






 本文通过爬取大众点评5000+餐厅数据,分析上海餐厅的分布、类型、价格区间及评分,揭示了以人民广场为中心的高密度餐厅分布,并探讨了各商圈的繁荣度与餐厅类型多样性。淮海路和陆家嘴成为餐饮繁华地标,日料、烧烤、咖啡厅等类型多样。此外,文章还研究了不同餐厅类型的消费者行为和人均消费趋势。
本文通过爬取大众点评5000+餐厅数据,分析上海餐厅的分布、类型、价格区间及评分,揭示了以人民广场为中心的高密度餐厅分布,并探讨了各商圈的繁荣度与餐厅类型多样性。淮海路和陆家嘴成为餐饮繁华地标,日料、烧烤、咖啡厅等类型多样。此外,文章还研究了不同餐厅类型的消费者行为和人均消费趋势。

作为标准的社畜吃货,一直有想着做一篇关于美食的数分内容,看看哪里工作的社畜最可怜,连吃美食的地方都没有,直到看到数据后我就又迷茫了,几百块的人均价堪比米其林,身边再多餐厅又有何用(手动狗头)。
言归正传,分析的第一步是数据的获取,在爬大众点评的餐厅的时候我差点就放弃了这个项目,他们的反爬真的很厉害(丧心病狂的那种),字符偏移、SVG、文字随机图片化(具体的问题大家可以参考git、csdn等),代理IP都没用,在手机流量超了1个G后,终于搞到了5000+数据。

美食里面的分类都对应着网址上的g**值,每个类别最多可以显示50页,最下面上代码。
因为不是每个菜系都是50页,所以最后的数据在5500家餐厅左右

共爬取:店铺名、店铺星级(空)、评论数、均价、店铺类型、商圈、地址、口味|服务|环境的评分共计10个字段。基于个人习惯,一般看到有详细地址的数据,我都会用百度地图api转换一下,最下面放转换地址的代码,篇幅原因,后续的分析代码就不上了,如果后续有需要我私发或者补上都可以。
调取百度地图的api,通过详细地址去获取经纬度。普通用户每天的逆向地理信息调用是6千次,调试几次就用完了,建议感兴趣的童鞋可以注册为开发者(身份证认证),每天有30万的额度,基本够用了。这里获取店铺的经纬度、所属区和门址信息,同大众点评上的商圈字段不同的是,百度的门址信息是划分信息,如(门牌号、车站、机场、商务楼……):

接下来就是一堆数据预处理的骚操作,删除重复数据、转变类型、填充或者删除无效信息……
然后,然我们看一下大众点评的餐厅都分布在哪里吧:
如图下图所示,基本上分布在以“人民广场”为中心的辐射半径为6公里的区域内(蓝色圆圈),各行政区内的店铺用不同颜色的店标记出来了,果然市区贵是有原因的稀疏密集程度和上海的房价几乎一致,难道是餐厅导致的上海高房价?大家赶紧去抵制吃饭,饭店关门了上海房价就跌了(再次狗头),黄浦和徐汇几乎是全区高密。

市区范围外,还有些零散的聚地点,基本在川沙(张江码农集聚地)、紫藤路(高新科技园)、车站、机场(虹桥的聚集效果更强)、迪士尼(景区):

上海各区域内的商圈数量,金山、青浦和奉贤这样的大郊区的商圈真的是屈指可数,市区虽然面积小但是商圈数据碾压郊区(浦东除外,浦东实在是太大了,还有陆家嘴这样的金融区),市区的商务办公地也多,办公——人多——商圈多——人多 大家互相成就,正向相关。

浦东的餐厅最多,黄浦其次,但想想两者的面积差,真的是恐怖(黄浦有226家咖啡店,小资情调MAX)

餐厅类型有日料、烧烤、咖啡厅等,我们探究下各个商圈下,每个商圈的餐厅类型有多少(该商圈所拥有的餐厅类型占整个上海餐厅类型的百分比),该指标反映商圈的繁荣度,餐厅类型越繁多,该商圈的人流量越大、越是繁华。
前六名分别是:淮海路(8.25%)、静安寺(5.39%)、人民广场(4.87%)、陆家嘴(4.64%)、虹桥(4.33%)、徐家汇(4.24%),的确是大家耳熟能详的地标商圈。敲下黑板,外地来旅游的朋友可以去这几个地点,繁华热闹,饮食上也绝对能满足您的口味。
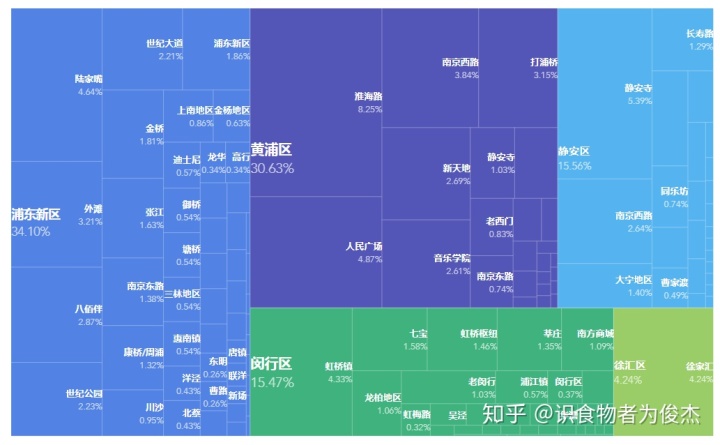
各个商圈的店铺数,各商圈数据均由下滑。但比较恐怖的是淮海路商圈,一条淮海路拥有整个上海地区5.12%的餐厅,一骑绝尘。怕不是整条路上全是餐厅?可怜我从小在淮海中路长大,也没吃几口好的(穷人在家吃)

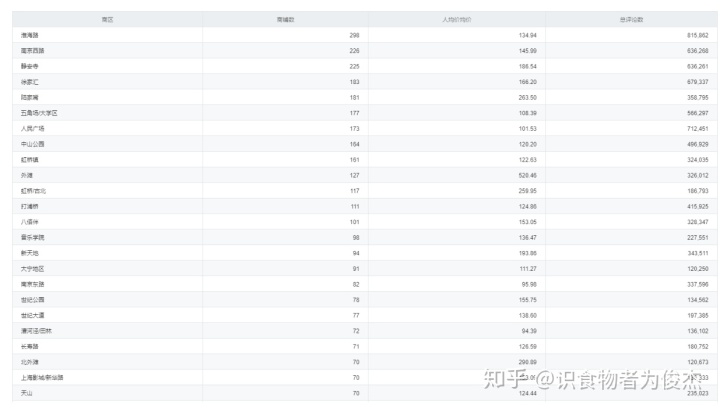
根据50以下、50-100、100-150这样的逻辑对人均消费分段,商圈大致以低价段-高价段递减的趋势,且淮海路商圈的100以下的人均店铺最多。值得一提的是陆家嘴商圈,其500以上人均消费的店铺比50-100人均的店铺还要多,不愧是金融凤凰男,我发四,以后再也不敢叫他们金融民工了。
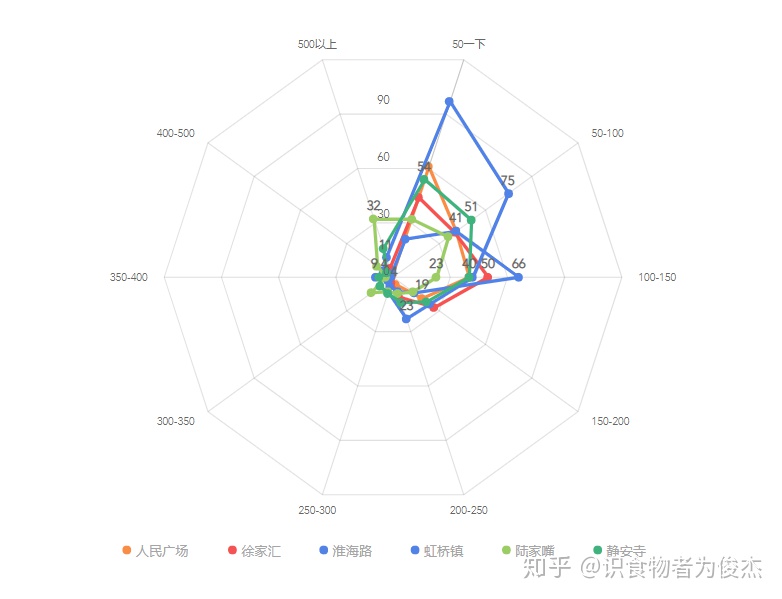
综上:从商圈角度而言,如果想吃的好、选择多,那么淮海路你一定不能错过,但您要是为了见识“魔都”,体验番一掷千金的“壕爽”,看看这灯红酒绿的十里洋场,那么2号线陆家嘴站欢迎您(呸,劳斯莱斯幻影、迈巴赫去接您)。
说了那么久,那么大众上到底哪些餐厅收录最多呢?

东北菜占有量接近5%,说明不少同学来自东北,可以想象下,海南的东北菜占比会不会高达50%(手动狗头)。
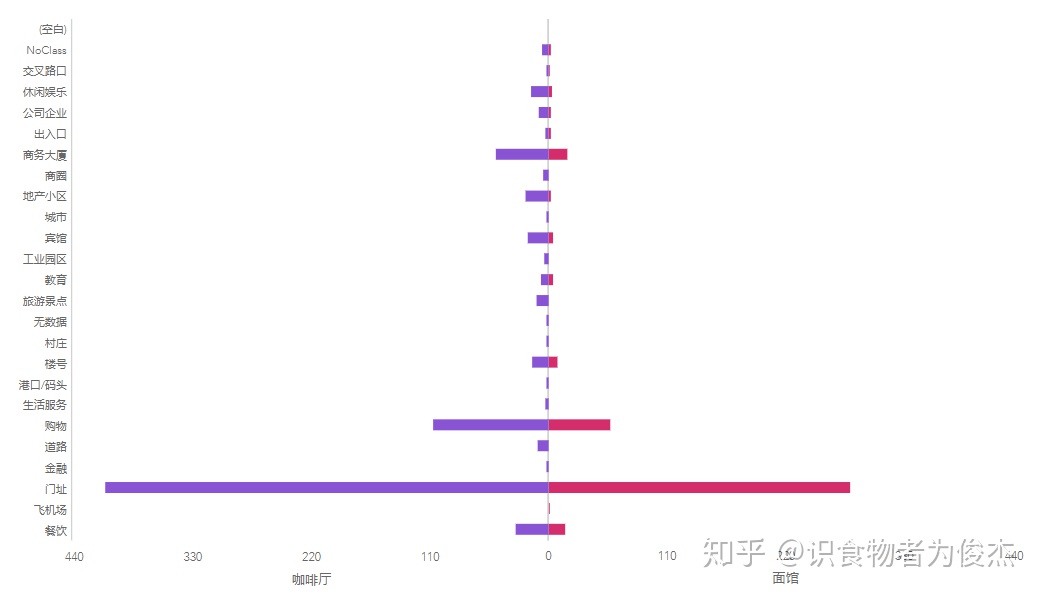
咖啡厅占比12.73%,面馆占比7.43%,难道大家都是吃饭时扒拉两口面,然后赶紧买杯咖啡继续加班么?果然上海是座工作型城市。为了验证设想,我们通过商圈对比面馆和咖啡馆的数量,两者成完美的正相关
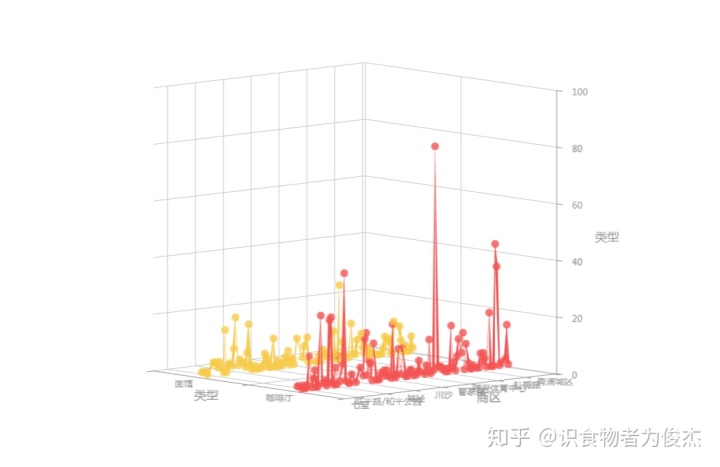
从百度的地址分类来看,收录的这五千多家餐厅,多以门址、购物、商务大厦和宾馆为主(依次递降)。
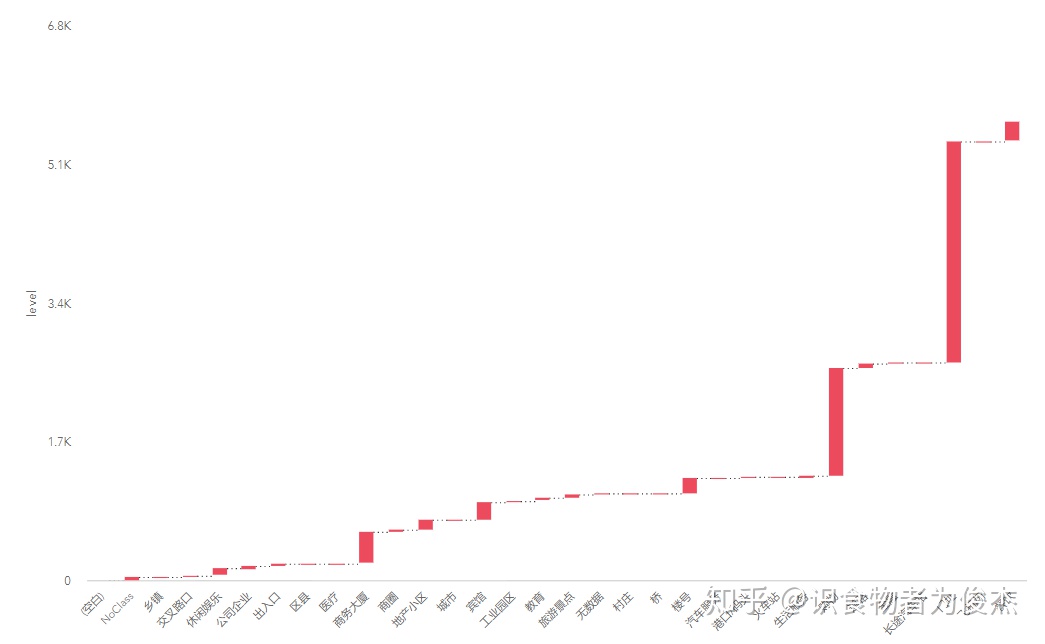
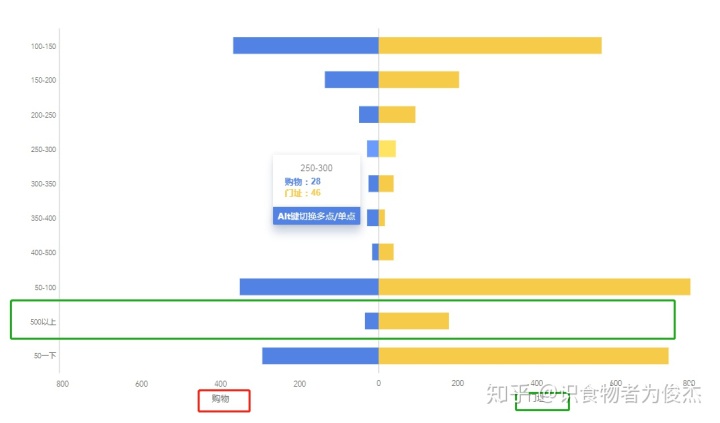
门址和购物的对比,基本分布一致,比较有意思的是门址的500+人家的餐厅远远大于其他类型地址。证明门址地点比较特殊,两级分化严重,要么是低端低消费的苍蝇馆子,要么就是高逼格、豪装的特色餐厅和外国料理。
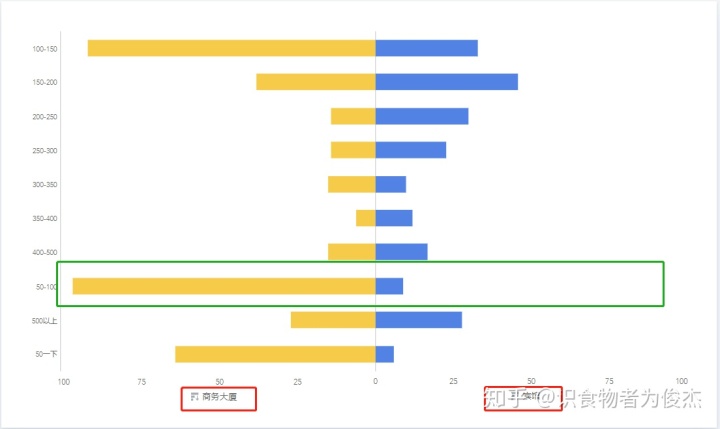
商务大厦和宾馆的对比同上图的人均分布比较大体一致,比较特殊的是,商务大厦人均最多的在50-100的价格段,宾馆人均消费最短的价格段在150-200。以写字楼白领为主商务大厦主打中低端商务餐,而宾馆的住宿人群出手较为豪气(无论出差还是旅游,肯定是舍得花钱的)。
而餐厅类型最多的咖啡厅和面馆在百度地址上却无明显差役,分布几乎一致(在此不套路较小餐厅类型,烧烤餐饮肯定在商场的少啊)
大众点评上对于餐厅有三个关键的评分指标: 服务、环境、口味,我们将每家店铺的三个指标分想加求平均分,获取店铺的平均分,较为平均:
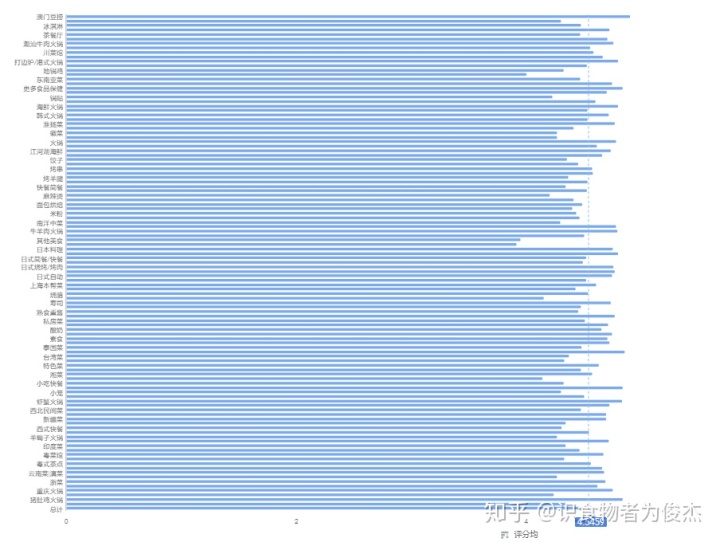
各家店铺都会有大众劵、买单打折活动,但是不是每个人都会去写点评。无论好坏,评论数能够代表一家店铺的人气,而高评论店铺一定是优质店铺,不然差评会让店铺没有人气,同时高评也能够代表该类型的店铺人均消费较低,以实惠著称。
南京菜、烤鸭、粤式茶点、火锅、日式自助是评论均榜的前五,基本以本地菜系为主,唯一入选的日料还是自助餐。南京菜的评论多,让我再次明白一个道理:没有一个鸭子能活着游过秦淮河,没有一个人能错过南京大牌档……

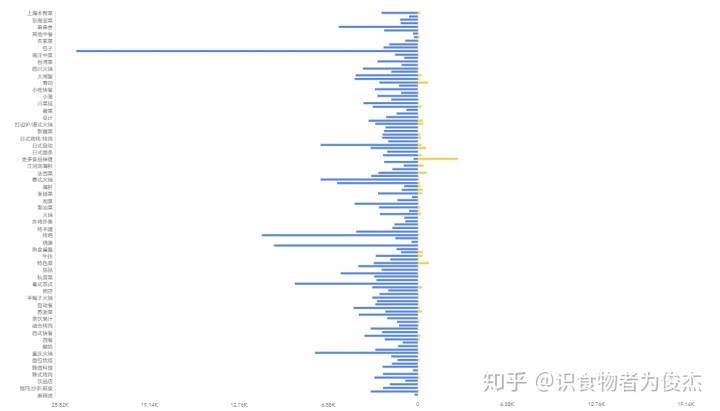
食品保健类餐厅的人均价遥遥领先,人均价要到3000元,抛掉保健特色不谈,人均价从高到低依次为:特色菜、寿司、法国菜、日本铁板烧、江湖河海鲜。印象中奢华的法国菜反倒只排到了第三(671元/人),就是没有想到寿司人均能到达795,不都是几十块一盒么。。。
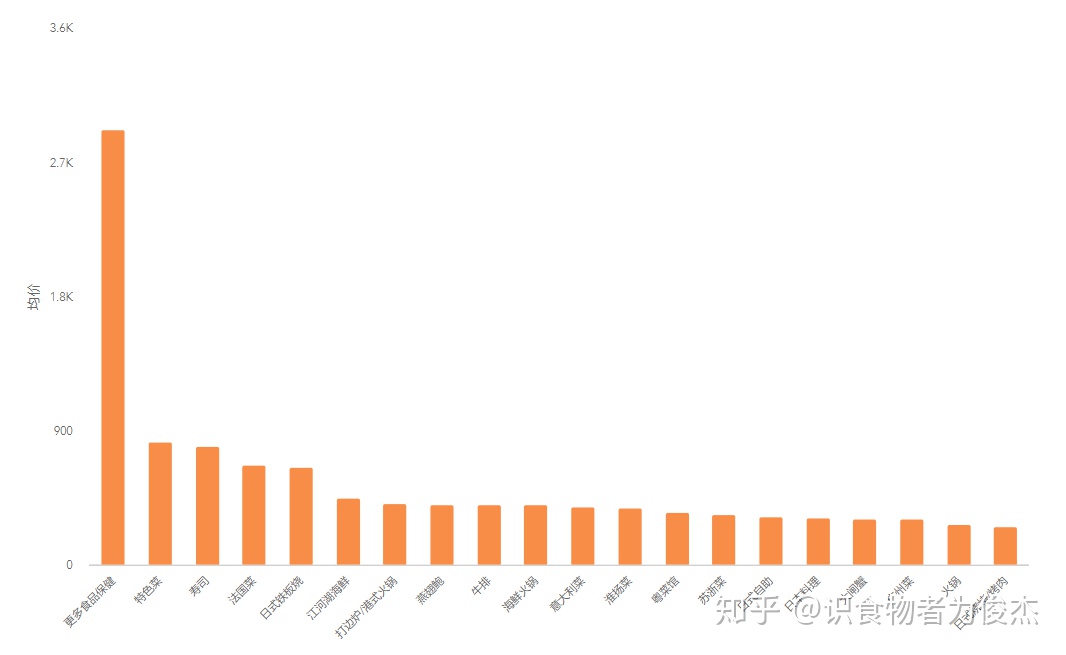
写了很多,对于我们这样想尝鲜的小伙伴来说,选择什么类型的餐厅最不容易采坑呢?
此处通过人均得分+餐厅评论得分+三指标(环境、服务、口味)得分【对各类型餐厅均分排序,赋予1-n分,然后三项指标得分累计计算出总分】,计算出更优质的餐厅类型,不易让大家采坑。
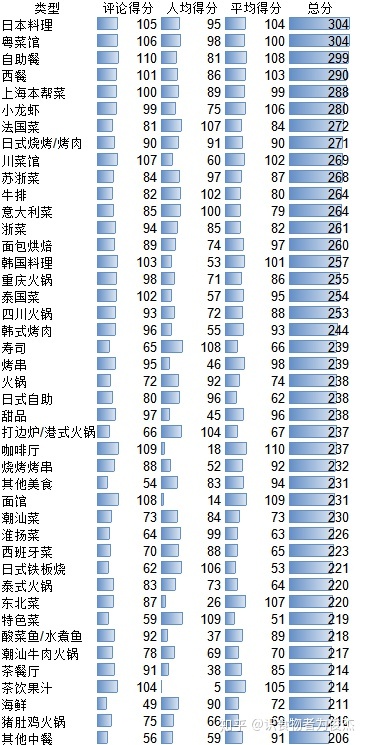
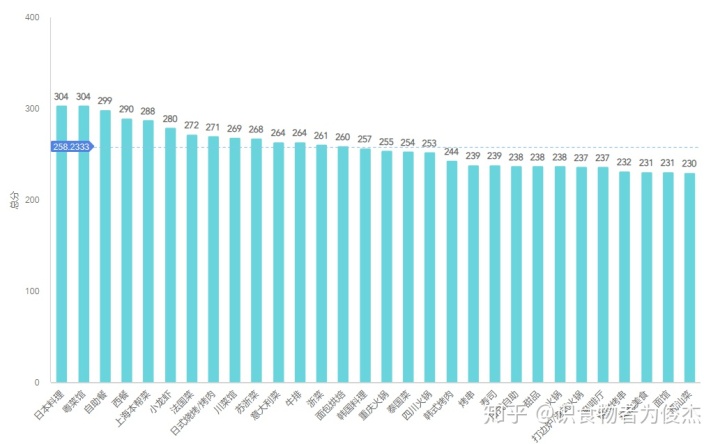
日料、粤菜馆、自助餐、西餐的综合评分最高,口味也更能迎合大部分人,也不易踩坑,本帮菜的得分也较高,外地朋友也值得一尝。
再次对人均消费价进行划段,100元以内为经济型餐厅(应该去除咖啡厅的),100-150为普通型餐厅,150-250为小资型餐厅、250-350为轻奢类餐厅、350-500为昂贵型餐厅,500元以上为奢侈型餐厅。如下图所示,各区域内基本低消到高消递降,无论哪个城市,普罗大众才是最广泛的群体,最值得敬佩的群体。
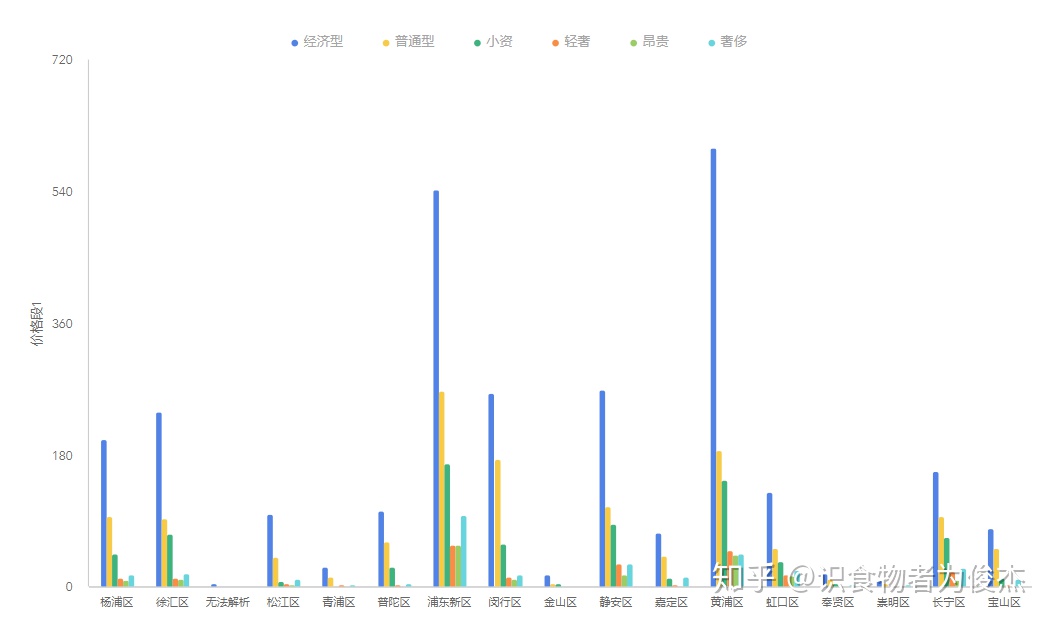
这是第二次追加文章了,数据表、图太多,细分下来篇幅实在恐怖。毕竟兴趣使然,没有确切分析目标,文章到此告一段落,代码下复。
爬虫代码:
import requests
from requests.exceptions import RequestException
from bs4 import BeautifulSoup
import json
import time
import random
from numba import jit
#获取一页内容
def get_one_page(url):
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': '你的浏览器cookie
',
'Host': 'www.dianping.com',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36'
}
proxiess=['http://39.105.104.1:3128',
'http://47.113.121.239:3128',
'http://58.220.95.54:9400',
'http://61.135.185.92:80',
'http://163.177.151.76:80',
'http://210.26.49.89:3128',
'http://117.185.17.151:80',
'http://117.185.17.177:80',
'http://111.13.100.91:80',
'http://47.98.162.91:6666',
'http://117.57.85.249:4216']
print(random.choice(proxiess))
try:
response = requests.get(url, headers=headers,proxies={'http':random.choice(proxiess)})
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
#解析一页内容
def parse_one_page(html):
soup = BeautifulSoup(html, 'lxml')
infos = soup.select('#shop-all-list ul li div.txt')
print(infos)
# time.sleep(random.uniform(1,3))
for info in infos:
yield {
'商铺': info.h4.get_text(),
'星级': info.find(class_="comment").span.get('title'),
'评论数': info.select('.review-num b')[0].string if info.select('.review-num b') else None,
'均价': info.select('.mean-price b')[0].string if info.select('.mean-price b') else None,
'类型': info.select('.tag')[0].string if info.select('.tag') else None,
'商区': info.select('.tag')[1].string if info.select('.tag') else None,
'地址': info.find(class_="addr").string,
'口味': info.select('.comment-list b')[0].string if info.select('.comment-list b') else None,
'环境': info.select('.comment-list b')[1].string if info.select('.comment-list b') else None,
'服务': info.select('.comment-list b')[2].string if info.select('.comment-list b') else None,
}
#保存结果数据
def write_to_file(content):
with open('result_shop.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii=False) + 'n')
f.close()
def main(start):
http = {
'http://www.dianping.com/shanghai/ch10/g101p',
'http://www.dianping.com/shanghai/ch10/g113p',
'http://www.dianping.com/shanghai/ch10/g112p',
'http://www.dianping.com/shanghai/ch10/g117p',
'http://www.dianping.com/shanghai/ch10/g110p',
'http://www.dianping.com/shanghai/ch10/g116p',
'http://www.dianping.com/shanghai/ch10/g111p',
'http://www.dianping.com/shanghai/ch10/g103p',
'http://www.dianping.com/shanghai/ch10/g114p',
'http://www.dianping.com/shanghai/ch10/g102p',
'http://www.dianping.com/shanghai/ch10/g118p',
'http://www.dianping.com/shangahi/ch10/g132p',
'http://www.dianping.com/shanghai/ch10/g219p',
'http://www.dianping.com/shanghai/ch10/g508p',
'http://www.dianping.com/shanghai/ch10/g115p',
'http://www.dianping.com/shanghai/ch10/g34236p',
'http://www.dianping.com/shanghai/ch10/g34014p',
'http://www.dianping.com/shanghai/ch10/g215p',
'http://www.dianping.com/shanghai/ch10/g106p',
}
for url in http:
time.sleep(random.uniform(1,2))
html = get_one_page(url + str(start))
for data in parse_one_page(html):
print(data)
write_to_file(data)
if __name__ == '__main__':
for i in range(50):
time.sleep(random.uniform(5,10))
main(i + 1)经纬度地址转换代码:
import pandas as pd
import json
import requests
import json
import math
import collections
import openpyxl
from pyecharts.charts import *
from pyecharts.components import Table
from pyecharts import options as opts
from pyecharts.commons.utils import JsCode
import random
import datetime
from numba import jit
from pyecharts.globals import CurrentConfig
CurrentConfig.ONLINE_HOST = "https://cdn.kesci.com/lib/pyecharts_assets/"
# pyecharts的js动态有些问题,有时图显现不出来,加上面两行代码
# 读取文章,存贮的数据是txt文件里的json,使用过read_json方法,并不可以,遂在此逐行读存
papers=[]
file = open('result_shanghai.txt', 'r',encoding='utf-8')
for lin in file.readlines():
dic = json.loads(lin)
papers.append(dic)
print(papers)
df = pd.DataFrame(papers)
# 因为详细地址的数据是路名,为了能够精确定位经纬度,需要在地址前加上上海市,不然无法识别
list3=[]
for i in df['地址'].values:
i=i.replace('地址:','')
print(i)
if i.startswith('上海') :
i=i
else:
i="上海市"+i
list3.append(i)
print(list3)
list2=[]
list4=[]
list5=[]
list6=[]
for line in list3:
# 去除换行符
line = line.strip('n').replace('#',' ')
# 去除特殊字符
line1 = line.replace('#', ' ').replace('/',' ').replace("'",'"')
try:
# 地址获取经纬度
baiduUrl="http://api.map.baidu.com/geocoding/v3/?address=%s&output=json&ak=kuRGjpEIfmc5qt8gKQjI5EwLSEzcKkB3&callback=showLocation"% (
line1)
req = requests.get(baiduUrl)
# print(req)
content = req.text
# print(content)
content = content.replace("showLocation&&showLocation(", "")
# print(content)
content = content[:-1]
baiduAddr = json.loads(content)
# print(baiduAddr)
level=baiduAddr["result"]["level"]
print(level)
list4.append(level)
except:
level='无数据'
list4.append(level)
print(level)
try:
lng = baiduAddr["result"]["location"]["lng"]
lat = baiduAddr["result"]["location"]["lat"]
list5.append(lng)
list6.append(lat)
# 经纬度获取城市
baiduUrl="http://api.map.baidu.com/reverse_geocoding/v3/?ak=你的ak&output=json&coordtype=wgs84ll&location=%s,%s"% (
lat, lng)
req = requests.get(baiduUrl)
content = req.text
print('hahahhahahah')
print(content)
baiduAddr = json.loads(content)
print('hehehhehehehhe')
print(baiduAddr)
province = baiduAddr["result"]["addressComponent"]["province"]
city = baiduAddr["result"]["addressComponent"]["city"]
district = baiduAddr["result"]["addressComponent"]["district"]
print(district)
list2.append(district)
except:
district='无法解析'
print(district)
list2.append(district)
list5.append('无')
list6.append('无')
# print(district)
print(list2)
print(list4)
print(list5)
print(list6)
df['区']=list2
df['level']=list4
df['经度']=list5
df['维度']=list6
df

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









