







 本文介绍了如何在Scrapy爬虫中通过自定义注解和命令行参数来实现动态参数传递。示例展示了如何在启动Scrapy爬虫时指定特定板块,从而实现按需采集内容。通过设置爬虫类的属性,并在运行时通过命令行参数进行传递,可以灵活控制爬虫的行为。
本文介绍了如何在Scrapy爬虫中通过自定义注解和命令行参数来实现动态参数传递。示例展示了如何在启动Scrapy爬虫时指定特定板块,从而实现按需采集内容。通过设置爬虫类的属性,并在运行时通过命令行参数进行传递,可以灵活控制爬虫的行为。
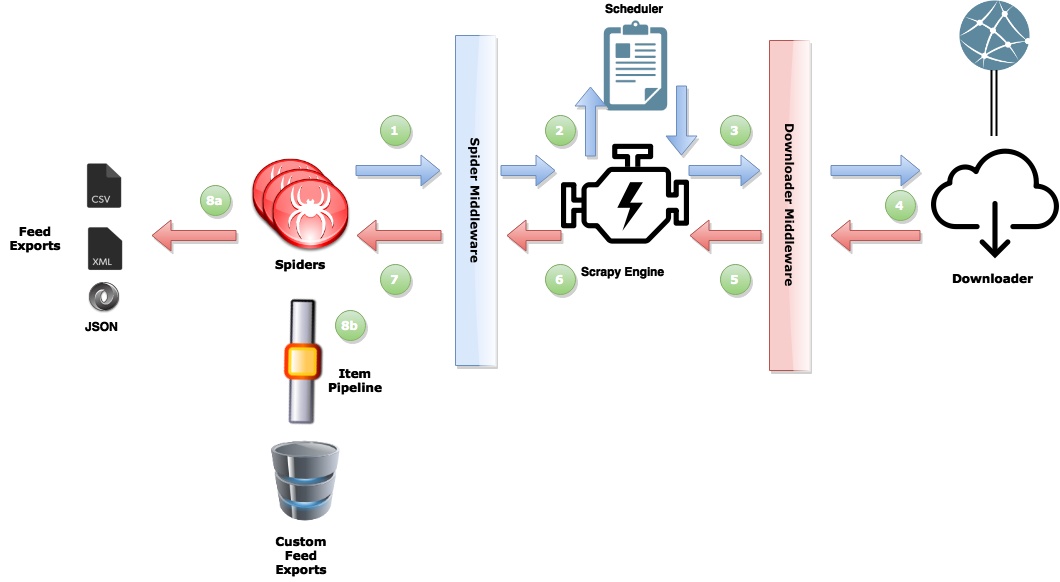
简介
在爬虫程序中,有时候我们想要获取整个网站的信息,所以我们写了一个整站爬虫的程序,但是有时候这样也不是很方便,因为采集时间比较长,而有时候我们又只想采集该网站下的某一个板块的内容。例如下面的网站中:
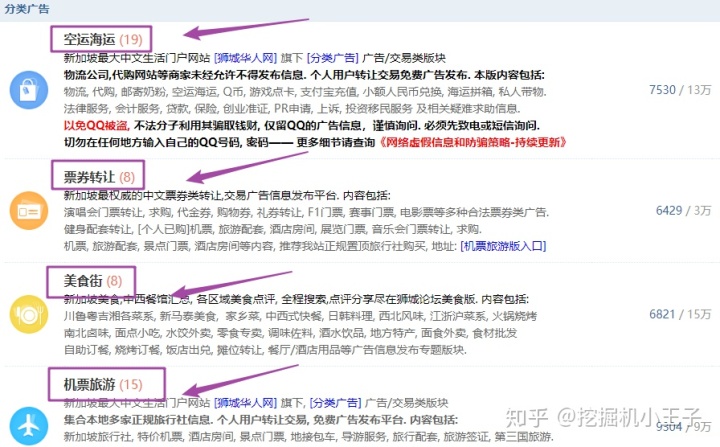
如果指定美食街等板块,就能自动采集该板块的内容会比较方便。Scrapy中是允许我们这样做的!!
通常我们执行Scrapy的时候是类似这样的:scrapy crawl spiderName
在加入参数后我们可以这样执行:
scrapy crawl spiderName -a parameter1=value1 -a parameter2=value2
我们可以增加分类或者其他参数来命令爬虫。爬虫文件中可以获取这些参数:
class MySpider(Spider):
name = 'myspider'
... 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1423
1423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









