",
"modelInstanceNumber" : 1,
"tokenizerProcessNumber" : 8,
"maxSeqLen" : 5120,
"npuDeviceIds" : [[4]],
"multiNodesInferEnabled" : false,
"ModelParam" : [
{
"modelInstanceType" : "Standard",
"modelName" : "qwen1.5-14b-chat",
"modelWeightPath" : "/home/models/Qwen1.5-14B-Chat",
"worldSize" : 1,
"cpuMemSize" : 5,
"npuMemSize" : 8,
"backendType" : "atb",
"pluginParams" : ""
}
]
},
"ScheduleParam" :
{
"maxPrefillBatchSize" : 50,
"maxPrefillTokens" : 8192,
"prefillTimeMsPerReq" : 150,
"prefillPolicyType" : 0,
"decodeTimeMsPerReq" : 50,
"decodePolicyType" : 0,
"maxBatchSize" : 200,
"maxIterTimes" : 512,
"maxPreemptCount" : 0,
"supportSelectBatch" : false,
"maxQueueDelayMicroseconds" : 5000
}
}step2. 启动服务
# 先试用如下命令启动服务,如果成功会提示success
./bin/mindieservice_daemon
# 如果可正常启动,则可以使用如下命令后台启动服务
nohup ./bin/mindieservice_daemon > output.log 2>&1 &
使用标准openai的形式发起请求,
curl --location 'http://127.0.0.1:1025/v1/chat/completions' -w "请求耗时:%{time_total}秒\n" \
--header 'Content-Type: application/json' \
--data '{
"model": "qwen1.5-14b-chat",
"messages": [
{
"role": "user",
"content": "你是谁,你能干啥"
}
]
}'

对比来看由于单块3090显存无法放下Qwen1.5-14B-Chat,因此用两块3090使用lmdeploy部署,测试结果如下,同样的请求Ascend 310P芯片响应时长≈10s,而3090耗时≈1.5s。



















 2217
2217







 到【灌水乐园】发言
到【灌水乐园】发言







