







概率图模型
隐马尔可夫模型
机器学习最重要的任务,是根据一些已观察到的证据(例如训练样本)来对感兴趣的未知变量(例如类别标记)进行估计和推测。概率模型提供了一种描述框架,将学习任务归结于计算变量的概率分布。在概率模型中,利用已知变量推测未知变量的分布称为“推断”,其核心是如何基于可观测变量推测出未知变量的条件分布。具体来说,假定所关心的变量集合为Y,可观测变量集合为O,其他变量的集合为R,“生成式”模型考虑联合分布P(Y,R,O),“判别式”模型考虑条件分布P(Y,R|O)。戈丁一组观测变量值,推断就是要由P(Y,R,O)或P(Y,R|O)得到条件概率分布P(Y|O)。
概率图模型是一类用图来表达变量相关关系的概率模型。它以图为表示工具,最常见的是用一个结点表示一个或一组随机变量,结点之间的边表示变量间的概率相关关系,即“变量关系图”。根据边的性质不同,概率图模型可大致分为两类:(1)使用有向无环图表示变量间的依赖关系,称为有向图模型或贝叶斯网;(2)使用无向图表示变量间的相关关系,称为无向图模型或马尔可夫网。
隐马尔可夫模型(简称HMM)是结构最简单的动态贝叶斯网,这是一种著名的有向图模型,主要用于时序数据建模,在语音识别、自然语言处理等领域有广泛应用。
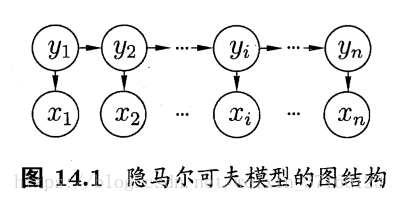
上图第一排是状态变量,yi表示第i时刻的系统状态。通常假定状态变量是隐藏的、不可被观测的,因此状态变量亦称隐变量。第二排是观测变量,xi表示第i时刻的观测值。同时,箭头表示了变量间的依赖关系,在任一时刻,观测变量的取值仅依赖于状态变量。同样的,t时刻的状态yt仅依赖于t-1时刻的状态y(t-1),与其余的状态无关,这就是所谓的“马尔可夫链”。基于这种依赖关系,所有变量的联合概率分布为
马尔可夫随机场
马尔可夫随机场(简称MRF)是典型的马尔可夫网,这是一种著名是无向图模型。图中每个结点表示一个或一组变量,结点之间的边表示两个变量之间的依赖关系。马尔可夫随机场有一组势函数,亦称“因子”,这是定义在变量子集上的非负实函数,主要用于定义概率分布函数。
上图显示出一个简单的马尔可夫随机场。对于图中结点的每一个子集,若其中任意两结点间都有边连接,则称该结点子集为一个“团”。若在一个团中加入另外任何一个结点都不在形成团,则称该团委“极大团”。

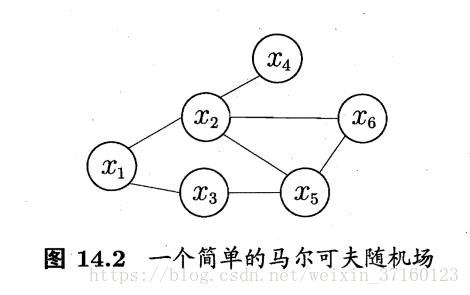
在马尔可夫随机场中如何得到“条件独立性”呢?同样借助“分离”概念,若从结点集A中的结点到B中的结点都必须经过结点集C中的结点,则称结点集A和B被结点集C分离,C称为“分离集”。
条件随机场
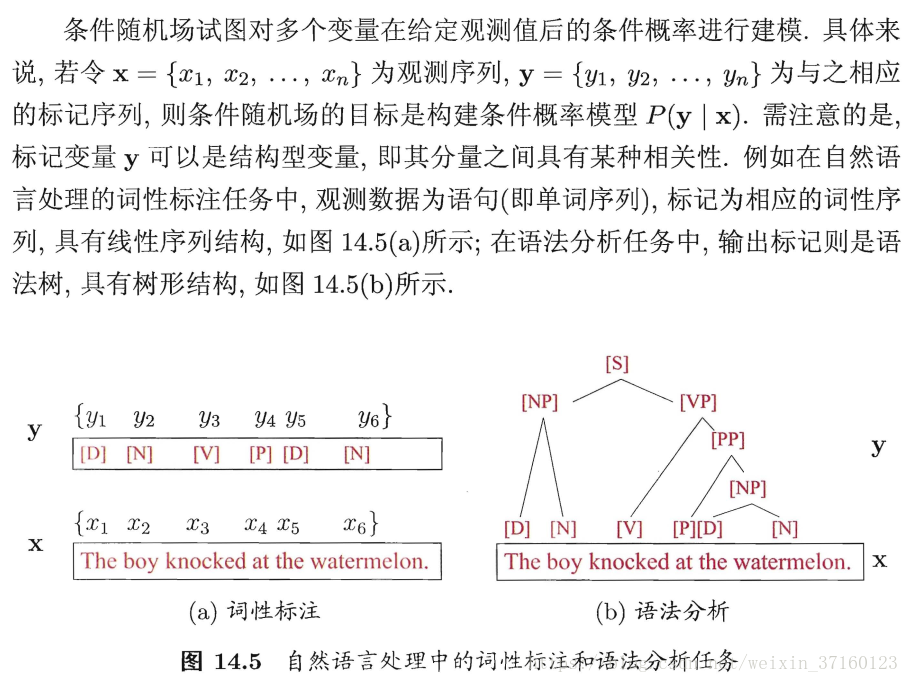
条件随机场(简称CRF)是一种判别式无向图模型,而判别式模型是对条件分布进行建模。上面两种均是生成式模型,而条件随机场则是判别式模型。

















 3361
3361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









