




 特征编码在机器学习中起到关键作用,它能处理非量化数据,构造细粒度特征,但也可能导致其他重要特征被忽视,尤其是在高维数据场景下。无监督与有监督编码的区别在于是否依赖其他特征,而编码唯一性涉及是否引入随机性。在模型训练前的编码步骤对于模型性能有直接影响。
特征编码在机器学习中起到关键作用,它能处理非量化数据,构造细粒度特征,但也可能导致其他重要特征被忽视,尤其是在高维数据场景下。无监督与有监督编码的区别在于是否依赖其他特征,而编码唯一性涉及是否引入随机性。在模型训练前的编码步骤对于模型性能有直接影响。
对特征编码有助于:
- 处理无法量化的数据
- 便于得到更优模型
- 以更细粒度的处理我们的数据
博主在学习中觉得,特征编码既是一种优势,又是一种束缚
- 优势在于:同样是年龄这个维度,如果是在研究奶粉的问题中,我们拆解问题的粒度需要到:0-1个月,1-3个月,3-6个月,6-12个月…,但是研究青少年焦虑的问题时,就需要另一种编码方法,因此手动进行编码可以构造更细粒度的特征。
- 束缚在于:编码其实是构造特征的一种,因此编码会放大某个维度的粒度,其他即便很重要的特征也会被掩盖光芒。尤其当数据维度太大时(常见于推荐系统维度灾难),不得不会对所有离散数据进行再次的整合与编码,这时影响会更加严重。
后续,我们参考这样的表格来进行编码学习:
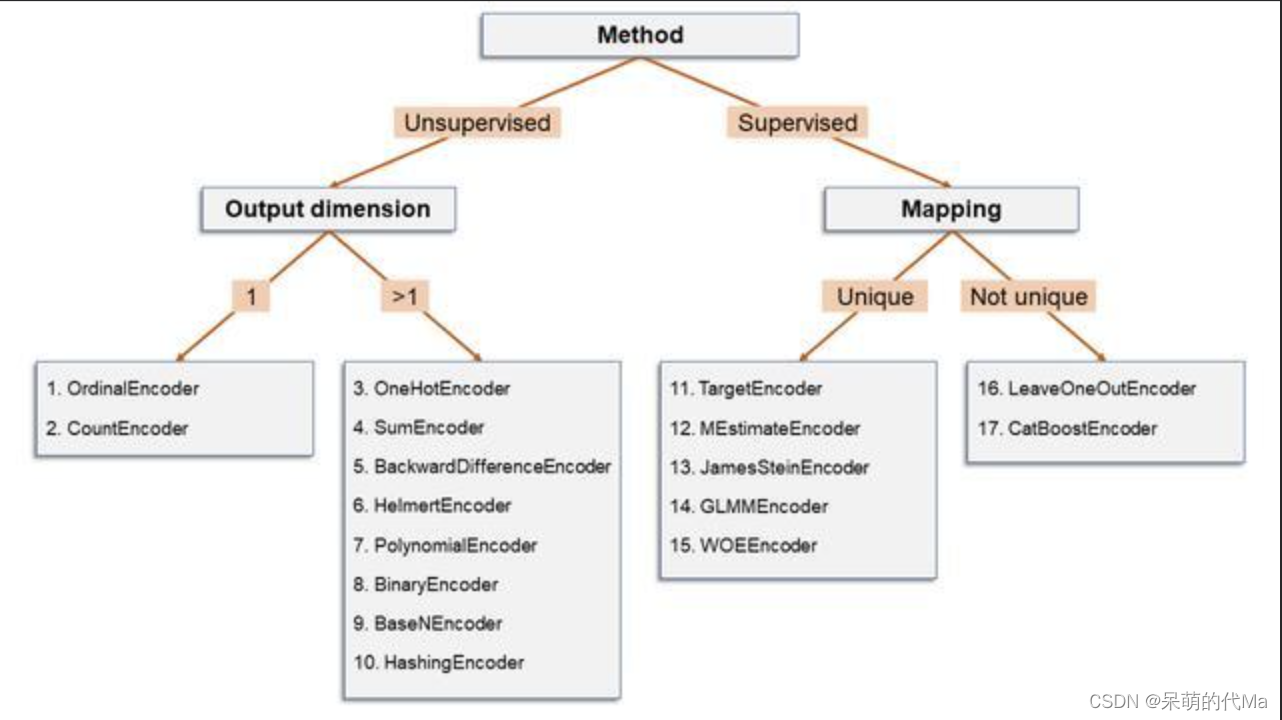
上图将编码的类型分为4类:
- 无监督,输出1维
- 无监督,输出多维
- 有监督,输出编码唯一
- 有监督,输出编码不唯一
无监督与有监督的区别是:
- 无监督是对自己的数据,无需参考其他特征
- 有监督需要参考其他维度(通常参考需要预测的那个维度的数据),对自己进行编码
输出编码是否唯一的区别是:
- 唯一:编码过程中不涉及随机性
- 不唯一:编码过程存在随机采样的情况,如果不设置随机种子,编码结果不唯一
在很多机器学习模型中,有很多模型都是先编码再训练的,在后续拓展时会简要介绍



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











