







简介:JSON数据格式在IT行业中广泛应用,本话题探讨如何使用JavaScript高效地处理JSON数据并构建树形结构。JSON对象的parse()方法能够将JSON字符串转换为JavaScript对象。构建树形结构需要对解析后的数据进行特定处理,如建立父子节点关系。针对大数据量的树形结构,采用优化策略如延迟加载或分页加载可以提高加载速度。同时,本压缩包含有多个关键组件,如样式表、HTML示例页面和JavaScript文件,它们共同提供了一个完整的解决方案,以高效加载和展示树形结构数据。
1. JSON数据格式应用与解析
在当今的IT领域,数据交换和存储的便捷性至关重要。JSON(JavaScript Object Notation)作为一种轻量级的数据交换格式,因其简洁的结构、易读性和跨语言的特性而广泛应用于Web开发中。
1.1 JSON数据格式简介
1.1.1 JSON的基本结构和组成
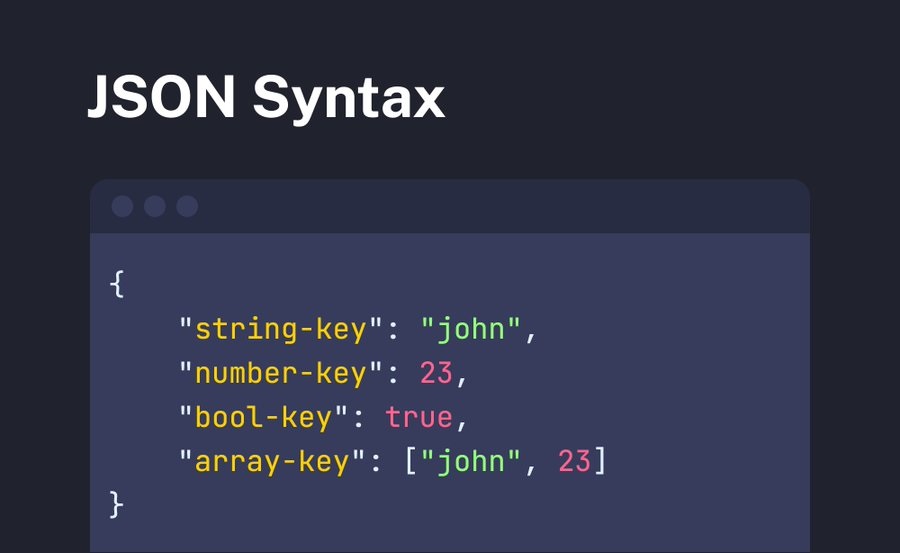
JSON数据格式支持两种类型的结构:对象(Object)和数组(Array)。一个对象是由一系列无序的键值对组成,用大括号 {} 包围;而数组则是由一系列有序的值组成,用中括号 [] 包围。每个键值对由一个冒号 : 分隔,值可以是字符串、数字、布尔值、数组、对象或 null 。
示例代码块:
{
"name": "John Doe",
"age": 30,
"isStudent": false,
"courses": ["Math", "Science"],
"address": {
"street": "123 Main St",
"city": "Anytown"
}
}
1.1.2 JSON数据类型的详细介绍
JSON支持以下数据类型:
- 字符串(String):用双引号括起来的字符序列。
- 数字(Number):不带引号的数字序列。
- 布尔值(Boolean): true 或 false 。
- 数组(Array):由方括号括起来,内部可以包含不同类型的值。
- 对象(Object):用大括号括起来的一系列键值对。
- null:表示一个空值。
1.2 JSON解析技术
1.2.1 解析JSON数据的重要性
JSON解析是将JSON格式的数据转换为编程语言中可以操作的数据结构的过程。解析的重要性在于它能将网络传输中的文本信息转换为程序能理解和处理的数据对象。在前端JavaScript开发中,这通常是处理服务器响应数据的第一步。
1.2.2 常见的JSON解析方法和工具
解析JSON的常见方法包括使用内置的 JSON.parse() 函数将JSON字符串转换为JavaScript对象,以及 JSON.stringify() 将对象转换回字符串形式。现代开发工具如Postman,在测试API时提供了内置的JSON解析器,简化了开发者的调试过程。
1.2.3 解析过程中的常见问题及解决方案
解析过程中可能会遇到格式不正确的JSON或数据类型错误,常见的解决方案包括使用try-catch错误处理机制捕获解析错误,并进行相应的错误提示和处理。在JavaScript中,可以使用 try...catch 来处理潜在的解析错误。
示例代码块:
try {
const obj = JSON.parse(jsonString);
// 使用解析得到的对象
} catch (e) {
console.error('解析JSON时出错:', e);
}
通过上述内容,本章为读者提供了一个JSON数据格式的基础介绍,并探讨了如何在实际应用中解析JSON数据。随后章节将继续深化,讨论树形结构构建与节点关系建立、数据加载策略优化、项目文件分析以及树形数据展示的高效实现和优化。
2. 树形结构构建与节点关系建立
2.1 树形数据结构概念
2.1.1 树形结构的特点和应用场景
树形数据结构是一种重要的非线性数据结构,它模拟了自然界中树木的分支结构,用于表示具有层次关系的数据。在计算机科学中,树由节点(Node)和边(Edge)组成,一个节点可以有多个子节点,但只有一个父节点,除了根节点外。根节点没有父节点。
树形结构的特点包括:
- 层级性 :树形结构中的节点具有清晰的层级关系,非常适合表示具有层次的组织信息。
- 单向关系 :节点间通常通过单向链接(边)相连接,这种单向性使得树结构易于管理。
- 唯一性 :从根节点到任何一个节点,都有且仅有一条路径,保证了数据的唯一访问路径。
树形结构的应用场景十分广泛,包括但不限于:
- 文件系统的目录结构
- HTML DOM结构
- 组织架构图
- 抽象语法树(AST)在编译器中的应用
- 数据库索引结构
2.1.2 树形结构与其它数据结构的对比
与其他数据结构相比,树形结构的优势在于其高效的层级关系处理能力。与数组、链表等线性结构相比,树结构在处理排序、查找、插入和删除操作时,能提供更优的时间复杂度。例如,在一个平衡二叉搜索树中,查找、插入和删除操作的时间复杂度可以达到O(log n),这在排序要求较高的场景中非常有用。
此外,树形结构与图结构也有显著不同。图可以表示任意复杂的非线性关系,而树则是图的一个特殊子集,只允许有一个入边(除了根节点),这使得树形结构在某些算法设计上更为简单和高效。
2.2 树节点的创建与关系维护
2.2.1 节点的定义和属性设置
在树形数据结构中,每一个独立的数据单元都被称为一个节点。一个节点通常包含以下几种属性:
- 数据:节点存储的数据内容。
- 子节点列表:指向其子节点的引用或指针集合。
- 父节点引用:指向其父节点的引用或指针。
- 深度(Level):节点在树中的层级位置。
- 广度(Position):节点在兄弟节点中的相对位置。
在代码层面,我们可以定义一个节点类(Node class),用以实现上述属性和功能。以下是使用JavaScript实现一个简单的树节点类示例:
class TreeNode {
constructor(data) {
this.data = data; // 存储数据
this.children = []; // 子节点列表
}
addChild(childNode) {
// 添加子节点方法
childNode.parent = this; // 设置子节点的父节点引用
this.children.push(childNode); // 将子节点添加到子节点列表中
}
removeChild(childNode) {
// 移除子节点方法
this.children = this.children.filter(node => node !== childNode);
childNode.parent = null;
}
}
2.2.2 节点间关系的建立和优化策略
节点间关系的建立通常涉及对子节点的添加和删除操作。在实际应用中,需要注意节点间关系的正确性和完整性。例如,在添加子节点时,不仅要将其添加到父节点的子节点列表中,还要更新子节点的父节点引用。
为了保证树形结构的正确性,我们可以在每个节点类中添加方法来维护节点间的引用,如上例中的 addChild 和 removeChild 方法。同时,可以引入一些优化策略,例如:
- 空间优化 :使用稀疏数组或者哈希表来存储节点间的关系,减少存储空间的使用。
- 时间优化 :在进行节点操作时,尽量减少遍历的次数,使用缓存机制来提高效率。
- 完整性检查 :在每次节点操作后,检查树的完整性和约束条件,如是否保持了平衡树的特性。
2.2.3 树的遍历算法及其效率分析
树的遍历算法是树操作中最基础也是最重要的技术之一。常见的遍历方式包括前序遍历、中序遍历和后序遍历,每种遍历方法都有其特定的应用场景。
前序遍历(Pre-order Traversal):
- 先访问根节点,然后递归地对子树进行前序遍历。
- 用于复制整个树结构、输出树的内容等。
中序遍历(In-order Traversal):
- 先递归地对左子树进行中序遍历,访问根节点,再递归地对右子树进行中序遍历。
- 用于获取排序好的树节点数据,如二叉搜索树中。
后序遍历(Post-order Traversal):
- 先递归地对子树进行后序遍历,然后访问根节点。
- 用于删除树结构,释放资源。
以下是一个递归实现的前序遍历示例代码:
function preOrderTraversal(node, visit) {
if (node === null) return; // 空节点直接返回
visit(node); // 访问当前节点
for (let child of node.children) {
preOrderTraversal(child, visit); // 递归遍历子节点
}
}
// 使用方法
preOrderTraversal(rootNode, (node) => console.log(node.data));
遍历算法的效率分析:
- 时间复杂度:O(n),其中n是树中节点的数量。每个节点都会被访问一次。
- 空间复杂度:取决于树的深度。在最坏的情况下(树退化为链表时),空间复杂度为O(n)。如果使用尾递归优化或迭代实现,空间复杂度可降低到O(log n),这在平衡树中是典型的。
通过上述分析,我们可以看出,树形结构的构建和节点关系的维护不仅需要考虑数据结构本身,还要考虑算法的效率和优化。在实际开发中,根据不同的应用场景选择合适的遍历算法和优化策略,能够显著提升程序的性能和效率。
3. 加载策略优化:延迟加载和分页加载
随着互联网技术的发展,数据量的不断增长和用户对网页性能的要求也随之提升。在这样的背景下,加载策略的优化显得尤为重要。本章将着重探讨延迟加载和分页加载的实现方法、优势以及它们在实际应用中的案例分析。
3.1 延迟加载技术
3.1.1 延迟加载的概念和优势
延迟加载(Lazy Loading)是一种性能优化策略,旨在将页面上非首屏的资源的加载推迟到用户需要查看时才进行加载。这种策略的主要目的是减少初始页面加载所需时间,提升用户体验,并且减少服务器的负载。
延迟加载的优势在于:
- 减少首屏加载时间:只加载用户当前看到的内容,其他内容按需加载。
- 节省带宽:避免加载用户可能永远不会查看的内容。
- 提升性能:在某些情况下,减少初始页面加载时间可以提升SEO排名。
3.1.2 实现延迟加载的方法和技巧
实现延迟加载的方法多种多样,包括但不限于:
- 图片和视频的延迟加载:通常利用浏览器的滚动事件来判断元素是否进入可视区域,再进行加载。
- 使用懒加载库:如Lazysizes、Lozad等,这些库提供了一套简单的API来实现延迟加载。
- 按需加载组件或模块:例如,使用Vue、React等现代前端框架时,可以利用组件的异步加载特性。
3.1.3 延迟加载在实际应用中的案例分析
以一个电子商务网站的图片画廊为例,首页展示的商品图片非常多,全部一次性加载会严重影响页面的加载速度。通过实施延迟加载策略,只有用户滚动到画廊中某个图片区域时,该区域内的图片才开始加载。这不仅减轻了服务器的压力,还提高了页面的响应速度,增强了用户体验。
3.2 分页加载的实现
3.2.1 分页加载原理及优势
分页加载(Pagination)是将大量数据集分割成若干个小的数据集,每个小的数据集称为“页”,用户可以通过翻页来查看更多的数据。分页加载的原理简单,优势显著:
- 减少单次加载的数据量,降低内存消耗和渲染时间。
- 用户体验提升,用户可以逐步加载更多数据,而不需要等待所有数据加载完成。
- 服务器资源利用更合理,避免因一次性加载大量数据而导致的服务器压力过大。
3.2.2 实现分页加载的技术细节
分页加载的实现细节包括:
- 分页参数的设置:通常需要包括当前页码、每页显示数量等参数。
- 数据加载方式:可以是前端的分页控件,也可以是后端API配合前端分页控件。
- 状态管理:前端需要记录当前页码、总页数等信息,以便于用户进行翻页操作。
3.2.3 分页加载对用户体验的影响分析
良好的分页加载实现不仅能够提升页面性能,还能极大地优化用户体验。例如,快速响应用户点击“下一页”的动作,提供清晰的页码导航,以及加载状态的提示等。
以下是使用JavaScript实现分页加载的一个基本示例代码:
// 假设有一个函数用于获取数据
function fetchData(page, pageSize) {
// 模拟通过API获取数据
// 返回的数据格式通常为 {data: [], total: 0}
return new Promise((resolve, reject) => {
setTimeout(() => {
let data = '模拟数据';
let total = 100; // 假设总数据量为100
let start = (page - 1) * pageSize;
let end = start + pageSize;
resolve({
data: data.slice(start, end),
total: total
});
}, 1000);
});
}
// 分页加载的核心逻辑
function loadPage(page) {
fetchData(page, 10).then(({ data, total }) => {
// 处理获取到的数据
console.log(`Page ${page} data:`, data);
// 更新UI元素,显示总页数和分页控件
document.getElementById('total-pages').textContent = total;
// 更多的分页逻辑...
});
}
// 调用分页加载
loadPage(1); // 加载第一页数据
在该示例中,我们创建了一个 fetchData 函数来模拟数据获取过程,使用了Promise来处理异步操作。通过 loadPage 函数调用 fetchData 来加载指定页的数据,并通过 .then 方法处理这些数据。
以上介绍了延迟加载和分页加载的原理与实现,希望对读者优化自身项目的加载策略有所启发。在下一节中,我们将深入探讨如何通过分页加载来提升用户体验。
4. 项目文件分析:样式表、HTML页面、JavaScript文件
在现代Web开发中,项目的文件结构和代码组织至关重要。它们直接关系到项目的可维护性、性能和可扩展性。本章将深入探讨项目文件的分析,包括样式表(CSS)、HTML页面结构,以及JavaScript文件的模块化和性能优化。
4.1 样式表文件分析
样式表文件是决定网页视觉表现的核心组成部分。它们不仅让网页美观,还能够提高网页的性能。
4.1.1 CSS文件的作用与优化方法
作用:
CSS(Cascading Style Sheets)定义了HTML元素的布局、位置、颜色、字体和其他视觉样式属性。一个良好的CSS文件能够让网页布局清晰、风格一致,并提供优质的用户体验。
优化方法:
- CSS合并与压缩 :减少HTTP请求的数量,使用工具如CSSNano或cleancss将多个CSS文件合并为一个,并压缩代码。
-
代码规范 :遵循特定的CSS编写规范,如使用BEM、SMACSS或OOCSS等方法,增加代码的可读性。
-
避免过度限定选择器 :使用简单的类选择器和ID选择器,避免嵌套过深,减少计算复杂度。
-
使用CSS预处理器 :如Sass或Less,可以使用变量、函数和混合(mixins)等高级功能来编写更易于维护的CSS代码。
-
利用CSS3特性 :使用CSS3渐变、阴影等特性,可以减少对图片的依赖,从而减小页面加载时间。
4.1.2 样式表的组织结构和复用性
组织结构:
良好的CSS文件组织结构应该是层次分明、清晰易懂的。可以将样式表分为几个部分:基础样式、布局样式、组件样式和主题样式。
- 基础样式 :包含重置样式和一些基本元素的样式,如链接、列表、表格等。
-
布局样式 :定义了网页的主要布局区域的样式,如头部、导航栏、内容区域等。
-
组件样式 :定义了可复用的组件,如按钮、表单元素、卡片等。
-
主题样式 :包含颜色、字体等主题相关的样式。
复用性:
样式复用能够提高开发效率和保持样式一致性。可以通过以下方式实现样式的复用:
-
类重用 :通过定义通用类来实现样式的复用,例如
.text-center表示文本居中。 -
mixins :在Sass或Less中使用mixins来复用一段代码块。
-
继承 :CSS选择器可以继承其他选择器的样式,这可以减少重复代码。
-
CSS变量 :使用CSS自定义属性可以定义可在整个样式表中复用的颜色和尺寸变量。
4.1.3 样式表的代码示例
/* 基础样式 */
body {
margin: 0;
padding: 0;
font-family: Arial, sans-serif;
}
/* 布局样式 */
.header {
background-color: #333;
color: #fff;
padding: 10px;
}
/* 组件样式 */
.button {
background-color: #007bff;
color: white;
padding: 10px 20px;
text-decoration: none;
display: inline-block;
}
/* 主题样式 */
:root {
--primary-color: #007bff;
--secondary-color: #6c757d;
}
4.2 HTML页面结构分析
HTML页面是用户与网页交互的载体,其结构直接影响到SEO和用户的阅读体验。
4.2.1 HTML文档结构的最佳实践
文档类型声明: HTML文档应以正确的文档类型声明开始,以确保浏览器按预期的模式渲染页面。
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>页面标题</title>
</head>
<body>
<!-- 页面内容 -->
</body>
</html>
语义化标签: 使用语义化的HTML标签能够提高页面内容的可读性和可访问性。例如,使用 <header> , <footer> , <article> , <section> 等标签。
链接和导航: 使用 <nav> 标签定义导航链接,确保导航结构清晰。
4.2.2 语义化标签的应用与优势
语义化标签不仅对搜索引擎友好,还能提升页面的结构化程度。使用正确的语义化标签可以使页面更加易于导航,尤其对于屏幕阅读器等辅助设备特别重要。
<header>
<nav>
<ul>
<li><a href="#">首页</a></li>
<li><a href="#">产品</a></li>
<li><a href="#">关于我们</a></li>
</ul>
</nav>
</header>
<main>
<section>
<article>
<h1>文章标题</h1>
<p>这里是文章内容...</p>
</article>
<!-- 其他文章内容 -->
</section>
</main>
<footer>
<p>版权所有 © 公司名称</p>
</footer>
4.3 JavaScript文件的模块化与性能优化
JavaScript是Web开发的核心之一,其模块化和性能优化对于提升用户体验至关重要。
4.3.1 JavaScript模块化的概念和好处
模块化:
模块化是将大的JavaScript代码分割成独立、可管理的小块的过程。它有助于代码复用、更容易测试和维护。
好处:
1. 代码组织 :更容易管理和理解代码结构。
2. 复用性提高 :模块可以被多个文件和项目复用。
3. 依赖管理 :自动管理代码间的依赖关系。
4.3.2 代码分割和懒加载技术的应用
代码分割(Code Splitting):
使用现代JavaScript打包工具如Webpack,可以将应用分割成若干个“块”,按需加载,减少初次加载时间。
// 使用动态import实现代码分割
import('./utils/math.js').then(math => {
console.log(math.add(16, 26));
});
懒加载(Lazy Loading):
懒加载是一种性能优化技术,它会延迟页面上非关键资源的加载时机,仅在需要时才加载。
// 懒加载图片示例
document.addEventListener('DOMContentLoaded', () => {
const images = document.querySelectorAll('img.lazy-load');
images.forEach(img => {
const src = img.dataset.src;
if (src) {
img.src = src;
}
});
});
4.3.3 性能监控与分析工具的使用
性能监控:
使用Performance API可以监控应用的性能指标,如加载时间、渲染时间等。
if (window.performance) {
console.log('加载时间: ' + (window.performance.timing.loadEventEnd - window.performance.timing.navigationStart) + 'ms');
}
分析工具:
Lighthouse、Chrome DevTools等工具可以进行性能审计和分析。
graph LR
A[开始审计] --> B[分析网站性能]
B --> C[检测最佳实践]
C --> D[分析SEO]
D --> E[检查渐进式Web应用]
E --> F[生成审计报告]
在本章节中,我们了解了如何对样式表、HTML页面以及JavaScript文件进行深入分析和优化。这些优化技巧对于提升Web应用的性能和用户体验有着直接的影响。通过采用模块化、代码分割、懒加载等技术,开发者能够显著减少应用加载时间,提升页面交互效率。接下来的章节将探讨如何通过技术实现高效、优化的树形数据展示。
5. 实现高效、优化的树形数据展示
5.1 树形数据展示的设计原则
在Web应用中实现树形数据展示,设计原则是至关重要的,它们影响到最终用户体验和系统性能。我们需要考虑以下几个关键点:
5.1.1 用户体验和交互设计的考虑
- 清晰的视觉层次 :在树形结构中,确保用户能够轻松地区分不同层级的节点,通常通过视觉上的层次感来实现,比如使用缩进来表示层级关系。
- 交互性 :设计中需要考虑用户如何与树形结构交互,比如节点的展开和折叠,选中节点后的响应等。
- 反馈机制 :用户操作后应给予明确的反馈,如展开/折叠节点时的过渡动画,以及在节点被选中时的高亮显示。
5.1.2 数据展示的性能优化技巧
性能优化是树形数据展示中的难点,因为展示的数据量可能很大,我们需要关注以下几点:
- 懒加载 :只加载可视区域内的节点,随着用户的滚动加载更多的节点数据。
- 虚拟DOM :使用虚拟DOM技术来最小化DOM操作,提高渲染效率。
- 缓存策略 :对频繁访问的数据进行缓存,减少对后端数据源的请求次数。
5.2 动态树形结构展示的实现
5.2.1 动态数据绑定与事件处理机制
在JavaScript中,我们可以使用ES6的 class 关键字和事件监听模式来实现动态数据绑定与事件处理:
class TreeNode {
constructor(data) {
this.data = data;
this.children = [];
this.parent = null;
this.expanded = false;
this.selected = false;
}
// 添加子节点
addChild(child) {
child.parent = this;
this.children.push(child);
}
// 展开节点
toggleExpanded() {
this.expanded = !this.expanded;
}
// 选择节点
toggleSelected() {
this.selected = !this.selected;
}
}
// 事件监听示例
const treeElement = document.getElementById('tree');
treeElement.addEventListener('click', (event) => {
const node = event.target.closest('.node');
if (node) {
node.toggleSelected();
node.toggleExpanded();
}
});
这段代码通过面向对象的方式定义了树节点类 TreeNode ,并提供了添加子节点、展开和选择节点的方法。此外,还演示了如何在DOM元素上设置事件监听器以响应用户的交互。
5.2.2 树节点的动态展开与折叠
节点的动态展开与折叠逻辑是树形结构中非常重要的一个功能,可以通过以下代码实现:
// 动态展开与折叠逻辑
function expandTreeNode(node) {
if (node.expanded) {
collapseTreeNode(node);
} else {
expandTreeNode(node);
}
}
function expandTreeNode(node) {
// 展开节点前的操作,例如加载子节点数据等
// ...
// 展开节点UI的操作
node.toggleExpanded();
updateUI(node);
}
function collapseTreeNode(node) {
node.toggleExpanded();
updateUI(node);
}
function updateUI(node) {
// 更新节点的DOM表示,例如调整缩进等
// ...
}
5.2.3 异步加载数据的展示策略
当树形结构的数据量很大时,异步加载数据是提高性能的常见策略:
function fetchData(url) {
return new Promise((resolve, reject) => {
const xhr = new XMLHttpRequest();
xhr.open('GET', url, true);
xhr.onreadystatechange = function() {
if (xhr.readyState === 4 && xhr.status === 200) {
resolve(JSON.parse(xhr.responseText));
}
};
xhr.onerror = function() {
reject(new Error('Network Error'));
};
xhr.send();
});
}
async function loadNodesAsync(node) {
try {
const childrenData = await fetchData(`path/to/data?parentId=${node.id}`);
childrenData.forEach(child => {
const newNode = new TreeNode(child);
node.addChild(newNode);
});
updateUI(node); // 更新UI以显示新加载的子节点
} catch (error) {
console.error('Error loading nodes:', error);
}
}
在这个例子中,我们定义了 fetchData 函数来异步获取数据,并通过 loadNodesAsync 函数来处理节点数据的加载。这使得我们能够在用户请求时才从服务器获取数据,而不是在页面加载时加载所有数据。
综上所述,高效和优化的树形数据展示需要我们从用户体验和性能优化两个方面出发,设计清晰的交互和缓存策略,实现动态数据绑定,以及采用异步加载数据的方法。通过这些方法,我们能够提供更加流畅和快速的用户交互体验。
6. 案例分析:在Web应用中实现树形数据展示
6.1 实际案例背景介绍
6.1.1 案例需求分析与功能设计
在Web应用中,树形数据结构常常用于表示具有层级关系的信息,如文件目录、组织结构、类别分类等。本案例分析将深入探讨如何在Web应用中实现树形数据的展示,分析实际需求并设计功能。
案例需求分析:
- 需要展示一个组织的层级结构,包括部门、团队和员工。
- 用户能够通过点击节点展开和折叠子节点。
- 节点可以动态加载,即用户在展开节点时,只有在这个操作发生时才加载子节点数据。
- 提供搜索功能,让用户能够快速定位特定的节点。
功能设计:
- 动态加载: 应使用延迟加载技术,优化初次加载时间和用户体验。
- 交互式展开和折叠: 实现平滑的节点展开和折叠动画效果。
- 异步搜索: 通过异步加载数据,使得搜索操作实时响应,不阻塞界面。
- 树节点操作: 提供添加、删除和修改节点的功能,支持快捷键和上下文菜单。
6.1.2 应用环境与技术选型
为了实现案例中的树形数据展示,需要选择合适的技术栈和开发环境。
技术选型:
- 前端框架: React或Vue,两者都提供了强大的组件化开发能力。
- 状态管理: Redux或Vuex,用于管理全局状态,使得组件间的数据共享更加方便。
- 数据处理: 使用Immutable.js来优化性能和避免不可变数据结构的直接修改。
- UI组件库: Ant Design或Element,它们提供了丰富的UI组件,包括用于树形结构的组件。
- 后端技术: Node.js配合Express框架,使用REST API与前端交互。
- 数据库: MongoDB或MySQL,根据数据模型的需求和规模选择。
6.2 树形数据展示实现过程
6.2.1 数据预处理和模型构建
在展示树形数据之前,需要对数据进行预处理,构建适合展示的数据模型。
// 示例代码:构建树形数据模型
const treeData = [
{
key: '1',
title: '部门A',
children: [
{ key: '1-1', title: '团队X' },
{ key: '1-2', title: '团队Y' },
],
},
{
key: '2',
title: '部门B',
children: [
{ key: '2-1', title: '团队Z' },
],
},
];
// 递归函数构建树结构
function buildTree(data, parentId = null) {
return data
.filter(item => item.parentId === parentId)
.map(item => ({ ...item, children: buildTree(data, item.key) }));
}
// 生成树形结构数据
const treeModel = buildTree(treeData);
数据模型构建逻辑分析:
- 通过递归函数 buildTree 将扁平数据转换为嵌套结构。
- 树节点包含 key 和 title 属性,以及 children 子节点数组。
- parentId 属性用于标识节点的父级,根节点的 parentId 为 null 。
6.2.2 前端展示层的实现细节
前端展示层的实现是用户直接交互的界面,细节决定成败。
// React 示例代码:使用Ant Design的Tree组件展示树形数据
import { Tree } from 'antd';
import { useEffect, useState } from 'react';
function App() {
const [treeData, setTreeData] = useState([]);
useEffect(() => {
// 假设从后端获取数据
fetch('api/treeData')
.then(response => response.json())
.then(data => setTreeData(buildTree(data))); // 使用前面构建的函数
}, []);
return (
<Tree
treeData={treeData}
onExpand={expandedKeys => console.log(expandedKeys)}
onSearch={value => console.log(value)}
onCheck={checkedKeys => console.log(checkedKeys)}
/>
);
}
前端展示层实现逻辑分析:
- 使用React hooks管理组件状态和生命周期。
- 使用Ant Design的Tree组件来展示树形数据。
- onExpand 属性接收展开和折叠节点时的回调函数。
- onSearch 属性允许用户进行节点搜索。
- onCheck 属性支持节点选择功能,常用于多选场景。
6.2.3 后端数据处理与接口设计
后端需要提供必要的数据和处理逻辑来支持树形结构的动态加载。
// Node.js 示例代码:后端接口伪代码
const express = require('express');
const app = express();
const router = express.Router();
// 模拟从数据库获取数据的函数
function fetchTreeData() {
// 这里是数据库查询逻辑
return Promise.resolve(treeData);
}
// REST API接口
router.get('/api/treeData', async (req, res) => {
const data = await fetchTreeData();
res.json(data);
});
app.use('/api', router);
app.listen(3000, () => {
console.log('Server is running on port 3000');
});
后端接口设计逻辑分析:
- 使用Node.js和Express框架快速搭建REST API。
- fetchTreeData 函数模拟从数据库中获取数据。
- GET /api/treeData 接口用于返回树形数据给前端。
- 假设后端数据来源复杂时,可以实现分页加载、条件查询等功能。
以上章节内容和代码示例展示了在Web应用中实现树形数据展示的整个流程。通过实际案例背景的介绍,需求分析与功能设计,以及前端展示层的实现与后端数据处理,我们能够对树形数据在Web应用中的展示有更深入的理解。这种展示方式不仅增强了用户的交互体验,还提供了动态加载、搜索和节点操作等实用功能。
7. 未来展望:树形数据处理技术的发展趋势
7.1 新兴技术对树形数据处理的影响
随着信息技术的不断进步,新兴技术正以不可预知的速度改变着我们的工作方式,树形数据处理技术也不例外。在这一节中,我们将深入探讨大数据环境下树形数据的挑战,以及人工智能与树形数据处理结合的可能性。
7.1.1 大数据环境下树形数据的挑战
大数据技术的发展使得数据处理能力大幅提升,但同时也对数据结构提出了更高的要求。树形结构由于其层次清晰、易于管理等特性,在大数据场景下被广泛应用,但它也面临着一系列挑战:
- 数据规模的扩大 :随着数据量的激增,如何有效地管理和存储树形数据成为了一个难题。传统的树形结构可能在性能上遭遇瓶颈,需要通过分层存储、分布式处理等技术手段来应对。
- 数据实时性要求提高 :在某些应用场景中,数据的实时性是至关重要的。如何实现大规模树形数据的快速更新与查询,成为技术实现的焦点。
7.1.2 人工智能与树形数据处理的结合
人工智能的加入为树形数据处理技术带来了新的生机。通过机器学习算法,可以对树形数据进行智能分析和决策:
- 模式识别 :利用AI进行树形结构数据的模式识别,可以快速发现数据中的异常模式,比如网络入侵检测中的异常流量模式。
- 预测分析 :通过机器学习模型,可以根据现有的树形数据来预测未来的趋势或者行为,如销售预测、用户行为预测等。
7.2 树形数据展示技术的发展方向
树形数据展示技术是树形数据处理的一个重要分支。随着应用场景的扩展,树形数据展示技术也在不断发展。
7.2.1 从Web到桌面应用的展示革新
随着跨平台技术的发展,树形数据展示不再局限于Web页面,也扩展到了桌面应用甚至移动应用。这种展示革新的趋势表现在以下方面:
- 自适应布局 :树形数据展示技术越来越多地支持响应式设计,能够适应不同大小的屏幕和不同分辨率。
- 丰富的交云体验 :通过引入动画、交互式图表等元素,提高用户体验,使得树形数据展示不再是单调的列表形式。
7.2.2 树形数据可视化的新趋势与框架
树形数据的可视化是数据展示的一个重要方面。以下是当前和未来树形数据可视化的一些趋势:
- 交互性增强 :用户可以与树形数据进行交互,例如拖拽节点、缩放视图等,以更直观地探索和理解数据。
- 三维展示 :利用三维空间展示树形数据,可以提供更为直观和深入的视角。这方面的研究和开发正在不断进步。
树形数据处理技术的未来,注定是与新兴技术结合的未来。无论是在大数据环境下的挑战,还是在人工智能融合的趋势下,树形数据技术都将保持其在数据处理中的重要地位,并不断演化,以适应不断变化的技术需求和业务场景。
简介:JSON数据格式在IT行业中广泛应用,本话题探讨如何使用JavaScript高效地处理JSON数据并构建树形结构。JSON对象的parse()方法能够将JSON字符串转换为JavaScript对象。构建树形结构需要对解析后的数据进行特定处理,如建立父子节点关系。针对大数据量的树形结构,采用优化策略如延迟加载或分页加载可以提高加载速度。同时,本压缩包含有多个关键组件,如样式表、HTML示例页面和JavaScript文件,它们共同提供了一个完整的解决方案,以高效加载和展示树形结构数据。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









