







垃圾对象
在Java里面,什么样的对象,是垃圾对象呢?通俗来讲,就是没有任何引用指向的对象,即为垃圾对象,在内存中占着空间,但是没有任何引用会引用到它。
Java中有专门的GC(垃圾收集器)来处理垃圾,一般情况下,开发人员不需要特别关注垃圾对象的处理。
识别垃圾
现在清楚了什么是垃圾对象,那GC又是如何判断这个对象是否是垃圾呢?一般有两种方式判别:引用计数法和可达性分析法
引用计数(reference count)
见名知意,对象有一个引用关联,则记数量+1
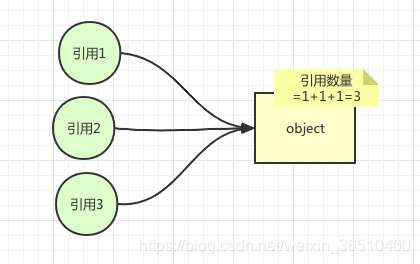
如图,现在有一个object对象,同时有三个引用指向这个object,其引用数量为3。每当释放一个引用之后,引用数量依次-1,当引用数量减为0时,此时该object即可被认为是垃圾对象,可以进行销毁。
这种方式比较简单,效率也会很高,但是一旦出现对象间循环引用时,对象将无法回收
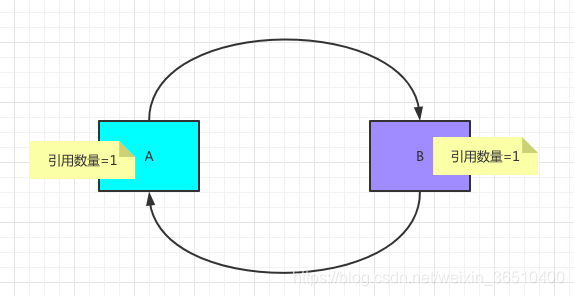
当对象A持有对象B的引用,同时对象B也持有对象A的引用,这种情况下,对象A的引用数量为1,对象B的引用数量也为1,这两个对象循环依赖之后,形成了孤岛,出了这个孤岛,外部再无任何引用能找到它们,根据引用计数规则,它们不属于垃圾对象,从而无法被回收。
可达性分析(root searching)
root search,即为从root对象开始搜索,如果最终能找到这个对象,则该对象不是垃圾:
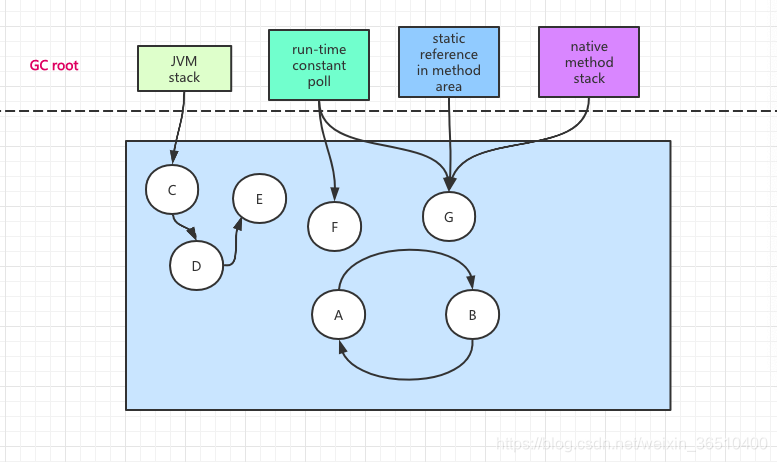
如图所示,从root节点出发,最终可以找到的对象有CDEFG,而对象A和B,从root节点出发没有任何一条路径可以找到它们,虽然它们之间相互依赖,各自引用数量不为0,但依然会判定它们为垃圾对象。
root节点
那什么样的节点可以作为root节点对象呢?根据JVM规范,有以下几种对象可以作为root节点:
-
线程栈变量(JVM stack)
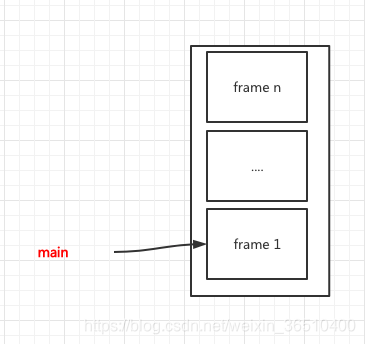
Java栈中会有很多的栈帧,main方法所在栈帧里的各种变量即可作为root对象,也即图中frame1中的变量对象 -
静态变量(static reference in method area)
所有Class文件中定义的静态变量,没啥好解释的 -
常量池(run-time constant poll)
这也没啥好解释的 -
本地方法栈(native method stack)
如果调用了本地由C/C++写的本地方法,那些方法中的对象也可认为是root对象
垃圾清除
ok,现在GC已经找到哪些对象时垃圾了,该如何进行清除呢?
常用的垃圾清除算法有下面3种:
- 标记清除(mark-sweep)
- 拷贝(copy)
- 标记压缩(mark-compact)
下面我们简单介绍下这几种算法的优缺点
我们以一个方块代表一个对象,黑色表示是垃圾对象,绿色表示是正常非垃圾对象,白色表示是内存空闲区域:
标记清除
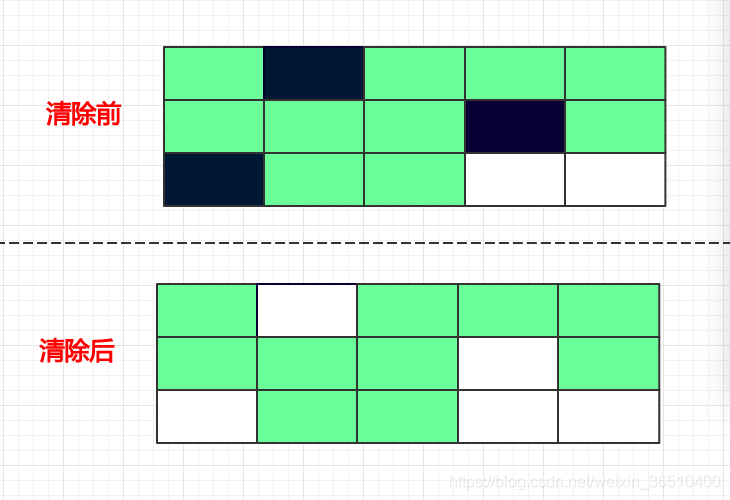
标记清除算法的逻辑很简单,即先将垃圾对象标记出来,然后再直接将被标记的对象清除。
通过上面的介绍,标记-清除算法,需要经过两遍扫描,第一遍先标记出所有的垃圾对象,第二遍扫描,是将第一遍标记出的对象清除。但是直接将对象清除之后,原对象占用的空间很有可能是不连续的,如图中黑色所示,分散在内存中各处,会造成内存中可用空间是断断续续的,碎片化比较严重。
该算法的优点是,算法相对比较简单,当垃圾对象比较少时,需要执行的动作较少,此时的效率最高。
缺点是极容易造成内存空间碎片化
拷贝
为了解决垃圾清除完后碎片化严重的问题,拷贝算法便孕育而生:
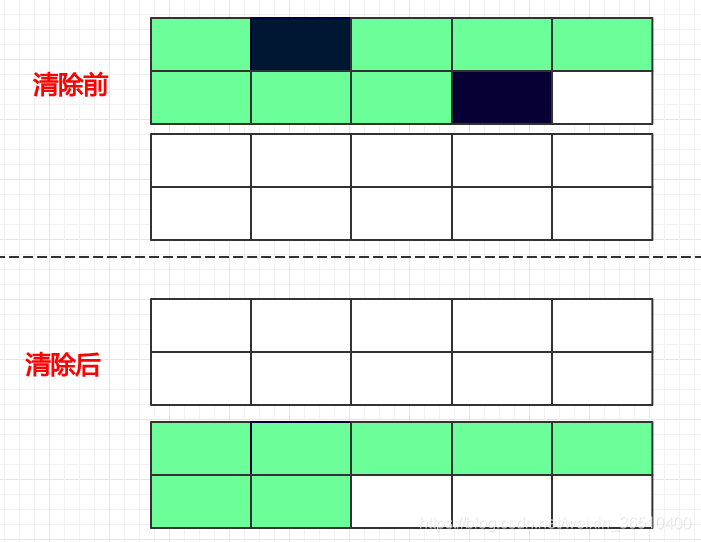
需要将内存空间一分为二,每次只用一半的空间。当需要清理垃圾时,将内存A中不是垃圾的对象,copy到另一半的内存空间B中,然后再将内存A中的所有对象全部清空。
这样的好处还是很明显的:
1)解决了碎片化问题,所有存活的对象,在内存B中的排列都是有序的,内存中剩余的可用空间也都是连续的
2)过程只经历了一次扫描
同样缺点也是很明显的:
1)内存空间浪费很严重,人为将内存空间缩减了一半
2)因内存中的存活对象经历了一次挪动,从内存A挪移到了内存B中,其内存地址必然发生变动,需要在挪动对象的同时修改该对象的所有引用指向的地址,当存活对象很多时,会很大程度降低该算法的效率
所以该算法,在存活对象比较少时,执行效率会比较高。
标记-压缩
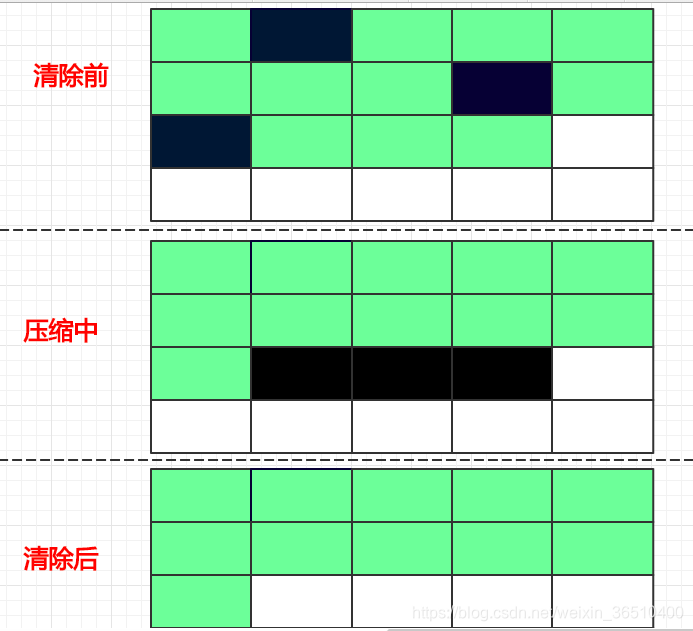
综合了标记-清除算法 和拷贝算法的优缺点,需要扫描两次,第一次扫描将所有内存中存活的非垃圾对象挪到连续的空间,第二次扫描将垃圾对象清除
该算法的优缺点一样很明显:
优点:
1)不会产生碎片化
2)内存大小不用人为缩减一半
缺点:
1)扫描2次
2)需要挪动对象,也会涉及对象引用的调整
效率低
GC种类
Java中有哪几种GC呢?先简单列举一下:
- Serial GC
- ParNew GC
- Parrallel GC
- CMS GC
- G1 GC
- ZGC(JDK11)
内存分代
逻辑分代:内存中不实际切割物理空间,只是在逻辑上标识这块空间是新生代,这块空间是老年代,但是对应的内存空间是统一连续的一块。
物理分代:物理切割内存空间,新生代,老年代分别对应着独立的两块不同的内存区域。
除ZGC外,都使用逻辑分代模型
G1是逻辑分代,物理部不分代
其他既逻辑分代,也物理分代
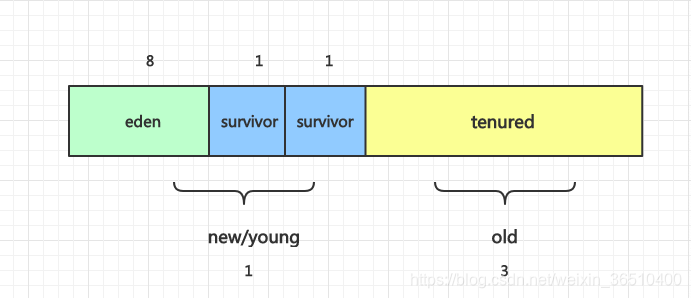
新生代:
包含两块区域,eden(伊甸园区)和两个survivor区,一般默认比例是8:1:1
- eden区,我们new出来的对象,会落在eden区,eden区大量对象产生,同时有大量对象被回收
- survivor区,当eden区回收之后,对象还存活着,对象则会进入survivor区中的一个,(另一个survivor始终处于空闲状态),survivor区每次发生GC,对象则会在survivor1和survivor2之间来回copy切换(如果对象始终存活),在对象被回收到一定年龄之后,对象进入老年代。
对象每被回收一次,年龄+1,最大年龄可达15次,也即对象被回收15次之后还存活,则对象会进入老年代。
当出发young GC,需要将eden中存活对象和survivor1对象copy进survivor2,如果eden中存活对象数量+survivor1中存活对象的数量 > survivor2大小的一半时,survivor中年龄大的对象也会直接进入老年代。
按照前面所讲的GC回收算法,eden区用的是标记清除算法,survivor使用的是copy算法,老年代则可以是标记清除算法,或者是标记压缩算法
Minor GC / YGC / Young GC : 新生代空间耗尽时触发
Major GC/Full GC :老年代空间耗尽时触发,此时新生代和老年代会同时进行回收
对象生命流转
我们在程序中new了一个对象,JVM是怎么分配这个对象的呢?
相信很多人都记得new的对象在堆上分配内存,在栈上分配引用,一定是这样吗?
其实并不完全是。
我们new出来的对象,可可能是直接分配在线程栈上,随着出栈操作直接消亡,而不需要经过垃圾回收处理。
所以对象的分配,优先在线程栈上分配,如果不满足分配条件,则优先线程本地分配(TLAB),如果还是不满足,则分配进eden区,如果是大对象,则直接分配进老年代。
分配规则简单来讲如下:
- 栈上分配规则:
- 线程私有,对象很小
- 无逃逸(即对象生命周期仅在此栈上,出了栈无任何引用)
- 支持标量替换(如对象仅有一个id字段,则只需要对id字段的值进行入栈和出栈操作,其等同于创建对象(id字段入栈),销毁对象(id字段出栈))
- 线程本地分配 TLAB(thread local allocation buffer)
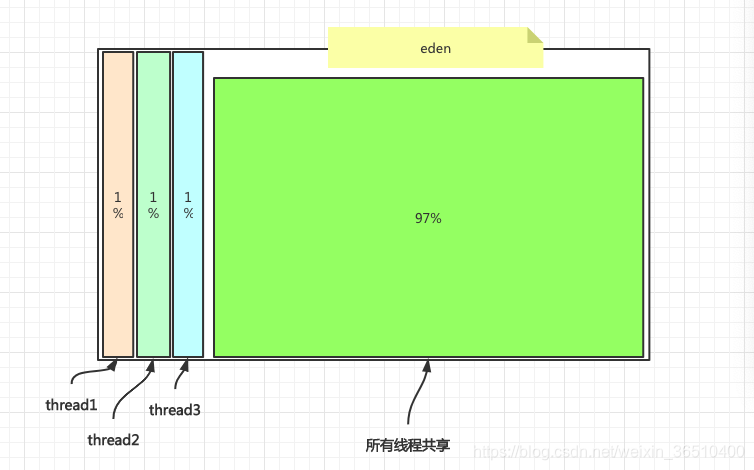
每个线程都会占用eden区,默认1%的空间。 当线程new对象之后,在栈上无法分配空间,则优先在eden区独占空间上进行分配,这样多线程环境下,线程无需在eden剩余区域进行空间竞争,一般分配的也是小对象。

















 770
770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









