






基于 RAG 的智能写作系统实现
我是deepMan,毕业于985高校,拥有丰富的大厂工作经验,现任独立开发者公司负责人。
长期专注于技术创新,精通人工智能和区块链技术,具备丰富的项目开发和管理经验,
擅长从0到1构建高质量技术解决方案,致力于推动技术在实际场景中的应用落地。
获取源码与答疑解惑,添加小助手微信,进行业交流群,一起抱团,开拓新赛道,获取新财富机会。
关注更多有意思的内容访问历史文章:答疑与更多源码
系统架构
-
文档处理模块 (DocumentProcessor)
- 支持 PDF 和 Markdown 文件加载
- 使用 RecursiveCharacterTextSplitter 进行文本分割
- 针对中文优化的分隔符设置
-
RAG 系统核心 (RAGSystem)
- 使用 shaw/dmeta-embedding-zh 进行文本向量化
- 使用 qwq 模型进行文本生成
- 基于 Chroma 的向量数据库存储
-
内容生成器 (ContentGenerator)
- 写作风格分析
- 主题提取
- 文章生成
- 自动保存功能
工作流程
1. 文档学习阶段
2. 写作风格分析
- 分析样本文档的句式结构
- 提取段落组织方式
- 识别用词特点
- 总结行文逻辑
3. 文章生成过程
-
大纲生成
outline_prompt = """基于标题"{title}",请生成一个详细的文章大纲, 要求: 1. 符合文档库中的专业领域知识 2. 包含3-5个主要部分 3. 每个部分2-3个子要点 """ -
内容生成
article_prompt = """请基于以下大纲和已学习的文档风格,撰写一篇完整的文章: 标题:{title} 大纲:{outline} 要求: 1. 符合原有文档的专业性和准确性 2. 保持一致的写作风格 3. 字数不少于{min_words}字 4. 注意段落之间的连贯性 """ -
文章保存格式
# 文章标题 ## 大纲 [自动生成的大纲内容] ## 正文 [生成的文章内容] --- 生成时间:[时间戳]
使用示例
import os
from typing import List, Dict
import json
from datetime import datetime
import random
from pathlib import Path
from langchain_community.document_loaders import DirectoryLoader, PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
from langchain.docstore.document import Document
from langchain_ollama import OllamaEmbeddings, OllamaLLM
import time
from tqdm import tqdm
import asyncio
from concurrent.futures import ThreadPoolExecutor
class DocumentProcessor:
def __init__(self):
# 初始化文本分割器
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
length_function=len,
separators=["\n\n", "\n", "。", "!", "?", ".", " ", ""]
)
def load_documents(self, directory_path: str) -> List[Document]:
"""加载指定目录下的 PDF 和 Markdown 文件"""
documents = []
# 加载 PDF 文件
pdf_loader = DirectoryLoader(
directory_path,
glob="**/*.pdf",
loader_cls=PyPDFLoader # type: ignore
)
# 加载 Markdown 文件
markdown_loader = DirectoryLoader(
directory_path,
glob="**/*.md"
)
try:
pdf_docs = pdf_loader.load()
documents.extend(pdf_docs)
print(f"已加载 {len(pdf_docs)} 个 PDF 文件")
except Exception as e:
print(f"加载 PDF 文件时出错: {str(e)}")
try:
md_docs = markdown_loader.load()
documents.extend(md_docs)
print(f"已加载 {len(md_docs)} 个 Markdown 文件")
except Exception as e:
print(f"加载 Markdown 文件时出错: {str(e)}")
return documents
def split_documents(self, documents: List[Document]) -> List[Document]:
"""将文档分割成小块"""
return self.text_splitter.split_documents(documents)
class RAGSystem:
def __init__(self, persist_directory: str = "./chroma_db"):
self.persist_directory = persist_directory
# 使用新的 OllamaEmbeddings
self.embeddings = OllamaEmbeddings(
model="shaw/dmeta-embedding-zh",
base_url="http://localhost:11434"
)
# 使用新的 OllamaLLM 替代 Ollama
self.llm = OllamaLLM(
model="llama3:latest",
base_url="http://localhost:11434"
)
def create_vectorstore(self, documents: List[Document]) -> Chroma:
"""创建向量数据库"""
return Chroma.from_documents(
documents=documents,
embedding=self.embeddings,
persist_directory=self.persist_directory
)
def create_qa_chain(self, vectorstore: Chroma) -> ConversationalRetrievalChain:
"""创建问答链"""
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True,
output_key="answer"
)
return ConversationalRetrievalChain.from_llm(
llm=self.llm,
retriever=vectorstore.as_retriever(
search_kwargs={"k": 3} # 检索最相关的3个文档片段
),
memory=memory,
return_source_documents=True # 返回源文档信息
)
class ContentGenerator:
def __init__(self, qa_chain, vectorstore):
self.qa_chain = qa_chain
self.vectorstore = vectorstore
self.style_patterns = []
self.learned_topics = set()
def analyze_writing_style(self, documents: List[Document]):
"""分析文档的写作风格"""
style_prompt = """分析这段文本的写作风格特点,包括:
1. 常用句式
2. 段落结构
3. 用词特点
4. 行文逻辑
请简要总结。
文本内容:{text}
"""
sample_size = min(5, len(documents))
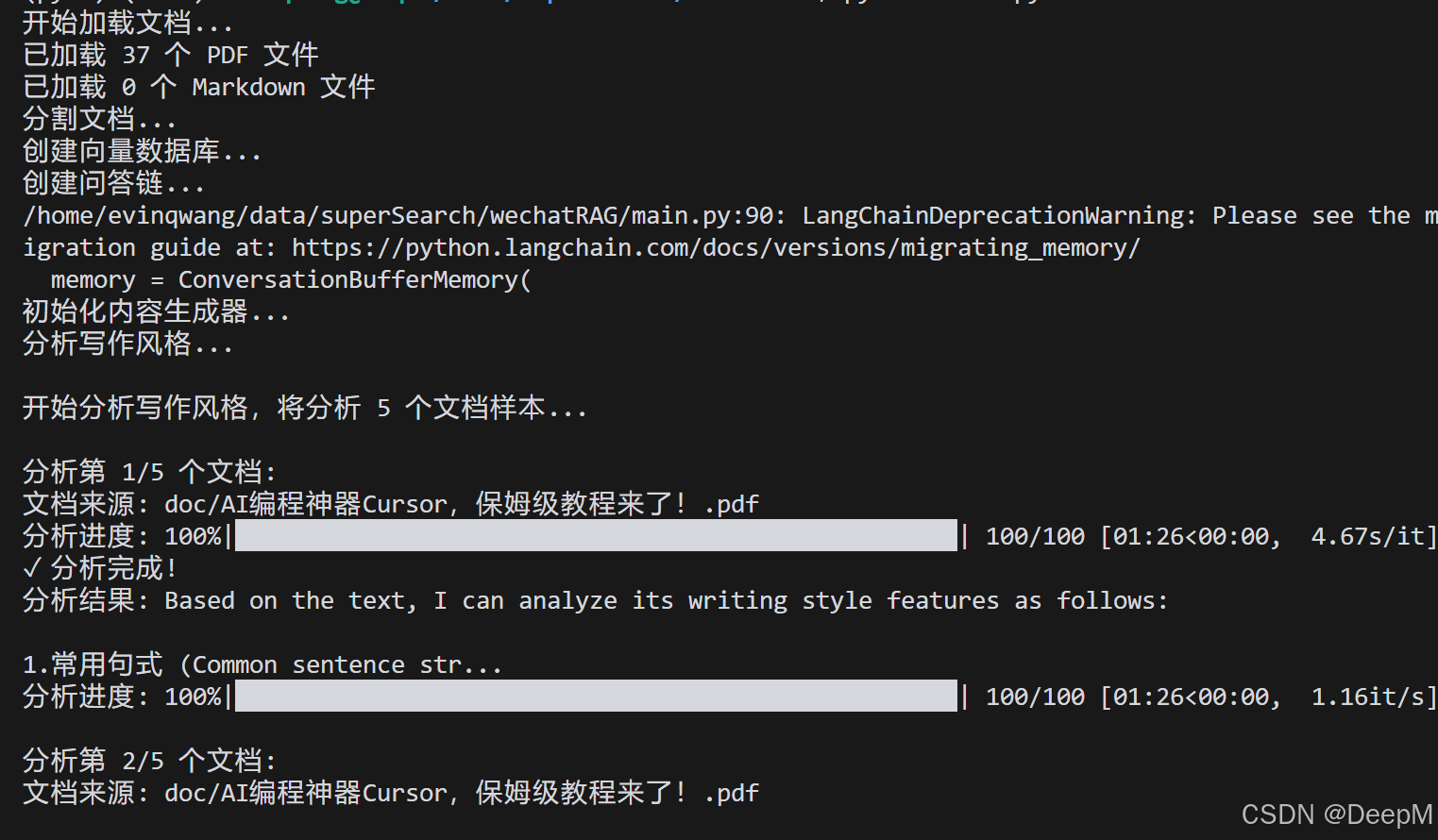
print(f"\n开始分析写作风格,将分析 {sample_size} 个文档样本...")
for i, doc in enumerate(documents[:sample_size], 1):
print(f"\n分析第 {i}/{sample_size} 个文档:")
print(f"文档来源: {doc.metadata.get('source', '未知来源')}")
# 添加进度条和超时处理
with tqdm(total=100, desc="分析进度", ncols=100) as pbar:
try:
# 创建定时更新进度的函数
def update_progress():
progress = 0
while progress < 95:
time.sleep(0.5)
step = min(5, 95 - progress)
progress += step
pbar.update(step)
# 在后台线程中更新进度
with ThreadPoolExecutor() as executor:
future = executor.submit(update_progress)
# 设置超时时间为60秒
response = self.qa_chain.invoke({
"question": style_prompt.format(text=doc.page_content)
})
# 完成进度条
pbar.update(100 - pbar.n)
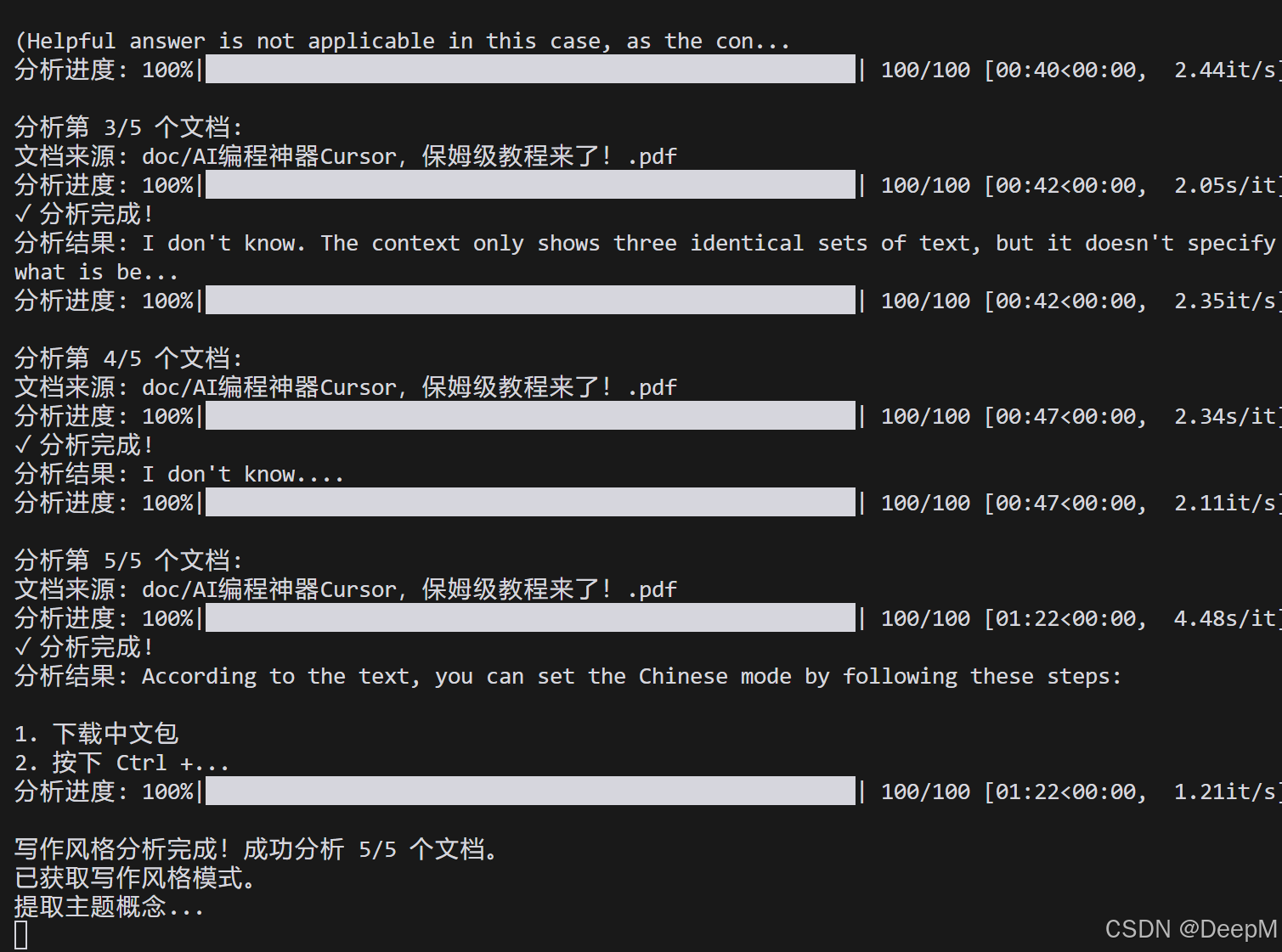
print("✓ 分析完成!")
print(f"分析结果: {response['answer'][:100]}...")
self.style_patterns.append(response["answer"])
except Exception as e:
print(f"\n❌ 分析失败: {str(e)}")
continue
successful_patterns = len(self.style_patterns)
print(f"\n写作风格分析完成!成功分析 {successful_patterns}/{sample_size} 个文档。")
if successful_patterns > 0:
print("已获取写作风格模式。")
else:
print("警告:未能成功分析任何文档的写作风格。")
def extract_topics(self, documents: List[Document]):
"""提取文档中的主题"""
topic_prompt = "请从以下文本中提取主要主题和关键概念:{text}"
for doc in documents:
response = self.qa_chain.invoke({
"question": topic_prompt.format(text=doc.page_content)
})
# 解析响应中的主题
topics = self._parse_topics(response["answer"])
self.learned_topics.update(topics)
def _parse_topics(self, text: str) -> set:
"""从文本中解析主题"""
# 这里可以使用更复杂的主题提取算法
words = text.replace(',', ',').replace('。', '.').split()
return set(word for word in words if len(word) > 1)
def generate_article(self, title: str, min_words: int = 800) -> Dict:
"""根据标题生成文章"""
# 构建文章大纲
outline_prompt = f"""基于标题"{title}",请生成一个详细的文章大纲,
要求:
1. 符合文档库中的专业领域知识
2. 包含3-5个主要部分
3. 每个部分2-3个子要点
"""
outline_response = self.qa_chain.invoke({"question": outline_prompt})
outline = outline_response["answer"]
# 根据大纲生成文章
article_prompt = f"""请基于以下大纲和已学习的文档风格,撰写一篇完整的文章:
标题:{title}
大纲:{outline}
要求:
1. 符合原有文档的专业性和准确性
2. 保持一致的写作风格
3. 字数不少于{min_words}字
4. 注意段落之间的连贯性
"""
article_response = self.qa_chain.invoke({"question": article_prompt})
return {
"title": title,
"outline": outline,
"content": article_response["answer"],
"timestamp": datetime.now().isoformat(),
"reference_style": random.choice(self.style_patterns)
}
def save_article(self, article: Dict, output_dir: str = "generated_articles"):
"""保存生成的文章"""
Path(output_dir).mkdir(exist_ok=True)
filename = f"{article['title']}_{datetime.now().strftime('%Y%m%d_%H%M%S')}.md"
filepath = os.path.join(output_dir, filename)
with open(filepath, 'w', encoding='utf-8') as f:
f.write(f"# {article['title']}\n\n")
f.write(f"## 大纲\n\n{article['outline']}\n\n")
f.write(f"## 正文\n\n{article['content']}\n\n")
f.write(f"\n---\n生成时间:{article['timestamp']}")
class AutoLearningSystem:
def __init__(self, doc_processor: DocumentProcessor, rag_system: RAGSystem):
self.doc_processor = doc_processor
self.rag_system = rag_system
self.content_generator = None
def learn_documents(self, directory_path: str):
"""自动学习文档内容"""
print("开始加载文档...")
documents = self.doc_processor.load_documents(directory_path)
if not documents:
raise ValueError("未找到任何文档")
print("分割文档...")
splits = self.doc_processor.split_documents(documents)
print("创建向量数据库...")
vectorstore = self.rag_system.create_vectorstore(splits)
print("创建问答链...")
qa_chain = self.rag_system.create_qa_chain(vectorstore)
print("初始化内容生成器...")
self.content_generator = ContentGenerator(qa_chain, vectorstore)
print("分析写作风格...")
self.content_generator.analyze_writing_style(splits)
print("提取主题概念...")
self.content_generator.extract_topics(splits)
print("学习完成!")
return self.content_generator
def generate_articles(self, titles: List[str], output_dir: str = "generated_articles"):
"""批量生成文章"""
if not self.content_generator:
raise ValueError("请先调用 learn_documents 进行学习")
generated_articles = []
for title in titles:
print(f"正在生成文章:{title}")
article = self.content_generator.generate_article(title)
self.content_generator.save_article(article, output_dir)
generated_articles.append(article)
return generated_articles
def main():
# 初始化系统
doc_processor = DocumentProcessor()
rag_system = RAGSystem()
auto_learning = AutoLearningSystem(doc_processor, rag_system)
# 指定文档目录
directory_path = "./doc"
try:
# 自动学习文档
content_generator = auto_learning.learn_documents(directory_path)
# 示例:生成一些文章
titles = [
"人工智能在医疗领域的应用前景",
"数字化转型对企业的影响",
"可持续发展与绿色能源的未来"
]
generated_articles = auto_learning.generate_articles(titles)
print(f"\n成功生成 {len(generated_articles)} 篇文章!")
print("文章已保存到 generated_articles 目录")
except Exception as e:
print(f"处理过程中出错: {str(e)}")
if __name__ == "__main__":
main()

















 4938
4938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









