







 本文详细介绍了支持向量机(SVM)的基本概念,如超平面、支持向量和间隔。SVM旨在找到最大化间隔的分类超平面,以减少过拟合风险。文章讨论了SVM的优缺点,强调其在处理高维数据和非线性分类中的优势。接着,解释了异常值处理和合页损失函数,以及如何通过二次规划或对偶问题求解SVM。此外,还探讨了如何将SVM扩展到多类别分类,包括OVR和OVO策略。最后,通过识别有毒蘑菇的实战案例展示了SVM在实际问题中的应用,包括数据预处理、模型训练、预测和性能评估。
本文详细介绍了支持向量机(SVM)的基本概念,如超平面、支持向量和间隔。SVM旨在找到最大化间隔的分类超平面,以减少过拟合风险。文章讨论了SVM的优缺点,强调其在处理高维数据和非线性分类中的优势。接着,解释了异常值处理和合页损失函数,以及如何通过二次规划或对偶问题求解SVM。此外,还探讨了如何将SVM扩展到多类别分类,包括OVR和OVO策略。最后,通过识别有毒蘑菇的实战案例展示了SVM在实际问题中的应用,包括数据预处理、模型训练、预测和性能评估。
1. 介绍
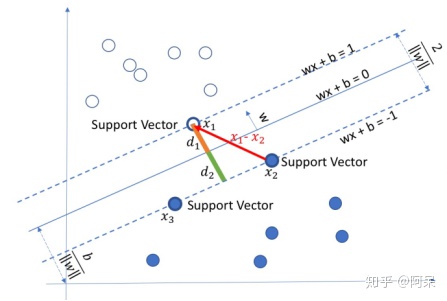
1.1 基本概念
超平面:wx+b = 0,也就是分类的决策边界。
支持向量:x1,x2,x3等,指离分隔超平面最近的那些点。
间隔:两个异类支持向量到超平面的距离之和。
支持向量机(SVM)的任务就是要找到具有“最大间隔”划分超平面,也就是最小化||w||的平方,从而使得划分超平面所产生的分类结果是最鲁棒的:
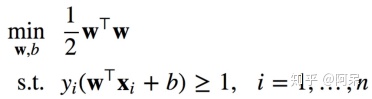
1.2 优缺点
支持向量机专注于寻找最优分界线,用于减少过拟合。Kernel Trick的应用使得支持向量机可以高效的用于非线性可分的情况。
优点:理论非常完美;支持不同的kernel,用于调参
- 模型只需要保存支持向量, 模型占用内存少, 预测快
- 分类只取决于支持向量, 适合数据的维度高的情况, 例如DNA数据
缺点:当数据量特别大时,训练速度特别慢
- 训练的时间复杂度为高, 当数据量巨大时候不合适使用。
- 需要做调参 C 当数据量大时非常耗时间.
2. 求解模型
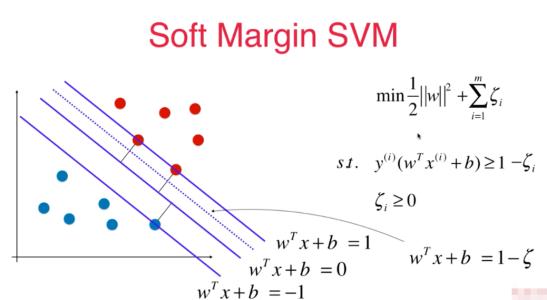
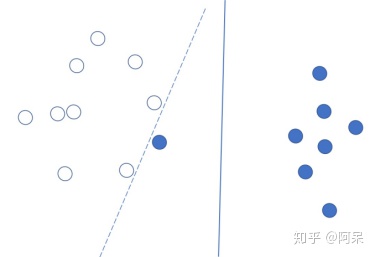
2.1 异常值处理
在处理数据时,可能会遇到在划分好的领域中出现了一两个异常值的情况:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 278
278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









