






写在前面
本章主要介绍FLink的框架结构、四层模型、编写一个FLink程序的基本步骤。后续今会在本节基础上由浅入深展开学习。
1.Flink简介
Stateful Computations over Data Streams
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
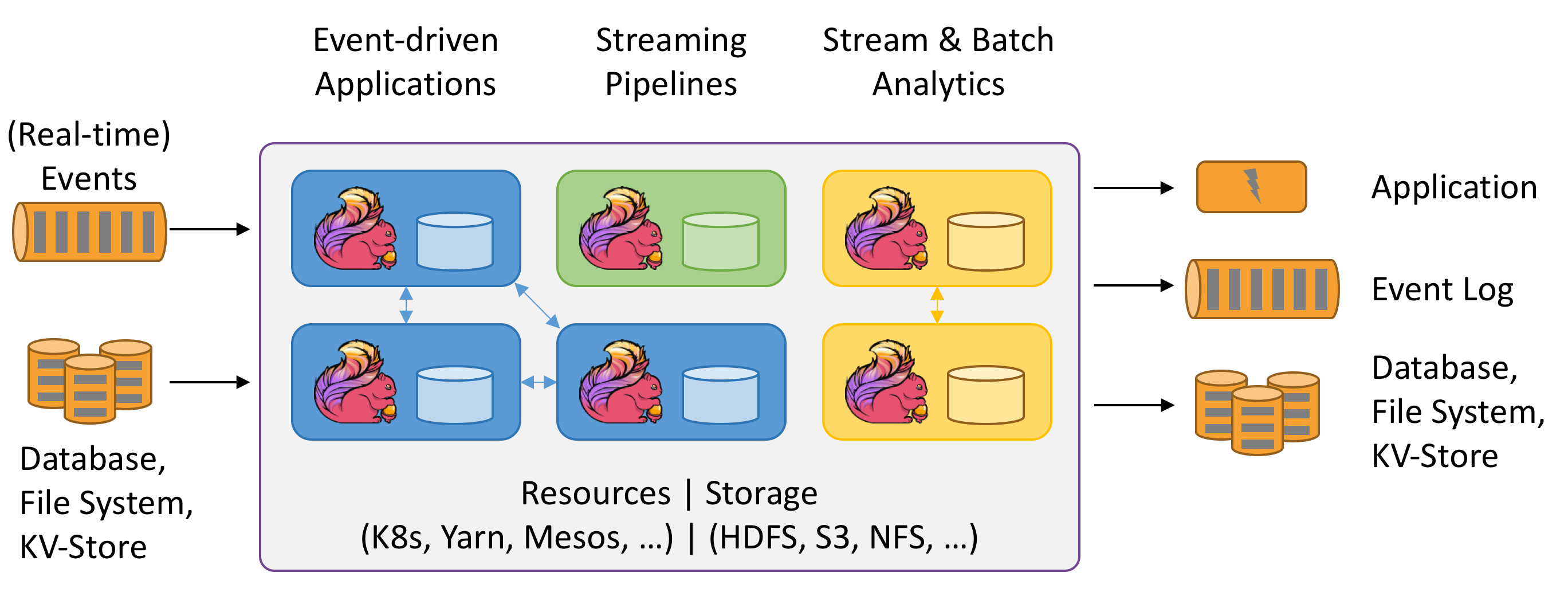
2.Flink架构图
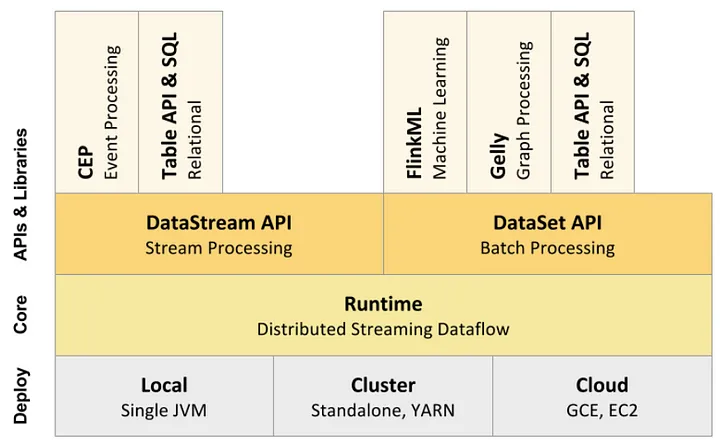
3.Flink四层模型
Flink代码的开发过程本质上就是构建一个Dataflow,Dataflow的运行需要经历如下4个阶段:
- StreamGraph:根据用户编写的Stream API而生成的最初的作业拓扑图,表示程序的拓扑结构。
- JobGraph:StreamGraph会经过作业链优化生成JobGraph,提交给 JobManager 的数据结构。主要的优化为,将并行度相同且流传输模式为one-to-one的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗。
- ExecutionGraph:JobManager 根据 JobGraph 生成ExecutionGraph,是JobGraph的并行化版本,是调度层最核心的数据结构。
- 物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
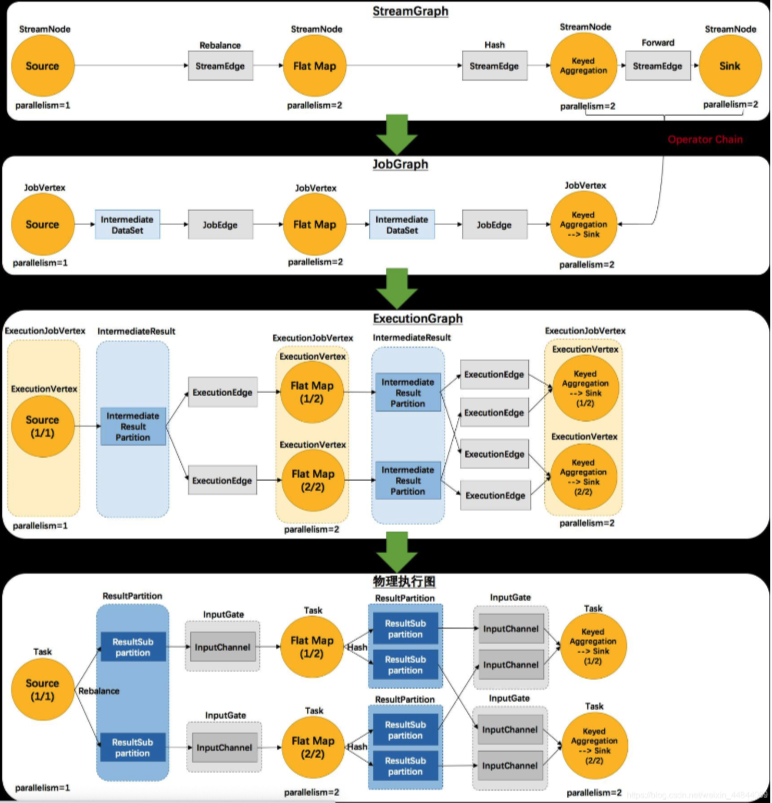
4.Flink脚本结构
- 设置环境变量
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
- 获取数据数据
DataStreamSource<String> data = env.socketTextStream("localhost",9999);
- 转化算子
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = data.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] fields = line.split(",");
for (String word : fields) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> result = wordAndOne.keyBy(0).sum(1);
- 数据输出
result.print();
- 执行程序
env.execute("");
DataFlow

output
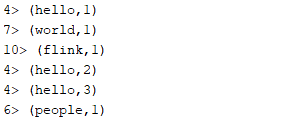


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









