






 本文详细解析了Java内存模型(JMM)的基本概念,包括内存可见性、重排序问题及synchronized、volatile和final的关键作用机制。并通过具体示例阐述了这些机制如何保障线程间的数据一致性。
本文详细解析了Java内存模型(JMM)的基本概念,包括内存可见性、重排序问题及synchronized、volatile和final的关键作用机制。并通过具体示例阐述了这些机制如何保障线程间的数据一致性。
在面试之时,很多面试官都喜欢问道,JMM清楚吗?说说什么是内存可见性,什么是重排序?synchronized、volatile和final中的原理?等等诸如此类的问题。而网上一搜,巴啦啦一大堆,东西比较乱,也很难把面试官变相问题回答清楚。终于,下定决心给大家捋一捋 JAVA 简化版的内存模型。
1、绪论。
Java的并发采用的是共享内存模型,Java线程之间的通信总是隐式的,整个通信过程对 程序员 来说完全是透明的。
2、JMM简述。
JMM是Java内存模型,它决定了一个线程对共享变量的写入何时对另一个线程可见。从抽象的角度看,JMM定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存(Main Memory)中,每个线程都有一个抽象的(真实不存在的)本地内存(Local Memory),本地内存存储了该线程以读、写共享变量的副本。
知识点补充:(上述JMM所说的"共享变量"主要存在于java堆中)
JVM内存模型包括:
(1) 程序计数器。一块很小的内存空间,用于记录下一条要运行的指令。是线程私有的内存。
(2)java虚拟机栈。它和java线程同一时间创建,保存了局部变量、部分结果,并参与方法的调用和返回。是线程私有的内存。
(3)本地方法栈。它和java虚拟机栈的功能相似,主要为Native方法服务。是线程私有的内存。
(4)java堆。为所有创建的对象和数组分配内存空间。是线程共有的内存。
(5)方法区。也被称为永久区,与堆空间相似。是线程共有的内存。
复制代码
3、JMM中的重排序。
在执行程序时,为了提高性能,编译器和处理器常常会对指令做重排序。然而在程序最终执行之前,还要做一个内存的重排序。
重排序可能会导致多线程程序出现内存可见性问题。请看代码例子:
class ReorderEample {
int a = 0;
boolean flag = false;
//写操作
public void writer() {
a = 1 ; // (1)
flag = true; //(2)
}
//读操作
public void reader() {
if (flag) { //(3)
int i = a * a; //(4)
// 处理逻辑
}
}
}
复制代码
flag变量是个标记,标识a是否已被写入。假设有两个线程A和B,A首先执行了写操作writer(),随后B接着执行读操作reader()方法。那么线程B在执行操作(4)时,是否能看到线程A在操作(1)时对共享变量a的写入?答案是未必能看到。因为在重排序时,A线程可能先标识了flag变量,再对a变量进行写入,但是在它们发生之间,B线程此时来读了,该程序的语义被破坏了。如下程序执行时序图:
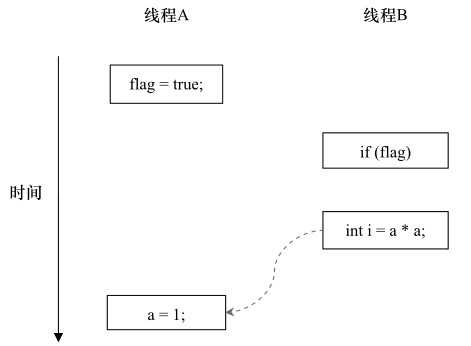
4、volatile的内存语义
JMM中,被声明成volatile的共享变量,线程通过排他锁获取这个变量,确保在线程中是可见的。为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入 内存屏障 来禁止特定类型的处理器重排序。了解内存屏障详情请看 Java内存模型Cookbook(二)内存屏障
4.1、volatile的特性
可见性。对一个volatile变量的读取,总能看到(任意线程)对这个volatile变量最后的写入。
原子性。对任意单个volatile变量的读/写具有原子性。但对于多个volatile操作或类型volatile++这种复合操作不具有原子性。
4.2、volatile解决重排序问题
volatile遵循happens-before原则。请看如下代码:
class ReorderEample {
int a = 0;
volatile boolean flag = false;
//写操作
public void writer() {
a = 1 ; // (1)
flag = true; //(2)
}
//读操作
public void reader() {
if (flag) { //(3)
int i = a * a; //(4)
// 处理逻辑
}
}
}
复制代码
假设线程A执行writer()方法之后,线程B执行reader()方法。根据happens-before原则,这个过程建立的happens-before关系分为3类:
根据程序次序规则,(1) happens-before (2) ; (3) happens-before (4)。
根据volatile规则,(2) happens-before (3).
根据happens-before的传递性规则,(1) happens-before (4)。
其happens-before建立关系图如下:
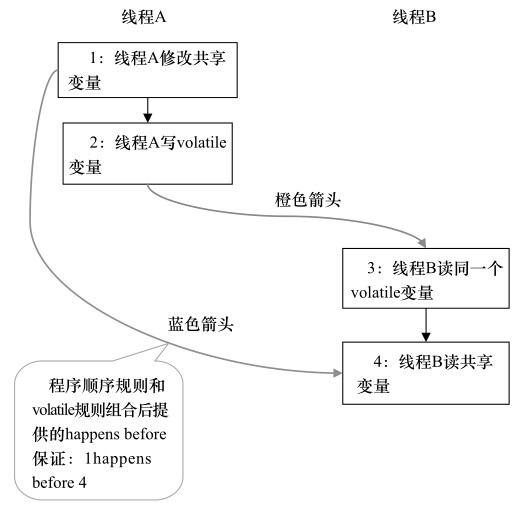
对于上一个例子来说,这个例子只对flag变量增加了volatile声明。A线程写入一个volatile变量后,B线程读同一个volatile变量。A线程在写volatile变量之前所有可见的共享变量,在B线程读同一个volatile变量后,立即对B线程可见。
happens-before规则知识点补充:
(1)程序顺序规则:一个线程中的每个操作,happens-before于该线程中的任意后续操作
(2)监视器锁规则:对一个线程的解锁,happens-before于随后对这个线程的加锁
(3)volatile变量规则:对一个volatile域的写,happens-before于后续对这个volatile域的读
(4)传递性:如果A happens-before B ,且 B happens-before C, 那么 A happens-before C
(5)start()规则:如果线程A执行操作ThreadB_start()(启动线程B) , 那么A线程的ThreadB_start()happens-before 于B中的任意操作
(6)join()原则:如果A执行ThreadB.join()并且成功返回,那么线程B中的任意操作happens-before于线程A从ThreadB.join()操作成功返回。
(7)interrupt()原则: 对线程interrupt()方法的调用先行发生于被中断线程代码检测到中断事件的发生,可以通过Thread.interrupted()方法检测是否有中断发生
(8)finalize()原则:一个对象的初始化完成先行发生于它的finalize()方法的开始。
复制代码
5、synchronized的内存语义
synchronized内存语义与volatile内存语义类似,在Java并发编程机制中,锁除了让临界区互斥之外,还可以让释放锁的线程向获取同一个锁的线程发送消息。它的核心底层就是使用一个volatile声明的state变量来维护同步状态。
5.1、synchronized解决重排序问题
锁也遵循happens-before规则。请看如下代码:
class MonitorExample{
int a = 0;
//写操作
public synchronized void writer() { //(1)
a ++; //(2)
} //(3)
//读操作
public synchronized void reader() { //(4)
int i = a; //(5)
//处理逻辑
} //(6)
}
复制代码
假设线程A执行writer()方法,随后线程B执行reader()方法。根据happens-before规则,这个过程包含的happens-before关系可以分为3类:
根据程序次序规则,(1) happens-before (2),(2) happens-before (3),(4) happens-before (5),(5) happens-before (6)。
根据监视器锁规则,(3) happens-before (4)。
根据传递性规则,(2) happens-before (5)。
其happens-before建立关系图如下:
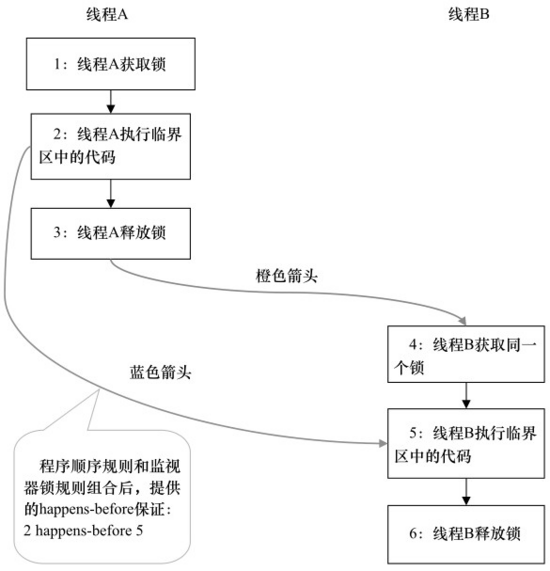
线程A释放了锁之后,随后线程B获取同一个锁。因为 (2) happens-before (5),所以线程A在释放锁之前所有可见的共享变量在线程B获取同一个锁之后对于B线程都变得可见。
6、final的内存语义
在JMM中,通过 内存屏障 禁止编译器把final域的写重排序到构造函数之外。因此,在对象引用为任意线程可见之前,对象的final域已经被正确初始化(不为null的情况)了。 对于final域,编译器和处理器遵循两个重排序规则:
在构造函数内对一个final域的写入,与随后把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。
初次读一个包含final域的对象的医用,与随后初次读这个final域,这两个操作之间不能重排序。
下面通过两个示例来说明这两个规则。
6.1、示例一
public class FinalExample {
int i; //普通变量
final int j; //final变量
static FinalExample obj;
public FinalExample(int j) { //构造函数
i = 1; //写普通域
this.j = j; //写final域
}
public static void writer() { //写线程A执行
obj = new FinalExample(2);
}
public static void reader() { //读线程B执行
FinalExample object = obj; //读引用对象
int a = object.i; //读普通域
int b = object.j; //读final域
}
}
复制代码
写普通域的操作被编译器重排序到了构造函数之外,读线程B错误地读取了普通变量i初始化之前的值。而写final域操作后,被写final域的重排序规则“限定”在了构造函数之内,读线程B正确地读取了final变量初始化的值。执行时序图如下:
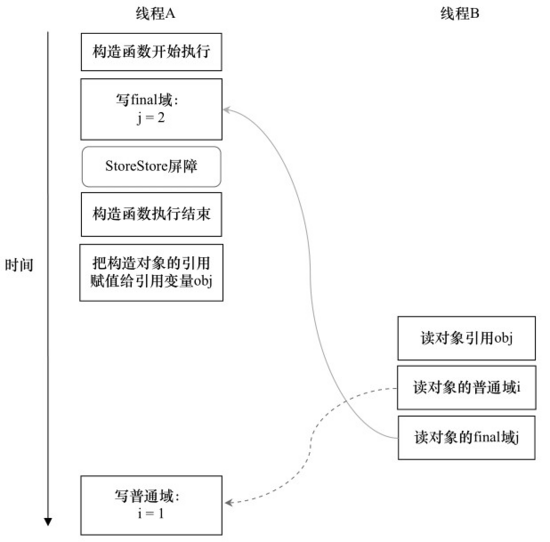
6.2 示例二
public class FinalReferenceExample {
final int[] intArray;
static FinalReferenceExample obj;
public FinalReferenceExample() { //构造函数
intArray = new int[1]; //(1)
intArray[0] = 1; //(2)
}
public static void writeOne() { //写线程A执行
obj = new FinalReferenceExample(); //(3)
}
public static void writeTwo() { //写线程B执行
obj.intArray[0] = 2; //(4)
}
public static void reader () { //读线程C执行
if (obj != null) { //(5)
int temp = obj.intArray[0]; //(6)
}
}
}
复制代码
首先线程A执行writeOne()方法,执行完后线程B执行writeTwo方法,执行完后线程C执行reader方法。操作(1)对final域的写入,操作(2)是对final域引用的对象的成员写入,操作(3)是把被构造的对象的引用赋值给某个引用变量。这里除了(1)和(3)不能重排序,(2)和(3)也不能重排序。因此,该程序的线程执行时序不可知,因为写线程B和读线程C之间存在数据竞争。
参考:《Java并发编程的艺术》 方腾飞 魏鹏 程晓明 《深入理解Java虚拟机》 周志明
如果这篇文章对你有用,请你点个赞吧!你的支持是我分享的动力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









