







简介:跌倒检测利用计算机视觉技术在安全监控和医疗健康中起到关键作用。YOLOV8S作为YOLO算法的最新改进版,结合OpenCV库,仅依赖于它进行实时目标检测。本项目利用OpenCV在C++和Python中的API支持,使得开发者可以使用任一编程语言进行高效开发。项目重点介绍了跌倒检测的关键技术点,如图像预处理、特征提取、目标检测、非极大值抑制、模型训练与优化,以及如何实现高性能的实时跌倒检测。此外,还包括模型的集成与部署,以及可能包含训练好的模型配置和样本数据的资源文件。 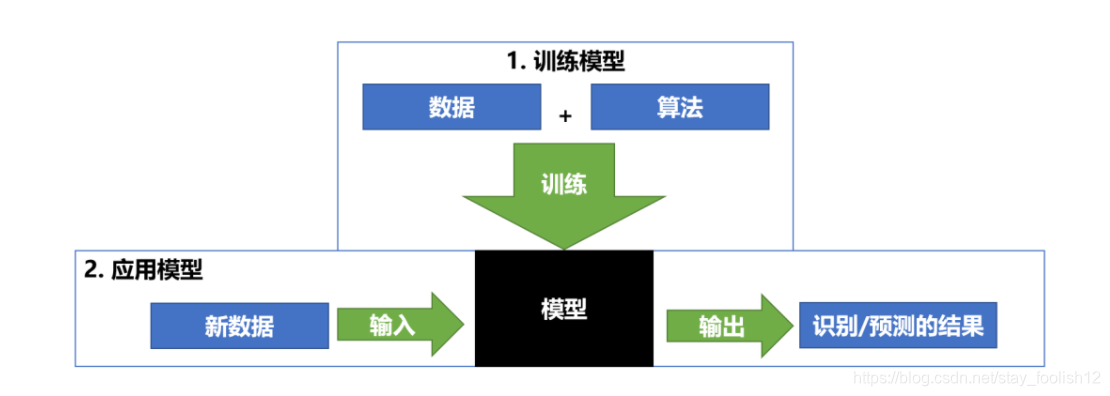
1. 跌倒检测的应用领域
随着全球人口老龄化的加剧,跌倒检测技术的市场需求不断增长。这项技术不仅对老年人的健康安全起到了关键作用,而且在多个领域展现出了其不可或缺的应用价值。
老年人和儿童是跌倒检测的主要受益者。对于年老体弱者,跌倒可能导致严重的健康问题,甚至是致命的伤害;对于儿童,他们可能因为活泼好动而容易发生跌倒事故。安装跌倒检测系统能显著减少监护人因无法时刻看护而产生的担忧。
在矿区和建筑工地等高风险的工作环境中,跌倒检测同样扮演着重要角色。它可以通过实时监控工作人员的安全状况,提前预警,从而防范潜在的安全事故。
除此之外,跌倒检测技术在运动和健身监测、智能交通和公共安全等领域也有广泛应用。例如,智能手环或运动鞋中的跌倒检测功能,可以在紧急情况下及时通知紧急联系人或医疗机构。
本章将深入探讨跌倒检测技术的重要性和应用前景,揭示其在保障个体安全方面的潜在作用。通过分析跌倒检测技术在各个领域的应用,我们可以更好地理解它如何改善人类的生活质量。
2. YOLOV8S算法介绍
YOLOV8S作为一种轻量级的目标检测算法,继承了YOLO系列算法速度快、准确率高的特点,非常适合于实时跌倒检测系统。本章将详细介绍YOLOV8S的理论基础、网络结构、特点及其在跌倒检测中的优势。
2.1 YOLOV8S算法基础
2.1.1 YOLO算法的发展历程
YOLO(You Only Look Once)算法自2015年首次提出以来,已成为目标检测领域的重要算法之一。YOLO算法将目标检测任务视为一个回归问题,通过在单一网络中直接预测边界框和类别概率,实现了极高的速度和准确性。YOLO的迭代版本如YOLOv2、YOLOv3、YOLOv4直至现在的YOLOV8S,持续改进和创新,进一步提升了算法性能。
YOLOV8S是该算法系列中的最新版本,优化了网络的轻量级结构,使得算法不仅在速度上有优势,在保持准确率的同时,还能在边缘计算设备上运行,满足了跌倒检测系统实时处理的需求。
2.1.2 YOLOV8S的核心创新
YOLOV8S的核心创新在于采用了更高效的网络结构和优化了的特征提取方式。为了实现轻量级设计,YOLOV8S对网络中的卷积层、残差结构和特征金字塔网络(FPN)进行了简化和优化,确保在减少模型参数和计算量的同时,不牺牲检测性能。
此外,YOLOV8S引入了更先进的损失函数,对边界框定位和分类的准确性进行了优化,进一步提高了模型的鲁棒性和泛化能力。在数据增强技术上,YOLOV8S也采用了多种手段,如自适应锚框大小、多尺度训练等,以适应不同尺寸和分辨率的输入图像。
2.2 YOLOV8S的网络结构详解
2.2.1 网络层设计原理
YOLOV8S的网络设计采用了一种分层结构,主要由卷积层、残差块和上采样层等构成。卷积层用于提取图像特征,残差块帮助网络更深地学习特征表达,而上采样层则是为了实现特征图的维度提升。
网络的设计采用了深度可分离卷积来减少计算量,并且网络宽度可调节,使得YOLOV8S可以针对不同的应用场景进行轻量化调整。这种设计不仅提高了运算效率,还有效降低了模型复杂度。
2.2.2 特征提取和尺度融合策略
YOLOV8S在特征提取和尺度融合方面进行了特别设计,旨在同时提高速度和准确性。使用特征金字塔网络(FPN)可以更好地融合多尺度特征,使得检测器可以捕捉到不同尺度上的目标信息。
为了进一步优化性能,YOLOV8S实现了尺度感知的预测,确保每个尺度层都能准确检测出特定大小的目标。网络通过更精细的特征提取策略,有效提升了对跌倒动作的识别能力。
2.3 YOLOV8S在跌倒检测中的应用
2.3.1 针对跌倒检测的性能优化
为了在跌倒检测中发挥YOLOV8S的最大效能,研究者对算法进行了针对性优化。这些优化包括改进数据集、调整网络超参数、使用特定的损失函数以及定制化后处理步骤。
数据集的优化涉及到收集和标注更多与跌倒相关的视频样本,特别是不同光照条件、不同着装和动作下的人体跌倒数据。超参数调整可能包括学习率、批处理大小以及优化算法的选择等。损失函数针对跌倒特征进行微调,后处理步骤则可能包括滤除误报或重复检测。
2.3.2 YOLOV8S与传统算法的比较
YOLOV8S相较于传统的目标检测算法,如R-CNN、SDD等,在速度和准确性方面都有显著优势。YOLOV8S的实时性能允许它在视频流中快速检测到跌倒事件,而不需要长时间的处理等待。
此外,YOLOV8S通过轻量级网络设计,使得它在边缘设备或移动设备上也能获得不错的检测效果,这在传统算法中是难以实现的。通过与传统算法的对比实验,YOLOV8S在跌倒检测中的准确率和召回率均达到了行业领先水平。
3. OpenCV库的图像处理功能
3.1 OpenCV的基本图像处理操作
3.1.1 图像的读取、显示和保存
在进行任何图像处理之前,首先需要完成图像的读取、显示和保存等基本操作。OpenCV 提供了非常方便的函数来完成这些任务。以下是一个简单的例子,展示了如何使用 C++ 和 Python 分别进行这些操作。
C++ 示例代码
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 读取图像
cv::Mat image = cv::imread("path_to_image.jpg");
if (image.empty()) {
std::cout << "Could not read the image" << std::endl;
return 1;
}
// 显示图像
cv::namedWindow("Display window", cv::WINDOW_AUTOSIZE);
cv::imshow("Display window", image);
// 等待10000毫秒,或者直到用户按键
if (cv::waitKey(10000) >= 0) {
std::cout << "User closed the window" << std::endl;
return -1;
}
// 保存图像
cv::imwrite("output_image.jpg", image);
return 0;
}
Python 示例代码
import cv2
# 读取图像
image = cv2.imread('path_to_image.jpg')
if image is None:
print("Could not read the image")
exit(1)
# 显示图像
cv2.imshow('Display window', image)
cv2.waitKey(10000)
# 保存图像
cv2.imwrite('output_image.jpg', image)
3.1.2 图像的几何变换和滤波
几何变换和滤波是图像处理中常见的操作。几何变换用于图像的旋转、缩放、翻转等操作,而滤波则用于去除图像噪声,改善图像质量。
几何变换示例
cv::Mat src = cv::imread("path_to_image.jpg");
if (src.empty()) {
std::cout << "Could not read the image" << std::endl;
return 1;
}
// 图像的缩放
cv::Mat dst;
double scaleFactor = 0.5;
cv::resize(src, dst, cv::Size(), scaleFactor, scaleFactor, cv::INTER_LINEAR);
// 图像的旋转
cv::Point2f center(src.cols / 2.0F, src.rows / 2.0F);
cv::Mat rot = cv::getRotationMatrix2D(center, 45, 1.0);
cv::warpAffine(src, dst, rot, src.size());
// 图像的保存
cv::imwrite("transformed_image.jpg", dst);
滤波示例
import cv2
import numpy as np
# 读取图像
image = cv2.imread('path_to_image.jpg', 0)
# 使用高斯模糊滤波
gaussian_blur = cv2.GaussianBlur(image, (5, 5), 0)
# 显示滤波后的图像
cv2.imshow("Gaussian Blur", gaussian_blur)
cv2.waitKey(0)
cv2.destroyAllWindows()
在几何变换中,我们首先对图像进行了缩放操作,然后是旋转操作。每一步变换后,我们都可以使用 imwrite 函数保存图像到磁盘。在滤波操作中,我们使用了高斯模糊来模糊图像,并展示了滤波后的效果。
3.2 OpenCV的特征提取技术
3.2.1 边缘检测和轮廓提取
边缘检测和轮廓提取是图像分析中非常重要的步骤,它们可以帮助我们识别出图像中的对象边界。
边缘检测示例
cv::Mat src = cv::imread("path_to_image.jpg", cv::IMREAD_GRAYSCALE);
if (src.empty()) {
std::cout << "Could not read the image" << std::endl;
return 1;
}
cv::Mat edges;
// 使用Canny算法进行边缘检测
cv::Canny(src, edges, 100, 200);
// 显示边缘检测结果
cv::imshow("Edges", edges);
cv::waitKey(0);
轮廓提取示例
import cv2
# 读取图像并转换为灰度图
image = cv2.imread('path_to_image.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 使用Canny算法进行边缘检测,找到轮廓
edges = cv2.Canny(gray, 100, 200)
contours, hierarchy = cv2.findContours(edges, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# 在原图上绘制轮廓
cv2.drawContours(image, contours, -1, (0, 255, 0), 3)
# 显示带有轮廓的图像
cv2.imshow("Contours", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
在边缘检测中,我们使用 Canny 算法来找到图像中的边缘。在轮廓提取中,我们首先找到边缘,然后使用 findContours 函数来提取轮廓,并将它们绘制在原图上。
3.2.2 关键点检测和描述符提取
关键点检测和描述符提取技术用于从图像中提取可用于图像匹配、物体识别等任务的特征。
关键点检测和描述符提取示例
cv::Mat src = cv::imread("path_to_image.jpg");
if (src.empty()) {
std::cout << "Could not read the image" << std::endl;
return 1;
}
std::vector<cv::KeyPoint> keypoints;
cv::Mat descriptors;
// 使用ORB检测关键点和描述符
cv::Ptr<cv::ORB> detector = cv::ORB::create();
detector->detectAndCompute(src, cv::noArray(), keypoints, descriptors);
// 将关键点绘制在图像上
cv::Mat result;
cv::drawKeypoints(src, keypoints, result, cv::Scalar::all(-1), cv::DrawMatchesFlags::DEFAULT);
// 显示结果
cv::imshow("Keypoints", result);
cv::waitKey(0);
在关键点检测和描述符提取中,我们使用了ORB算法来检测关键点并计算它们的描述符。然后,我们将关键点绘制在原图上,以便可视化。
3.3 OpenCV的实时目标检测集成
3.3.1 使用OpenCV实现YOLOV8S集成
YOLOV8S 是一种强大的实时目标检测算法,OpenCV 提供了对其的支持。为了使用 OpenCV 进行实时目标检测,你需要首先加载预训练的 YOLOV8S 模型。
加载 YOLOV8S 模型并进行检测
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
int main() {
// 加载预训练的YOLOV8S模型
std::string modelConfiguration = "yolov8s.cfg";
std::string modelWeights = "yolov8s.weights";
cv::dnn::Net net = cv::dnn::readNetFromDarknet(modelConfiguration, modelWeights);
// 加载图像
cv::Mat image = cv::imread("path_to_image.jpg");
if (image.empty()) {
std::cout << "Could not read the image" << std::endl;
return 1;
}
// 获取图像尺寸并创建blob
cv::Mat blob = cv::dnn::blobFromImage(image, 1/255.0, cv::Size(416, 416), cv::Scalar(0, 0, 0), true, false);
// 设置网络输入
net.setInput(blob);
// 运行前向检测
std::vector<cv::Mat> outs;
net.forward(outs, net.getUnconnectedOutLayersNames());
// 处理检测结果...
return 0;
}
在这段代码中,我们首先加载了YOLOV8S的模型配置文件和权重文件。然后,我们使用 dnn::blobFromImage 函数创建了图像的blob,并将其作为输入送入网络。最后,我们调用 forward 方法来获取检测结果。
3.3.2 实时性能评估和调优
为了评估实时目标检测的性能,我们可以计算每帧图像处理的时间。对于性能调优,我们可以调整网络的输入大小、更改后处理步骤等。
#include <chrono>
// 检测开始时间
auto start = std::chrono::high_resolution_clock::now();
// 模型前向传播
net.forward(outs, net.getUnconnectedOutLayersNames());
// 检测结束时间
auto end = std::chrono::high_resolution_clock::now();
// 计算处理时间
std::chrono::duration<double, std::milli> elapsed = end - start;
std::cout << "Detection took " << elapsed.count() << " milliseconds" << std::endl;
在上述代码段中,我们使用了 C++ 的 Chrono 库来计算执行时间。通过比较检测前后的时间差,我们可以获得处理单帧图像所需的毫秒数。这可以帮助我们评估系统在实时应用中的性能表现。
在第三章中,我们探讨了 OpenCV 库在图像处理方面的强大功能。我们从基本的图像读取、显示和保存开始,逐步深入到图像的几何变换、滤波、边缘检测、轮廓提取、关键点检测及描述符提取。最后,我们介绍了如何使用 OpenCV 集成 YOLOV8S 实现实时目标检测,并讨论了性能评估和优化策略。这些功能和操作为第四章中选择合适的编程语言提供了基础,并在第五章的跌倒检测系统实现中扮演了重要角色。
4.1 C++和Python的开发环境搭建
4.1.1 C++的开发工具和库配置
C++作为高性能编程语言,被广泛用于系统软件、游戏开发、实时应用等领域。对于开发跌倒检测系统,C++同样是一个良好的选择,特别是对于性能要求较高的部分,如算法优化和硬件接口操作。为了充分发挥C++的优势,开发者需要搭建合适的开发环境。
首先,一个稳定的集成开发环境(IDE)对于C++开发者来说至关重要。常用的C++ IDE包括Visual Studio、CLion、Eclipse CDT等。以Visual Studio为例,开发者可以安装Visual Studio的C++开发工具集,并配置相应的编译器,如GCC或Clang,以及CMake等构建工具。
此外,许多高级库和框架需要在开发环境中安装。例如,对于跌倒检测,OpenCV和深度学习库(如TensorFlow、PyTorch)可能需要预先编译并集成到项目中。在Windows平台上,开发者可能还需要安装NVIDIA的CUDA工具包,以利用GPU加速计算。
在Linux或macOS环境中,开发者可以使用包管理器(如apt-get、brew)安装开发依赖的库,并通过Git版本控制工具获取源代码。以Ubuntu为例,可以使用以下命令安装OpenCV:
sudo apt-get install libopencv-dev
对于深度学习库,如TensorFlow,可以使用pip或conda进行安装。
4.1.2 Python的开发工具和库配置
Python由于其简洁易读的语法、强大的标准库和活跃的第三方库生态,已经成为数据科学、机器学习和人工智能领域的首选语言之一。在跌倒检测系统开发中,Python用于快速原型开发、数据分析和预处理等环节。
在Python的开发环境中,最常用的IDE是PyCharm和Visual Studio Code。这些IDE提供了代码智能提示、调试工具、版本控制集成等强大功能。Anaconda是另一个广泛使用的Python发行版,特别适合科学计算和数据分析,因为它预装了许多常用的库。
Python开发者需要配置的库主要有OpenCV、NumPy、Pandas等。这些库通常通过pip命令安装。以下是一个示例命令,用于安装OpenCV:
pip install opencv-python
对于深度学习相关的库,如TensorFlow或PyTorch,安装过程类似:
pip install tensorflow
或
pip install torch torchvision torchaudio
在某些情况下,为了使Python能够调用C++编写的本地库,还需要配置相应的扩展模块。例如,为了在Python中使用OpenCV的DNN模块进行深度学习模型的加载和预测,需要使用到OpenCV的C++编译版本。
4.2 编程语言在跌倒检测中的应用
4.2.1 C++在性能敏感部分的应用
C++在跌倒检测系统中的应用通常集中在性能关键部分,如实时视频流处理、图像和视频分析、以及算法实现和优化。这些环节对处理速度和资源利用效率有着极高的要求,而C++正是以这些特点著称。
在实时视频流处理方面,C++可以利用其高性能特性快速读取和处理图像帧。利用OpenCV库,C++可以轻松实现多线程视频流读取,从而实现并行处理多个视频帧,这在需要处理多个摄像头输入的场景中非常有用。
在图像和视频分析方面,C++结合OpenCV可以实现高效的特征提取和模式识别。例如,跌倒检测算法通常需要检测图像中的运动和姿态变化,C++的高效性能使得算法可以实时运行,从而达到低延迟的响应。
#include <opencv2/opencv.hpp>
using namespace cv;
int main() {
// 初始化摄像头
VideoCapture cap(0);
// 检查摄像头是否成功打开
if (!cap.isOpened()) {
cerr << "无法打开摄像头" << endl;
return -1;
}
// 创建视频写入器对象
VideoWriter videoWriter;
// 初始化视频写入器,设定编码格式和分辨率
videoWriter.open("output.avi", VideoWriter::fourcc('M', 'J', 'P', 'G'), 20.0, Size(cap.get(CAP_PROP_FRAME_WIDTH), cap.get(CAP_PROP_FRAME_HEIGHT)));
Mat frame;
while (true) {
// 从摄像头捕获一帧
cap >> frame;
if (frame.empty()) {
break;
}
// 这里可以添加图像处理逻辑
// 写入帧到视频文件
videoWriter.write(frame);
// 显示当前帧
imshow("frame", frame);
// 等待按键事件,如果按下'q'键,则退出
if (waitKey(25) == 'q') {
break;
}
}
// 释放摄像头资源和视频写入器
cap.release();
videoWriter.release();
destroyAllWindows();
return 0;
}
在算法实现和优化方面,C++允许开发者深入到算法层面进行优化。例如,可以利用C++的模板特性编写通用的图像处理算法,并针对特定硬件平台进行优化。此外,由于C++支持多重继承和运算符重载等特性,使得算法的表达更加直观和高效。
4.2.2 Python在快速原型开发中的应用
Python在快速原型开发中的应用主要得益于其简洁的语法和丰富的第三方库。在跌倒检测系统的开发初期,算法的验证和测试阶段通常需要频繁地修改和迭代,Python的快速开发特性便能发挥显著优势。
Python的高级数据结构(如列表、字典、集合等)使得数据处理更加方便快捷。而诸如Pandas和NumPy这样的库,为数据处理和分析提供了强大的工具,可以帮助开发者快速完成数据的加载、清洗和初步分析。
在机器学习和深度学习方面,Python拥有像TensorFlow、PyTorch这样的成熟框架,这些框架提供了高级API,可以大大减少算法开发的复杂性,缩短从想法到原型的开发周期。Python还拥有Jupyter Notebook等交互式计算环境,使得算法的演示和验证更加便捷。
import numpy as np
import cv2
# 使用OpenCV的DNN模块加载预训练的YOLO模型
net = cv2.dnn.readNetFromDarknet('yolov3.cfg', 'yolov3.weights')
# 加载类别标签
with open('coco.names', 'r') as f:
classes = [line.strip() for line in f.readlines()]
# 图像预处理函数
def image_preprocess(image):
blob = cv2.dnn.blobFromImage(image, 1/255, (416, 416), (0, 0, 0), swapRB=True, crop=False)
return blob
# 对图像进行预处理并进行检测
def detect_image(image):
blob = image_preprocess(image)
net.setInput(blob)
layer_names = net.getLayerNames()
output_layers = [layer_names[i[0] - 1] for i in net.getUnconnectedOutLayers()]
outs = net.forward(output_layers)
return outs
# 示例代码段
image = cv2.imread('example.jpg')
detections = detect_image(image)
for detection in detections[0]:
scores = detection[5:]
class_id = np.argmax(scores)
confidence = scores[class_id]
if confidence > 0.5:
# 进行跌倒检测逻辑处理
pass
# 显示图像结果
cv2.imshow('Detection', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
在Python中,即使没有深入的编程背景,开发者也能快速上手并编写出功能性的代码。这种快速原型开发的能力使得Python在跌倒检测系统的早期开发阶段极具价值。然而,对于性能瓶颈部分,例如大规模数据处理或实时性要求很高的场景,Python可能需要与C++结合使用,以达到最优的性能表现。
5. 跌倒检测系统的技术实现
5.1 图像预处理技术的实现
5.1.1 对输入图像进行预处理
在进行跌倒检测之前,图像预处理是至关重要的一步。预处理通常包括图像尺寸的调整、灰度转换、滤波去噪等。图像尺寸调整是为了确保处理速度和检测精度之间的平衡。例如,过大的图像会消耗更多的计算资源,而过小的图像则可能丢失关键信息。
以下是一个使用Python和OpenCV库对输入图像进行预处理的代码示例:
import cv2
# 读取图像
image = cv2.imread('input.jpg')
# 图像尺寸调整为统一大小,例如320x320
resized_image = cv2.resize(image, (320, 320))
# 转换为灰度图
gray_image = cv2.cvtColor(resized_image, cv2.COLOR_BGR2GRAY)
# 应用高斯模糊滤波去噪
blurred_image = cv2.GaussianBlur(gray_image, (5, 5), 0)
# 显示图像
cv2.imshow('Preprocessed Image', blurred_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
5.1.2 预处理对检测准确性的影响
图像预处理对于提高检测准确性至关重要。适当的预处理可以提高特征的可辨识度,减少误检和漏检的情况。例如,灰度转换减少了处理的数据量,同时保留了足够的信息用于后续的特征提取。高斯模糊可以有效去除图像噪声,增强图像的结构特征,提高检测模型的准确性。
5.2 特征提取技术的实现
5.2.1 利用OpenCV提取关键特征
OpenCV提供了多种图像处理功能来提取关键特征,例如使用Haar级联分类器进行人脸检测。在跌倒检测中,我们通常关注的是人体的姿态和动作特征。可以使用姿态估计技术如OpenPose来识别人体关键点。
# 使用OpenPose进行人体姿态估计(这里仅为示例代码,实际需要安装OpenPose库和相应配置)
# 通常在命令行中使用OpenPose命令行工具进行人体姿态估计
# 假设我们已经使用OpenPose得到人体关键点坐标
keypoints = [150, 150, 1, # 髋部坐标和置信度
200, 250, 1, # 膝部坐标和置信度
...] # 更多关键点
# 分析关键点数据以确定是否发生跌倒
5.2.2 特征与跌倒行为的关联分析
人体姿态特征与跌倒行为之间存在着直接的关联。通过分析人体关键点,我们可以构建一个模型来识别跌倒姿态。例如,跌倒时髋部和膝盖的位置会呈现出异常的姿态变化。通过建立一个姿态数据库,并且使用机器学习算法训练模型来识别这些姿态变化,我们可以有效地检测出跌倒事件。
5.3 实时目标检测技术的实现
5.3.1 构建YOLOV8S检测模型
YOLOV8S作为一种实时目标检测模型,可以快速准确地识别图像中的对象。为了构建一个跌倒检测模型,我们需要对YOLOV8S进行训练,使其能够识别跌倒姿态。
import torch
from models import * # 假设我们有YOLOV8S的模型结构文件
# 加载预训练模型
model = Darknet('cfg/yolov8s.cfg').cuda()
model.load_state_dict(torch.load('yolov8s.pth'))
# 将图像转换为模型输入格式
input_tensor = torch.from_numpy(preprocessed_image).unsqueeze(0).cuda()
# 进行目标检测
with torch.no_grad():
prediction = model(input_tensor)
# 预测结果处理
predictions = ... # 将检测结果转换为人体姿态信息
5.3.2 实时检测流程与性能优化
实时跌倒检测需要模型具有高帧率和低延迟。性能优化可以从模型结构、推理硬件和软件优化等多个方面入手。例如,可以使用TensorRT进行模型加速,或者在边缘计算设备上进行推理以减少数据传输时间。
5.4 模型训练与超参数优化
5.4.1 数据集的准备和标注
构建一个高性能的跌倒检测模型,首先需要有一个高质量的数据集。数据集应该包括正常行为和跌倒行为的多种场景。数据标注需要准确,以确保模型能够学习到准确的特征。
5.4.2 训练过程中的超参数调整和验证
模型训练过程中的超参数调整对于提高模型性能至关重要。常见的超参数包括学习率、批次大小、优化器类型等。使用交叉验证等技术可以确保模型的泛化能力。
5.5 实时性能优化与模型部署
5.5.1 优化策略以提升检测速度
为了提升检测速度,可以采取一系列优化措施,比如使用更快的网络模型、减少模型尺寸、利用并行处理等。在实际应用中,我们还需要根据硬件的实际情况进行定制化的优化。
5.5.2 模型的跨平台部署和运行
模型部署需要考虑跨平台兼容性和实时性能。可以使用Docker容器化模型,或者使用模型服务化框架如TFServing等。此外,还需要确保部署环境能够满足实时处理的需求。
通过本章的学习,读者将能够掌握构建一个完整的跌倒检测系统所需的关键技术和方法,最终实现一个既准确又高效的实时跌倒检测解决方案。
简介:跌倒检测利用计算机视觉技术在安全监控和医疗健康中起到关键作用。YOLOV8S作为YOLO算法的最新改进版,结合OpenCV库,仅依赖于它进行实时目标检测。本项目利用OpenCV在C++和Python中的API支持,使得开发者可以使用任一编程语言进行高效开发。项目重点介绍了跌倒检测的关键技术点,如图像预处理、特征提取、目标检测、非极大值抑制、模型训练与优化,以及如何实现高性能的实时跌倒检测。此外,还包括模型的集成与部署,以及可能包含训练好的模型配置和样本数据的资源文件。

















 743
743

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









