







 本文介绍了如何使用PyTorch实现矩阵分解进行协同过滤,以构建动漫推荐系统。通过分析Kaggle上的动画推荐数据集,进行数据预处理,然后运用随机初始化的嵌入权重进行梯度下降训练,最终解决冷启动问题并探讨了矩阵分解的局限性。
本文介绍了如何使用PyTorch实现矩阵分解进行协同过滤,以构建动漫推荐系统。通过分析Kaggle上的动画推荐数据集,进行数据预处理,然后运用随机初始化的嵌入权重进行梯度下降训练,最终解决冷启动问题并探讨了矩阵分解的局限性。
我们一天会遇到很多次推荐——当我们决定在Netflix/Youtube上看什么,购物网站上的商品推荐,Spotify上的歌曲推荐,Instagram上的朋友推荐,LinkedIn上的工作推荐……列表还在继续!推荐系统的目的是预测用户对某一商品的“评价”或“偏好”。这些评级用于确定用户可能喜欢什么,并提出明智的建议。

推荐系统主要有两种类型:
基于内容的系统:这些系统试图根据项目的内容(类型、颜色等)和用户的个人资料(喜欢、不喜欢、人口统计信息等)来匹配用户。例如,Youtube可能会根据我是一个厨师的事实,以及/或者我过去看过很多烘焙视频来推荐我烹饪视频,从而利用它所拥有的关于视频内容和我个人资料的信息。
协同过滤:他们依赖于相似用户喜欢相似物品的假设。用户和/或项目之间的相似性度量用于提出建议。
本文讨论了一种非常流行的协同过滤技术——矩阵分解。
矩阵分解
推荐系统有两个实体-用户和物品(物品的范围十分广泛,可以是实际出售的产品,也可以是视频,文章等)。假设有m个用户和n个物品。我们推荐系统的目标是构建一个mxn矩阵(称为效用矩阵),它由每个用户-物品对的评级(或偏好)组成。最初,这个矩阵通常非常稀疏,因为我们只对有限数量的用户-物品对进行评级。
这是一个例子。假设我们有4个用户和5个超级英雄,我们试图预测每个用户对每个超级英雄的评价。这是我们的评分矩阵最初的样子:
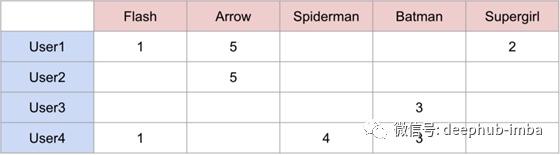
针对超级英雄等级4x5评分矩阵
现在,我们的目标是通过寻找用户和项目之间的相似性来填充这个矩阵。例如,我们看到User3和User4对蝙蝠侠给出了相同的评级,所以我们可以假设用户是相似的,他们对蜘蛛侠的感觉也是一样的,并预测User3会给蜘蛛侠评级为4。然而,在实践中,这并不是那么简单,因为有多个用户与许多不同的项交互。
在实践中,通过将评分矩阵分解成两个高而细的矩阵来填充矩阵。分解得到:
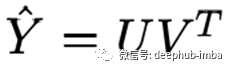
用户-产品对的评分的预测是用户和产品的点积
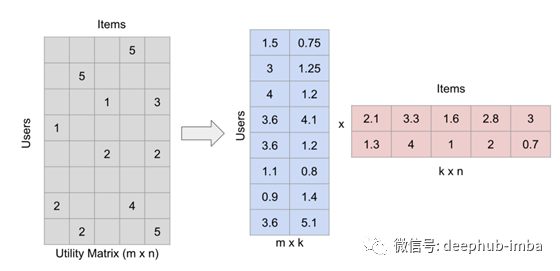
矩阵因式分解(为了方便说明,数字是随机取的)
PyTorch实现
使用PyTorch实现矩阵分解,可以使用PyTorch提供的嵌入层对用户和物品的嵌入矩阵(Embedding)进行分解,利用梯度下降法得到最优分解。
数据集
我使用了来自Kaggle的动画推荐数据集:
https://www.kaggle.com/Co
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









