







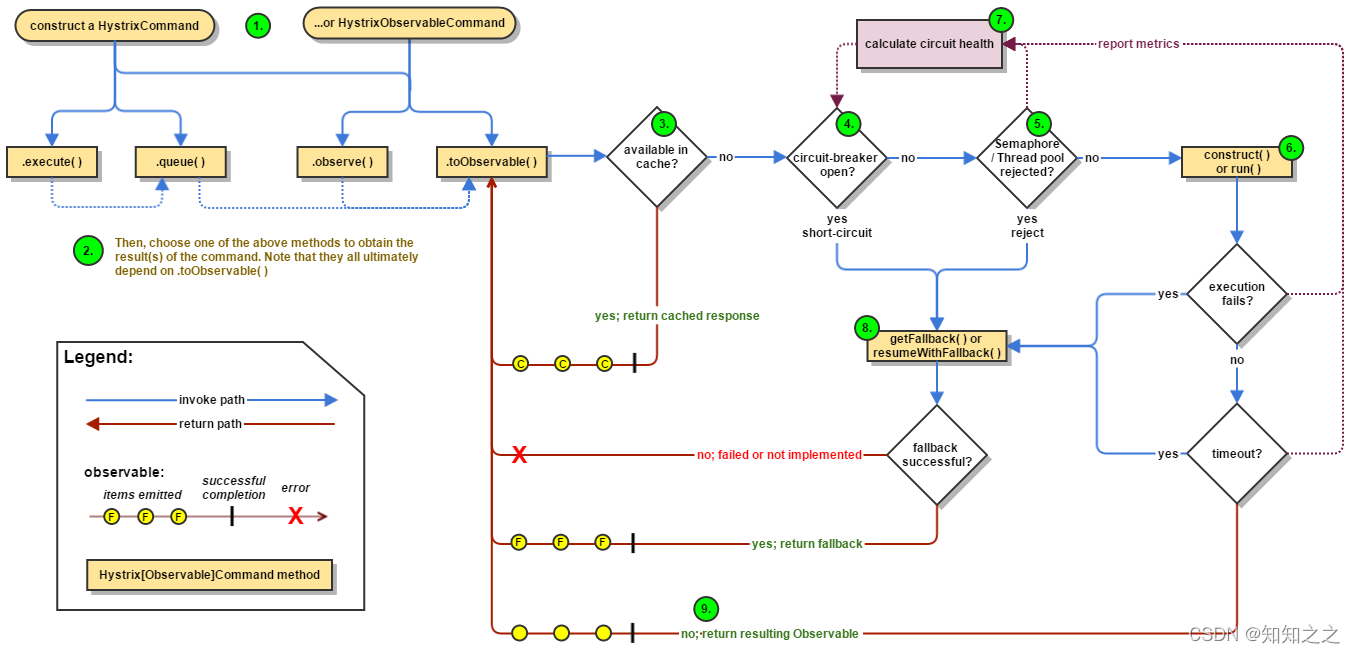
工作流程
默认超时时间为1秒
- 创建HystrixCommand或HystrixObservableCommand对象,用来表示对依赖服务的操作请求,同时传递所有需要的参数
- 执行命令;execute():同步执行;queue():异步执行,直接返回一个Future对象
- 结果是否被缓存;若当前命令的请求缓存功能是被启用的,并且该命令缓存命中,那么缓存的结果会立即返回
- 断路器是否打开;在命令结果没有命中缓存的时候,Hystrix在执行命令需要检查断路器是否为打开状态,如果断路器是打开状态,那么Hystrix不会执行命令,而是转接到fallback处理逻辑;如果断路器是关闭状态,那么Hystrix跳到第5步,检查是否有资源来执行命令。
- 线程池、请求队列、信号量是否占满;如果与命令相关的线程池、请求队列、信号量已经被占满时,那么Hystrix不会执行命令,而是转接到fallback处理逻辑
- 执行run()或者construct()
- 计算断路器的健康度;Hystrix会将成功、失败、拒绝、超时等信息报告给断路器,而断路器会维护一组计数器来统计这些数据,断路器会使用这些数据来决定是否将断路器打开,来对某个依赖服务的请求进行熔断或者短路,直到恢复期结束,若在恢复期结束后,根据统计数据判断如果还是未达到健康指标,就再次熔断或者短路
- fallback处理;当命令执行失败的时候,Hystrix会进入fallback尝试回退处理,通常称之为服务降级
- 返回成功结果
依赖隔离
线程隔离
Hystrix会为每一个依赖服务创建一个独立的线程池,这样就算某个依赖服务出现延迟过高的情况,也只是对该依赖服务的调用产生影响,而不会拖慢其他的依赖服务
- 应用自身得到保护,不会受不可控的依赖服务影响
- 有效降低新服务的风险,如果新服务接入后运行不稳定或者存在问题,完全不会影响应用其他的请求
- 可以利用他为同步依赖的服务构建异步访问
- 为系统带来额外的开销,但是线程池上的开销相对于隔离带来的好处是无法比拟的
适用场景:适合绝大多数的场景,对依赖服务的网络调用timeout,TPS要求高的
信号量隔离
- 请求线程和调用provider线程是同一条线程
- 信号量的开销远比线程池的开销要小很多
- 但是不能设置超时和实现异步访问
- 只有在依赖服务是足够可靠的情况下才会使用信号量
主要适用场景: 并发需求不大的依赖调用(因为如果并发需求较大,相应的信号量的数量就要设置得够大,因为Tomcat线程与处理线程为同一个线程,那么这个依赖调用就会占用过多的Tomcat线程资源,有可能会影响到其他服务的接收)
熔断器工作原理
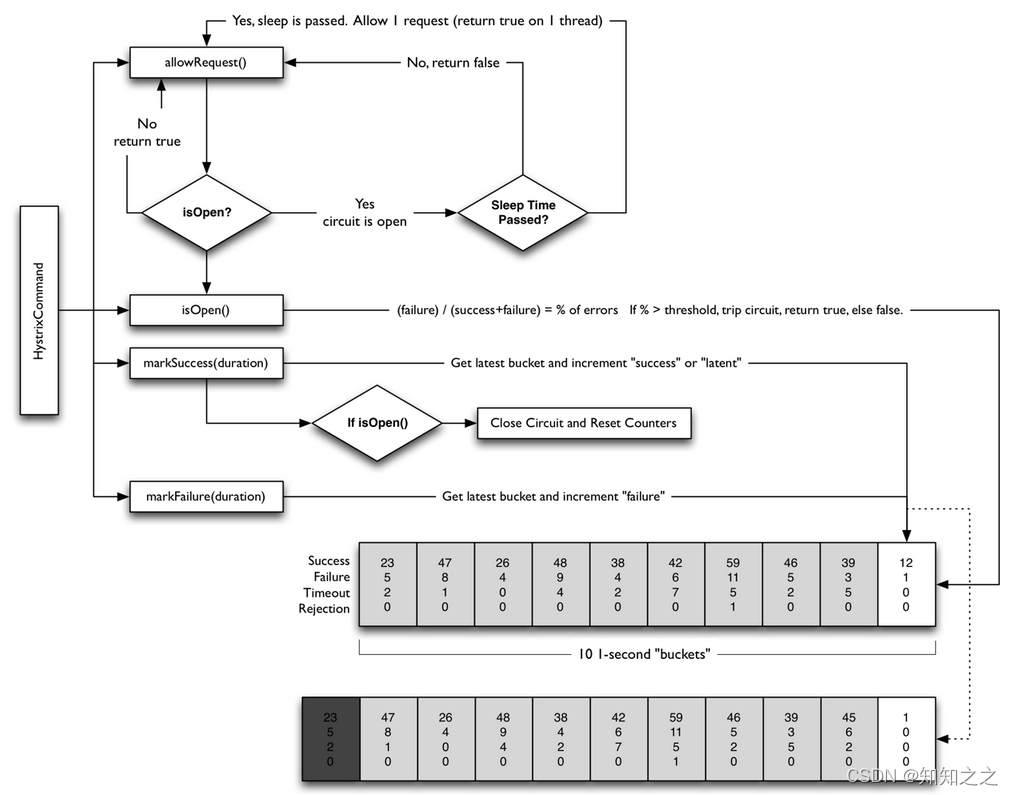
Hytrix熔断器流程
- 如果熔断器打开标识为true,则直接返回true,表示熔断器处于打开状态。否则,就从度量指标对象metrics中获取HealthCounts统计对象进一步判断(该对象记录了一个滚动时间窗内的 信息快照,默认时间窗为10秒)
- 如果在一个时间窗口内它的请求总数在预设的阈值范围内就返回false,默认值为20
- 如果在一个时间窗口内错误百分比在阈值范围内就返回false,默认值为50
- 如果以上两种条件都没有达到,则将熔断器状态设置为关闭状态,并记录时间
- 如果熔断器状态为open,在等待一个睡眠时间窗口后,下一个请求被允许通过,这时候熔断器的状态是half-open状态,如果这个请求失败,熔断器在睡眠时间窗口状态依然是open,如果这个请求成功 那么熔断器状态切换为close。
服务雪崩
"服务雪崩",在微服务架构中,通常指的是一个微小的问题导致一连串模块或服务的故障,如同雪崩一样,起初只是小范围的雪崩,但最终可能会引发整个系统的瘫痪。
一种常见的服务雪崩场景是:当一个微服务因为网络延迟或者是过载等引起响应变慢或者失效,其上游的服务由于等待该服务响应而阻塞,这种情况下请求会迅速积压,造成大量的线程或进程阻塞,导致服务资源耗尽,最后导致该服务失效。而这种情况又会向上游服务蔓延,形成链式反应,最终可能引起整个系统的瘫痪。
那么,如何防止服务雪崩的发生呢?下面是一些常用的策略:
1.超时机制:为每个服务调用设置合理的超时时间。当调用的服务在规定的时间内无法完成请求处理,上游服务就会中断请求,释放线程或者进程资源。
2.熔断机制:当服务熔断器检测到下游服务调用问题时,会自动中断对问题服务的调用,转而调用预设的回退逻辑。
3.限流机制:限制系统的输入,防止过多的请求一次性涌入系统,导致系统资源耗尽。
4.负载均衡:通过负载均衡策略把请求分发到多个服务实例上,从而防止单一服务实例成为瓶颈。
5.隔离机制:为不同的服务调用路径提供隔离的运行环境,防止故障在不同的服务间蔓延。
6.服务降级:当系统压力过大时,暂时关闭一些非核心的服务功能,释放更多资源供核心功能使用。
通过这些策略的应用和优化,我们可以有效地防止服务雪崩的发生。当然,除了做好以上策略以外,我们还需要做好服务监控和日志记录,这样才能在出现问题时及时发现并排查问题,防止问题的进一步扩大。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









