






 本文介绍了如何使用Python爬取微博的评论数据,并利用MongoDB存储,之后通过jieba分词和WordCloud库进行数据可视化,展示了Python在数据抓取和可视化的应用。
本文介绍了如何使用Python爬取微博的评论数据,并利用MongoDB存储,之后通过jieba分词和WordCloud库进行数据可视化,展示了Python在数据抓取和可视化的应用。
接上篇,这一篇将从技术层面讲讲是如何实现的。阅读本文您将会了解如何用python爬取微博的评论以及如何用python word_cloud库进行数据可视化。
准备工作
为什么要用m站地址?因为m站可以直接抓取到api json数据,而pc站虽然也有api返回的是html,相比而言选取m站会省去很多麻烦
打开该页面,并且用chrome 的检查工具 查看network,可以获取到评论的api地址。
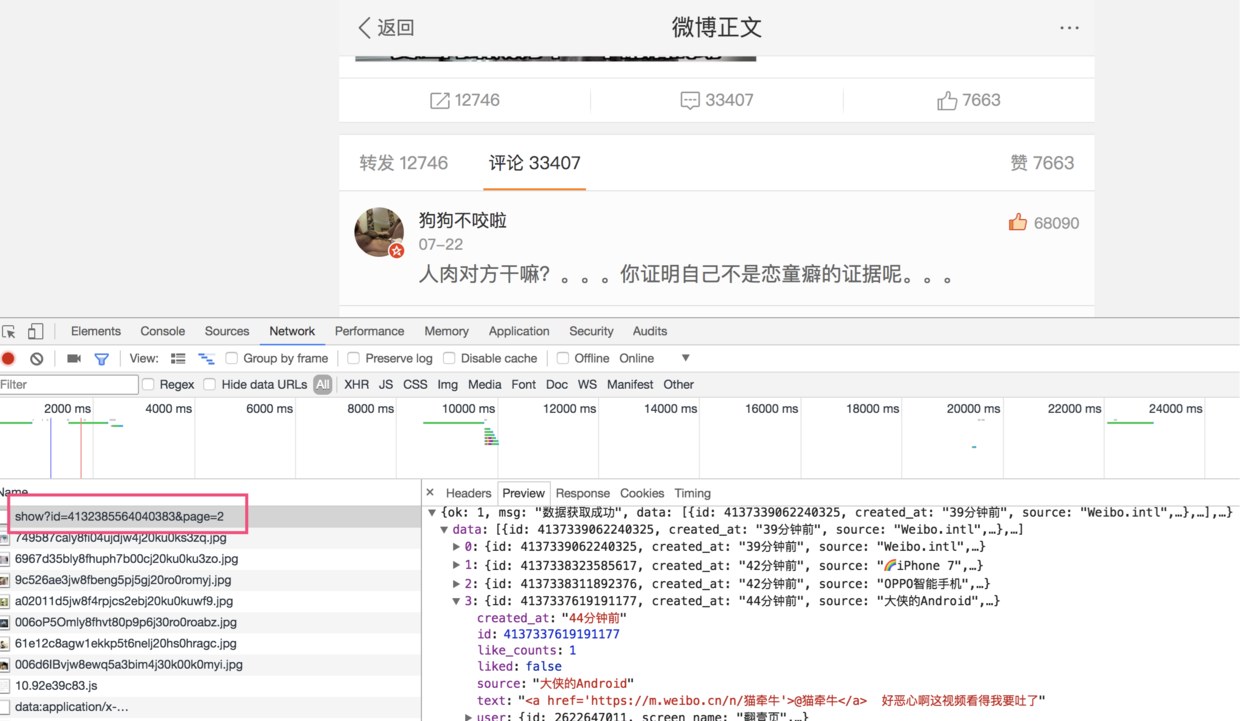
数据抓取
首先观察api返回
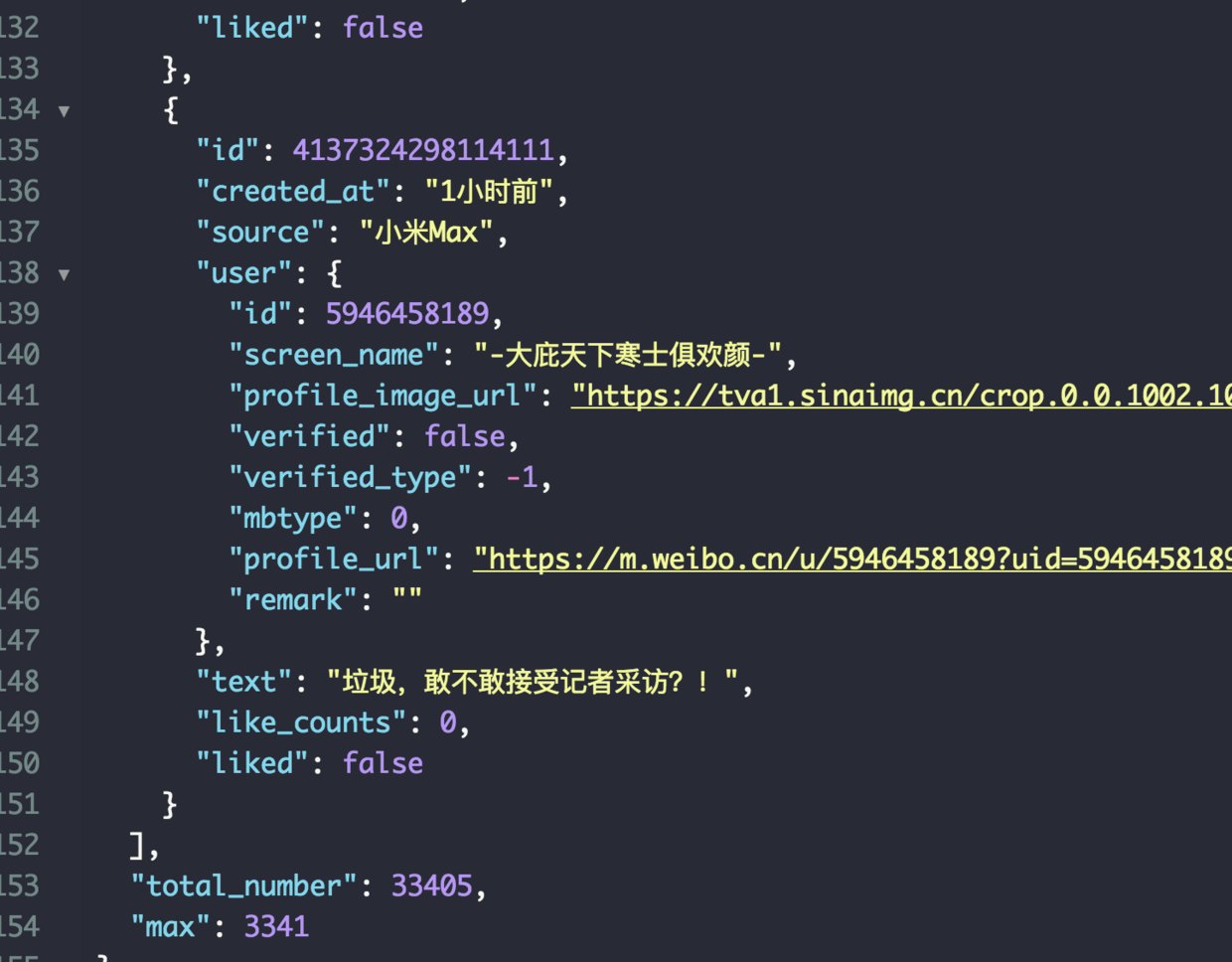
从返回地址上可以看到可以通过参数page 改变请求的页码,并且每页都回返回总条数和总页码数。这里我决定采用多线程来抓去(其实数据量不大,也可以单线程跑)。
其中在爬取数据的时候会面临几个问题:
1.存储选择
我这里选用了MongoDB作为数据存储,因为api通常返回的是json数据而json结构和MongoDB的存储方式可以结合的很默契,不需要经过任何处理可以直接的进行插入。
2.防爬虫
很多网站可能会做一些防爬虫的处理,面对同一个请求ip的短时间的高频率请求会进行服务隔断(直接告诉你服务不可用),这个时候可以去网上找一些代理进行请求。
3.多线程的任务分配
采用多线程爬取你当然不能让多个线程去爬取同样的链接做别人已经做过的事情,那样多线程毫无意义。所以你需要制定一套规则,让不同线程爬取不同的链接。
# coding=utf-8
from __future__ import division
from pymongo import MongoClient
import requests
import sys
import re
import random
import time
import logging
import threading
import json
from os import path
import math
# 爬取微博评论
# m站微博地址
weibo_url = 'https://m.weibo.cn/status/4132385564040383'
thread_nums = 5 #线程数
#代理地址
proxies = {
"http": "http://171.92.4.67:9000",
"http": "http://163.125.222.240:8118",
"http": "http://121.232.145.251:9000",
"http": "http://121.232.147.247:9000",
}
# 创建 日志 对象
logger = logging.getLogger()
handler = logging.StreamHandler()
formatter = logging.Formatter(
'%(asctime)s %(name)-12s %(levelname)-8s %(message)s')
handler.setFormatter(formatter)
logger.addHandler(handler)
logger.setLevel(logging.DEBUG)
mongoconn = MongoClient('127.0.0.1', 27017)
mdb = mongoconn.data_analysis
das_collection = mdb.weibo
weiboid_reobj = re.match(r'.*status/(\d+)', weibo_url)
weibo_id = weiboid_reobj.group(1)
def scrapy_comments(weibo_id, page):
weibo_comment_url = 'https://m.weibo.cn/api/comments/show?id=%s&page=%d' % (
weibo_id, page)
res = requests.get(weibo_comment_url)
res_obj = json.loads(res.content)
return res_obj
def import_comments(threadName, weibo_id, page_start, page_end):
logger.info('开始线程:%s' % threadName)
for page in range(page_start, page_end + 1):
logging.info('读取第%s页' % page)
time.sleep(1)
# continue
try:
res_obj = scrapy_comments(weibo_id, page)
logging.info('该页有%s条记录' % len(res_obj['data']))
except:
logging.error('读取%s页时发生错误' % page)
continue
if res_obj['ok'] == 1:
comments = res_obj['data']
for comment in comments:
comment_text = re.sub(
r'?\w+[^>]*>', '', comment['text']).encode('utf-8')
if re.search(r'回复@.*:', comment_text):
# 过滤掉回复别人的评论
continue
comment['text'] = comment_text
comment['weibo_id'] = weibo_id
logging.info('读取评论:%s' % comment['id'])
try:
if das_collection.find_one({'id': comment['id']}):
logging.info('在mongodb中存在')
else:
logging.info('插入记录:%s' % comment['id'])
das_collection.insert_one(comment)
except:
logging.error('mongodb发生错误')
else:
logging.error('读取第%s页时发生错误' % page)
logging.info('线程%s结束' % threadName)
# res_obj = scrapy_comments(weibo_id, page)
if __name__ == '__main__':
# 分配不同链接到不同的线程上去
res_obj = scrapy_comments(weibo_id, 1)
if res_obj['ok'] == 1:
total_number = res_obj['total_number']
logging.info('该条微博有:%s条评论' % total_number)
max_page = res_obj['max']
page_nums = math.ceil(max_page / thread_nums)
else:
raise
# print max_page
# print page_nums
for i in range(1, thread_nums + 1):
if i < thread_nums:
page_end = page_nums * i
else:
page_end = max_page
page_start = (i - 1) * page_nums + 1
t = threading.Thread(target=import_comments, args=(
i, weibo_id, int(page_start), int(page_end)))
t.start()
数据整理可视化(data visualization)
运行脚本完毕,我的MongoDB得到了2万多条评论数据,接下来要做的事是对这部分数据进行提取、清洗、结构化等操作。这里顺便说明一下python 数据分析的 大致基本流程。
1.与外界进行交互
这个过程包括数据的获取、读取。不管是从网络资源上爬取、还是从现有资源(各样的文件如文本、excel、数据库存储对象)
2.准备工作
对数据进行清洗(cleaning)、修整(munging)、整合(combining)、规范化(normalizing)、重塑(reshaping)、切片(slicing)和切块(dicing)
3.转换
对数据集做一些数学和统计运算产生新的数据集
4.建模和计算
将数据跟统计模型、机器学习算法或其他计算工具联系起来
5.展示
创建交互式的或静态的图片或文字摘要
下面我们来进行2、3及5的工作:
# coding=utf-8
import sys
from pymongo import MongoClient
import random
# 分词库
# from snownlp import SnowNLP
import jieba
import uniout
from collections import Counter, OrderedDict
# 词语云 文本统计可视化库
from wordcloud import WordCloud
mongoconn = MongoClient('127.0.0.1', 27017)
mdb = mongoconn.data_analysis
das_collection = mdb.weibo
total_counts = das_collection.find().count()
# random_int = random.randint(0, total_counts - 1)
docs = das_collection.find()
print docs.count()
words_counts = {}
for doc in docs:
print doc
comment_text = doc['text'].encode('utf-8')
if len(comment_text) == 0:
continue
words = jieba.cut(comment_text)
for word in words:
if word not in words_counts:
words_counts[word] = 1
else:
words_counts[word] += 1
for word in words_counts.keys():
if words_counts[word] < 2 or len(word) < 2:
del words_counts[word]
# print words_counts.items()
#注意要让中文不乱码要指定中文字体
#fit_words 接收参数是dict eg:{'你':333,'好':23} 文字:出现次数
wordcloud = WordCloud(
font_path='/Users/cwp/font/msyh.ttf',
background_color='white',
width=1200,
height=1000
).fit_words(words_counts)
import matplotlib.pyplot as plt
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
介绍下以上代码:
我们主要用到了2个工具,jieba和word_cloud。前者对中文进行分词后者图形化展示词语的出现频率。
众所周知,中文系的语言处理恐怕是最难的自然语言处理(NLP)的语种。就基本的分词而言都是一项比较困难的工作,(英语句子中每个单词都是有空格分开的,而中文是由单个字组成词连接成串组成句).
举个例子,请用“孩提”造句,"那个男孩提交完代码就下班了"。如果人工分词,可以知道"男孩"和"提交"应该是分开的2个词,但是对于机器而言,要辨别"提"应该与"男"还是"交"进行组词就很难办了。要想机器能够更精确的辨别这类问题,就需要让机器不停学习,让它知道这种情况该这么分而不是那么分。研究中文自然语言处理将是一个长久而大的工程,对于分析数据(我们不是要研究自然语言处理😏),这里就借助jieba这个库进行工作了.
对于word_cloud,图形化文本统计,网上有不少的博文都贴了代码,但我想说的是我不了解它们是不是真的运行出了结果。因为fit_words 这个函数接收的是dict而不是list,官方文档和函数doc其实写错了,在github上有披露。
最后得到结果:

一些用到的工具

















 458
458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









