






 本文介绍了Python标准库os模块中的listdir()函数,详细讲解了该函数的用法,并列举了四个在使用过程中需要注意的要点,帮助开发者更好地理解和运用这个常用的库函数。
本文介绍了Python标准库os模块中的listdir()函数,详细讲解了该函数的用法,并列举了四个在使用过程中需要注意的要点,帮助开发者更好地理解和运用这个常用的库函数。
好消息:“Python小屋”编程比赛正式开始
推荐图书:
《Python程序设计(第3版)》,(ISBN:978-7-302-55083-9),董付国,清华大学出版社,2020年6月第1次印刷,8月第4次印刷

=======================
标准库函数os.listdir()是在文件操作和文件遍历时常用的函数之一,用来获取指定文件夹中的所有文件和子文件夹名称组成的列表,完整语法为:listdir(path=None)os.listdir()函数在使用时应注意以下几个问题:1)函数参数path的值可以是字符串或字节串,如果使用字符串指定文件夹则返回的列表中都是字符串形式的文件和子文件夹名字,如果使用字节串指定文件夹则返回的列表中都是字节串形式(UTF-8编码)的文件和子文件夹名字,如果不指定参数则默认返回当前文件夹中的文件和子文件夹名字。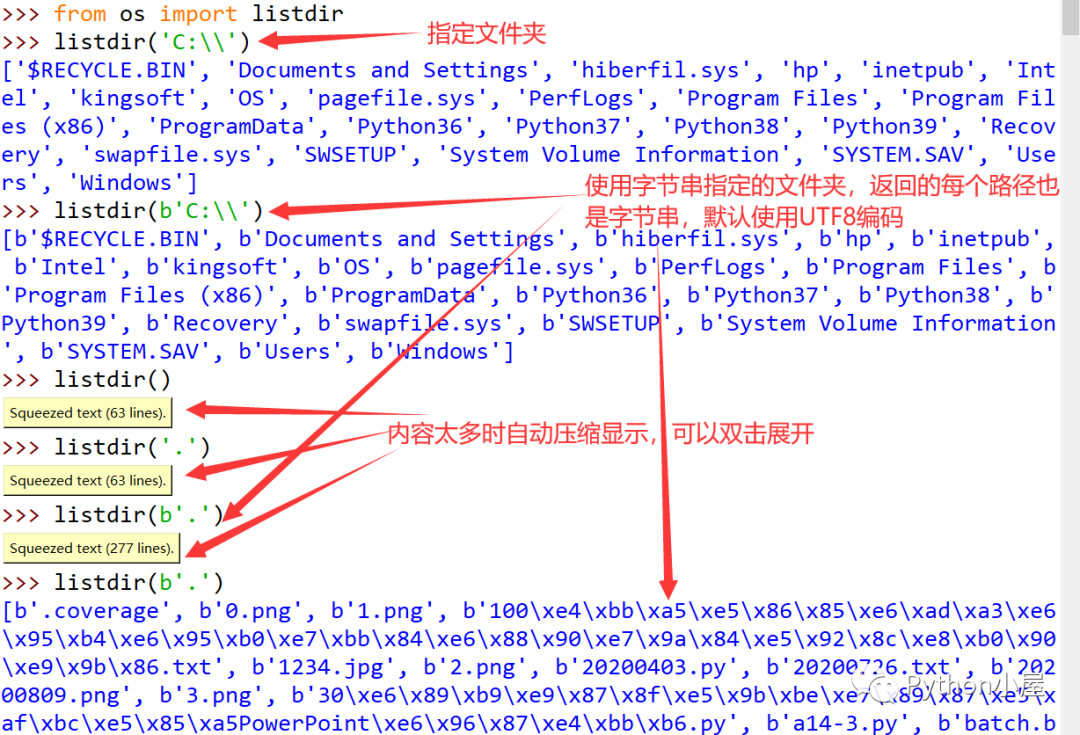 2)如果指定的文件夹中包含子文件夹,listdir()函数返回的列表中不包含子文件夹中的内容。如果需要遍历子文件夹中的内容,可以使用深度优先或广度优先遍历目录树的方法,详见:Python使用广度优先和深度优先两种方法遍历目录树3)listdir(path)函数返回的列表中的路径都是相对于参数path的相对路径,如果参数path不是当前文件夹,那么listdir(path)返回的列表中的路径都无法直接访问。
2)如果指定的文件夹中包含子文件夹,listdir()函数返回的列表中不包含子文件夹中的内容。如果需要遍历子文件夹中的内容,可以使用深度优先或广度优先遍历目录树的方法,详见:Python使用广度优先和深度优先两种方法遍历目录树3)listdir(path)函数返回的列表中的路径都是相对于参数path的相对路径,如果参数path不是当前文件夹,那么listdir(path)返回的列表中的路径都无法直接访问。 4)listdir()函数返回的列表中的字符串是“乱序”的,大致来说,是按字符串转换为大写或小写之后的Unicode编码升序排序的,与我们习惯的按数字、拼音或字母顺序不一样。如果需要的话(例如按文件名编号升序排序后导入其他文件或系统),可以对列表中的字符串进行排序之后再使用。假设Python安装目录中有test子文件夹,内容如下(随机生成文件名):
4)listdir()函数返回的列表中的字符串是“乱序”的,大致来说,是按字符串转换为大写或小写之后的Unicode编码升序排序的,与我们习惯的按数字、拼音或字母顺序不一样。如果需要的话(例如按文件名编号升序排序后导入其他文件或系统),可以对列表中的字符串进行排序之后再使用。假设Python安装目录中有test子文件夹,内容如下(随机生成文件名):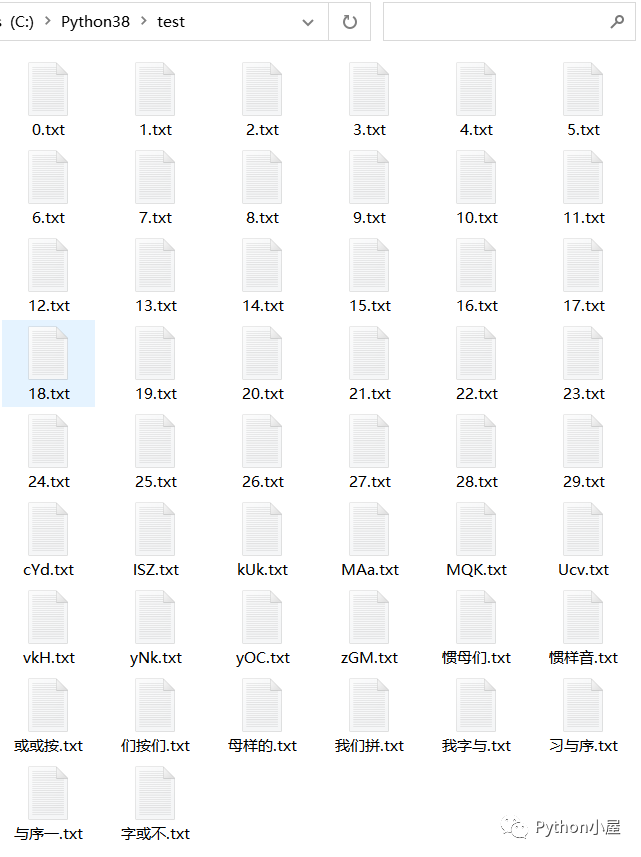 使用listdir()函数获取其中文件名以及不同排序规则显示效果演示如下:
使用listdir()函数获取其中文件名以及不同排序规则显示效果演示如下: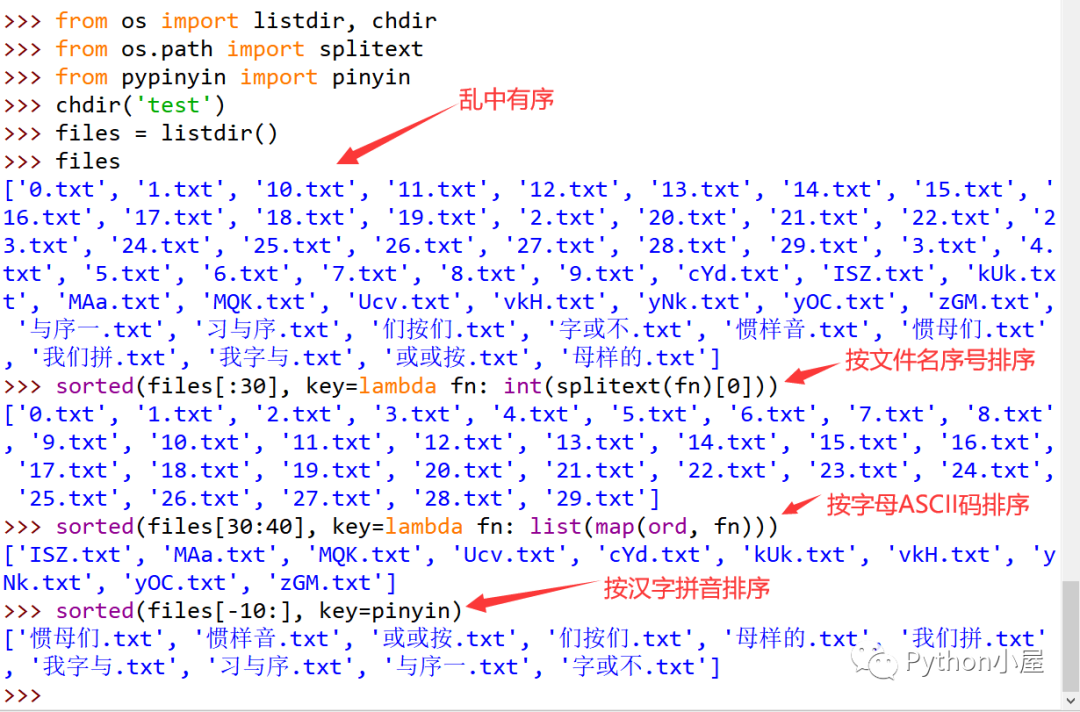 温馨提示:关注微信公众号“Python小屋”,在公众号后台发送消息“大事记”可以查看董付国老师与Python有关的重要事件;发送消息“教材”可以查看董付国老师出版的Python系列教材(已累计印刷超过100次)的适用专业详情;发送消息“历史文章”可以查看董付国老师推送的超过1000篇原创技术文章;发送消息“会议”或“培训”可以查看近期董付国老师的培训安排;发送消息“微课”可以查看董付国老师免费分享的超过500节Python微课视频;发送消息“课件”可以查看董付国老师免费分享的Python教学资源;发送消息“小屋刷题”可以下载“Python小屋刷题神器”,免费练习1187道客观题和118道编程题,题库持续更新;发送消息“编程比赛”了解Python小屋编程大赛详情。
温馨提示:关注微信公众号“Python小屋”,在公众号后台发送消息“大事记”可以查看董付国老师与Python有关的重要事件;发送消息“教材”可以查看董付国老师出版的Python系列教材(已累计印刷超过100次)的适用专业详情;发送消息“历史文章”可以查看董付国老师推送的超过1000篇原创技术文章;发送消息“会议”或“培训”可以查看近期董付国老师的培训安排;发送消息“微课”可以查看董付国老师免费分享的超过500节Python微课视频;发送消息“课件”可以查看董付国老师免费分享的Python教学资源;发送消息“小屋刷题”可以下载“Python小屋刷题神器”,免费练习1187道客观题和118道编程题,题库持续更新;发送消息“编程比赛”了解Python小屋编程大赛详情。
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









