






 本文探讨了前端路由的发展历程,从后端实现到局部刷新视图的转变,重点介绍了hash和history两种主流路由实现方式。详细解析了hash变化、history API的使用,包括pushState和replaceState的区别,以及popstate事件的应用。
本文探讨了前端路由的发展历程,从后端实现到局部刷新视图的转变,重点介绍了hash和history两种主流路由实现方式。详细解析了hash变化、history API的使用,包括pushState和replaceState的区别,以及popstate事件的应用。
前言:休息了一周,重新再捡起我的知识们,不知道他们有没有想我。
先来写一下之前遇到过几次的一个问题,就是前端历史状态管理和前端路由跳转的问题
早期的路由都是后端实现的,根据url来reload页面,随着页面越来越复杂给后端造成了巨大压力,为了减轻后台压力以及前端用户体验,出现了局部刷新视图的方法ajax,同时给前端路由奠定了基础。通过记录url的变化来记录ajax的变化(ajax的标签化),从而实现前端路由。
通常前端路由的主流实现方式是hash和history两种方式,下面来仔细说明一下。
hash哈希
因为hash变化的url都会被浏览器记录下来,前进、后退都可以用。然后用onhashchange可以监听当hash改变时,对应的后续处理。
window.onload=function(){
window.onhashchange=function(){
console.log(window.location.hash);
}
}
历史状态管理–history
随着history api的到来,前端路由发生了变化,在hash模式中,只能改变#后面的url片段,而history api则给了前端完全的自由
HTML5新增了一个history api,该api允许用户通过js管理浏览器的历史记录,实现无刷新更改浏览器的链接地址,配合history+ajax可以设计不需要刷新页面的跳转
但是history不怕前进后退,就怕刷新,因为刷新是去请求服务器的。
history api可以分为两大部分,切换和修改。
切换包括back、forward、go三个方法对应浏览器的退回、跳转和前进操作。
history.go(-2); //后退两次
history.go(2); //前进两次
history.back(); //后退
修改历史状态包括 pushState和replaceState
这两个方法接收三个参数,stateObj, title, url
history.pushState(stateObj, title, url);
stateObj: 储存JSON字符串,用在popstate事件之中
title:多数浏览器不支持或忽略这个参数,最好用null代替
url:任意有效的url,用于更新浏览器的地址栏,并不在乎url是否存在在地址列表中,不会重新加载页面
pushState和replaceState的区别在于:
pushState()是向history栈中添加一个新的条目,replaceState()是替换掉当前的记录值
他们并不会引起hashchange时间的激活,即使旧的url和新的url只在hash上有区别。
popstate
当前活动历时项(history entry)改变会触发popstate事件,调用pushState和replaceState创建的历史项其popstate事件的state属性会包含历史项和状态对象state的拷贝。
当浏览器触发返回和前进时触发:
window.onpopstate=function(e){
console.log(e.state)
}
例子
例子1:
html代码:
<button id="button">点击我</button>
<p>当前:<span id="num"></span></p>
js代码:
var button=document.getElementById("button");
var num=document.getElementById("num");
var page=0;
button.onclick=function(){
page++;
history.pushState({page:page},null,'?page='+page); //把目标地址推入浏览器历史记录堆栈中
num.innerHTML=page;
}
window.onpopstate=function(e){
if(e.state){
num.innerHTML=e.state.page;
}else{
num.innerHTML=0;
}
console.log(window.history.length);
}
效果
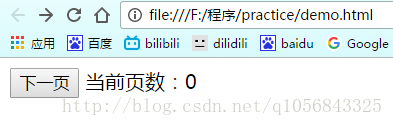
要实现点击下一页,然后当前页数对应增加
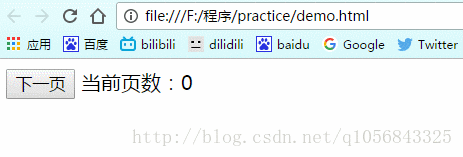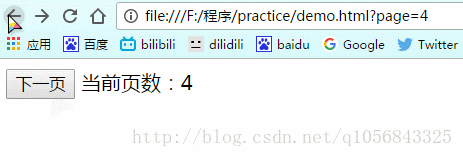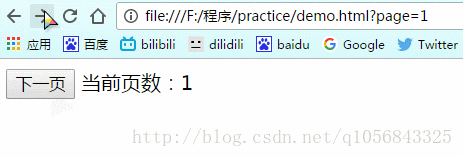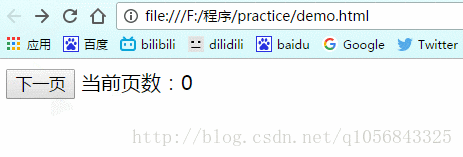
当点击“后退”按钮回到最开始时(第0页)
因为没有状态,所以e.state值为null
例子2
在HTML5之前,使用js实现在浏览器的地址栏中切换url地址,都会触发一个页面刷新的过程,这个过程将大量消耗时间和资源,大多数情况下,这个刷新是没有必要的,会导致重复加载。
h5的history api允许在不刷新页面的前提下,通过js的方式更新页面内容,过程如下:
(1)使用ajax想服务器端请求页面需要更新的信息
(2)使用js加载并显示更新的页面信息
(3)通过history api在不刷新页面的前提下,更新浏览器地址栏中的url地址。
整个处理过程张,页面信息得到更新,浏览器地址栏也发生变化,但是页面并没有被刷新,实际上,history api的诞生主要任务就是为了解决ajax技术与浏览器历史记录存在的冲突。
一般history和ajax结合才有价值,一般三个技术要点
- 使用ajax实现网页内容的更新
- 使用history实现浏览器历史记录的更新
- 使用history实时跟踪浏览器的导航响应,当浏览器历史记录发送变化时,页面内容页随之更新
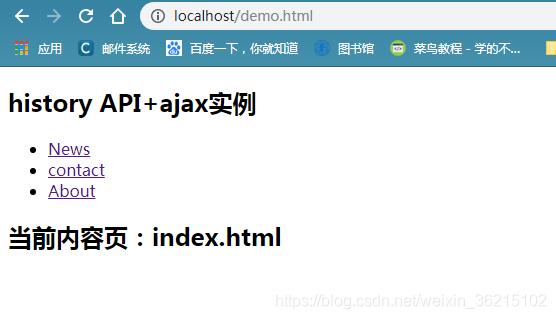
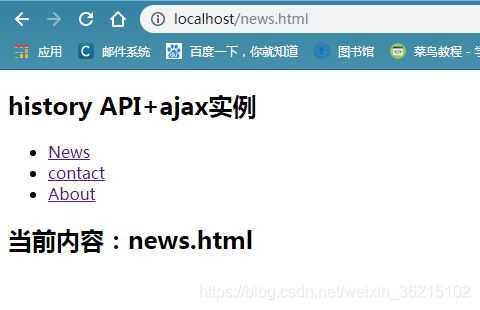
例子:实际无刷新页面导航
如图所示,点击不同的页面,显示不同的内容,而且浏览器中的记录也会变化。
html代码
<h2>history API+ajax实例</h2>
<ul id="menu">
<li><a href="news.html">News</a></li>
<li><a href="contact.html">contact</a></li>
<li><a href="about.html">About</a></li>
</ul>
<div id="content">
<h2>当前内容页:index.html</h2>
</div>
js代码
<script type="text/javascript">
$(document).ready(function() {
$('#menu a').on('click',function(e){
e.preventDefault();
var href=$(this).attr('href');
getContent(href, true);
})
function getContent(url,addEntry){
$.get(url).done(function(data){
$('#content').html(data);
if(addEntry==true){
history.pushState(null,null,url);
//把目标地址推入浏览器历史记录堆栈中
}
})
}
window.addEventListener('popstate', function(e){
getContent(location.pathname,false);
}, false)
});
</script>
效果:
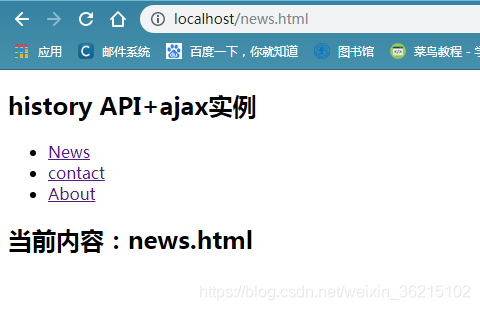
依次点击news、contact,观察页面地址变化,前进后退按钮,观察页面变化
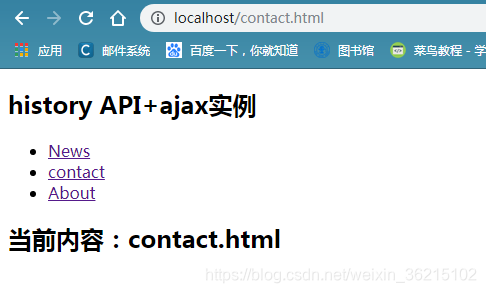
点击后退
后记:文章写得很乱,分了好几天写得,都不知道写的啥


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









