






 博主实测发现,从浏览器到Python库(bs4)抓取网页时,属性顺序发生变化。通过requests、urllib和BeautifulSoup抓取'page3.html'的实例,展示了不同库对HTML结构处理的差异。
博主实测发现,从浏览器到Python库(bs4)抓取网页时,属性顺序发生变化。通过requests、urllib和BeautifulSoup抓取'page3.html'的实例,展示了不同库对HTML结构处理的差异。
伊谢尔伦2017-04-18 09:33:414楼
经过实测,结论是 bs4 改变了属性的顺序。
1、在浏览器中右键点击页面,选:
审查元素
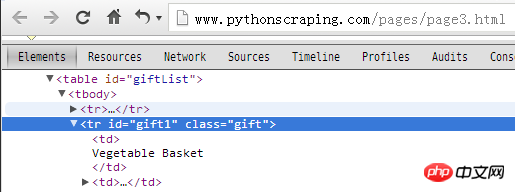
查看网页源码

2、在 python3 程序中对比:
import re
ptn_tr = re.compile(r'
]+>')import requests as req
rsp=req.get('http://www.pythonscraping.com/pages/page3.html')
html = rsp.text
print('requests:\t', ptn_tr.findall(html)[0])
from urllib.request import urlopen
rsp = urlopen("http://www.pythonscraping.com/pages/page3.html")
html = rsp.read().decode()
print('urlopen:\t', ptn_tr.findall(html)[0])
from bs4 import BeautifulSoup
html = str(BeautifulSoup(html,"lxml"))
print('bs4Soup:\t', ptn_tr.findall(html)[0])
结果:
requests:
urlopen:
bs4Soup:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









