







预备知识
1 jensen不等式
回顾优化理论中的一些概念。设f是定义域为实数的函数,如果对于所有的实数x,![]() ,那么f是凸函数。当x是向量时,如果其hessian矩阵H是半正定的(
,那么f是凸函数。当x是向量时,如果其hessian矩阵H是半正定的(![]() ),那么f是凸函数。如果
),那么f是凸函数。如果![]() 或者
或者![]() ,那么称f是严格凸函数。
,那么称f是严格凸函数。
Jensen不等式表述如下:
如果f是凸函数,X是随机变量,那么
![]()
特别地,如果f是严格凸函数,那么![]() 当且仅当
当且仅当![]() ,也就是说X是常量。
,也就是说X是常量。
这里我们将![]() 简写为
简写为![]() 。
。
如果用图表示会很清晰:

图中,实线f是凸函数,X是随机变量,有0.5的概率是a,有0.5的概率是b。(就像掷硬币一样)。X的期望值就是a和b的中值了,图中可以看到![]() 成立。
成立。
当f是(严格)凹函数当且仅当-f是(严格)凸函数。
Jensen不等式应用于凹函数时,不等号方向反向,也就是![]() 。
。
当且仅当X为常数,等号成立。
EM算法
推导过程
(1)
令Qi表示隐含变量Z的某种分布,Qi满足的条件是。
(1)式变换为
(2)
根据数学期望公式:。
有:,(2)式中
是
的数学期望。
(3)
根据Jensen不等式:
是凹函数,
,
(4)
(5)
(5)
(5)式是参数的对数似然函数的下界。
等式成立的条件
根据Jensen不等式,,当且仅当x为常数时,等号成立。和
,有:
、
又有
EM算法流程
初始化分布参数;重复E、M步骤直到收敛
E-step:选择隐含变量的概率分布
M-step:\
EM算法收敛性
那么究竟怎么确保EM收敛?假定![]() 和
和![]() 是EM第t次和t+1次迭代后的结果。如果我们证明了
是EM第t次和t+1次迭代后的结果。如果我们证明了![]() ,也就是说极大似然估计单调增加,那么最终我们会到达最大似然估计的最大值。下面来证明,选定
,也就是说极大似然估计单调增加,那么最终我们会到达最大似然估计的最大值。下面来证明,选定![]() 后,我们得到E步
后,我们得到E步
![]()
这一步保证了在给定![]() 时,Jensen不等式中的等式成立,也就是
时,Jensen不等式中的等式成立,也就是
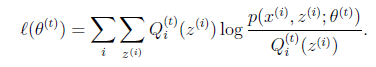
然后进行M步,固定![]() ,并将
,并将![]() 视作变量,对上面的
视作变量,对上面的![]() 求导后,得到
求导后,得到![]() ,这样经过一些推导会有以下式子成立:
,这样经过一些推导会有以下式子成立:
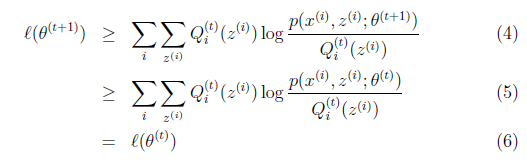
解释第(4)步,得到![]() 时,只是最大化
时,只是最大化![]() ,也就是
,也就是![]() 的下界,而没有使等式成立,等式成立只有是在固定
的下界,而没有使等式成立,等式成立只有是在固定![]() ,并按E步得到
,并按E步得到![]() 时才能成立。
时才能成立。
况且根据我们前面得到的下式,对于所有的![]() 和
和![]() 都成立
都成立
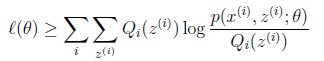
第(5)步利用了M步的定义,M步就是将![]() 调整到
调整到![]() ,使得下界最大化。因此(5)成立,(6)是之前的等式结果。
,使得下界最大化。因此(5)成立,(6)是之前的等式结果。
这样就证明了![]() 会单调增加。一种收敛方法是
会单调增加。一种收敛方法是![]() 不再变化,还有一种就是变化幅度很小。
不再变化,还有一种就是变化幅度很小。
再次解释一下(4)、(5)、(6)。首先(4)对所有的参数都满足,而其等式成立条件只是在固定![]() ,并调整好Q时成立,而第(4)步只是固定Q,调整
,并调整好Q时成立,而第(4)步只是固定Q,调整![]() ,不能保证等式一定成立。(4)到(5)就是M步的定义,(5)到(6)是前面E步所保证等式成立条件。也就是说E步会将下界拉到与
,不能保证等式一定成立。(4)到(5)就是M步的定义,(5)到(6)是前面E步所保证等式成立条件。也就是说E步会将下界拉到与![]() 一个特定值(这里
一个特定值(这里![]() )一样的高度,而此时发现下界仍然可以上升,因此经过M步后,下界又被拉升,但达不到与
)一样的高度,而此时发现下界仍然可以上升,因此经过M步后,下界又被拉升,但达不到与![]() 另外一个特定值一样的高度,之后E步又将下界拉到与这个特定值一样的高度,重复下去,直到最大值。
另外一个特定值一样的高度,之后E步又将下界拉到与这个特定值一样的高度,重复下去,直到最大值。

















 337
337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









