






VLookup无疑是Excel中进行数据匹配查询用得最广泛的函数,但是,随着企业数据量的不断增加,分析需求越来越复杂,越来越多的朋友明显感觉到VLookup函数在进行批量性的数据匹配过程中出现的卡顿问题也越来越严重。
那么,在数据量较大,需要批量进行数据匹配查找的情况下,是否有办法进行适当的改善,以提高数据的匹配查找效率呢?
以下用一个例子,分别对比了四种常用的数据匹配查找的方法,并在借鉴PowerQuery的合并查询思路的基础上,提出一个简单的公式改进思路,供大家参考。
一、测试数据
本次测试以微软罗斯文贸易数据库的订单表和订单明细表进行扩展,涉及数据概况及要求如下:
订单表21581行(含标题)
订单明细表17257行(含标题)
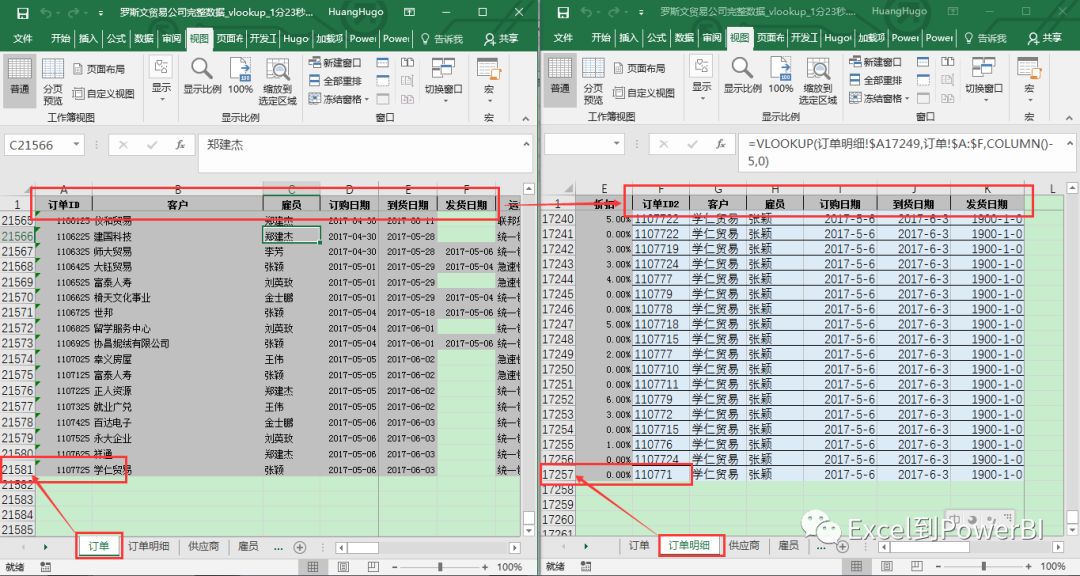
要求将订单表中的“订单ID”、“客户”、“雇员”、“订购日期”、“到货日期”、“发货日期”等6列数据匹配到订单明细表中。
如下图所示:
二、测试设备配置
本次测试使用个人笔记本电脑进行,系统、软件及配置情况如下:
笔记本型号:Thinkpad X250
核心配置:CPU i5-5200U @2.20GHz(4核)+ 内存 8GB + 固态硬盘
系统:Windows 7(64位)
Excel版本:2016(64位)
三、 测试方法
为尽可能减少相关程序及不同工作簿之间可能造成的干扰,分别对四种方法建立单独的工作簿,每次仅打开一个工作簿进行独立操作,如下图所示:
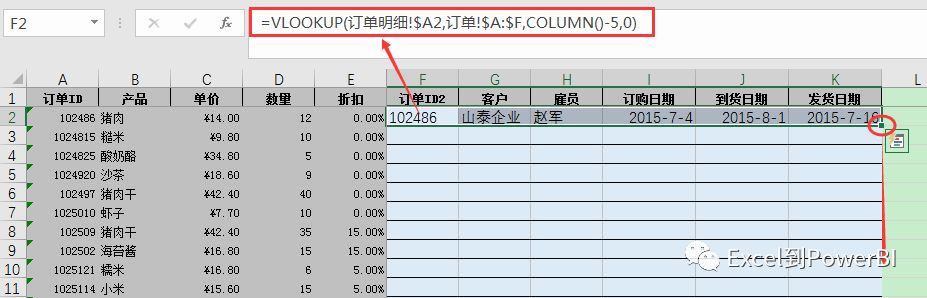
公式法统一在第一行写上公式,然后统一向下扩展填充至所有行,从开始填充起计算至填充完成的时间,如下图所示:
四、4种数据匹配查找方法
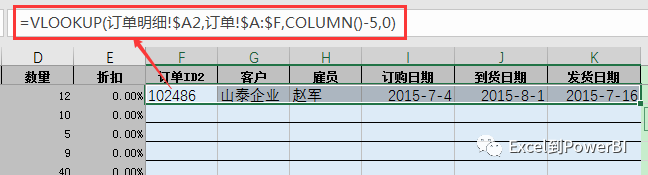
1、VLookup函数,按常用全列匹配公式写法如下图所示:
2、Index+Match函数,按常用全列匹配公式写法如下图所示:
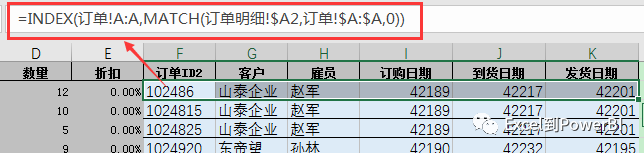
3、Lookup函数,按常用全列匹配公式写法如下图所示:
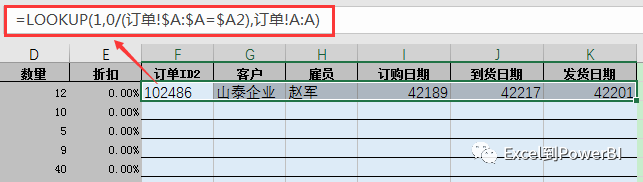
4、Power Query合并查询,按常规表间合并操作如下图所示:

五、4种方法数据匹配查找方法用时对比
经过分别对以上4中方法单独执行多列同时填充(Power Query数据合并法单独执行数据刷新)并计算时间,结果如下表所示:

从运行用时来看:
VLookup函数和Index+Match函数的效率基本一样;
Lookup函数在大批量数据的查找中效率最低,甚至不能忍受;
Power Query的效率非常高。
六、 对公式法的改进
考虑到仍有大量的朋友没有使用PowerQuery,我在想:
是否有可能对公式进行一定程度的改进,以实现效率上的提升?
PowerQuery的合并查询效率为什么会这么高?
PowerQuery进行合并查询的思想是否可能借鉴用于公式查询?
在思考这些问题的时候,我突然想到,Power Query进行合并查询的步骤,其实是分两步的:
第一步:先进行数据的匹配
第二步:按需要进行数据的展开
也就是说,只需要匹配查找一次,其它需要展开的数据都跟着这一次的匹配而直接得到,而我们在前面用VLookup、Index+Match写公式的思路则是对每一个需要取的值,都是一次单独的匹配和单独的取值。也就是说,每次为了查找到一个数据,都需要从订单表的2万多条数据里搜索一遍,这种效率自然会很低。
那么,如果我们在公式中也可以做到只匹配一次,后面所需要取的数据都跟着这次匹配的结果而直接得到,那么,效率是否会大有改善呢?
再回头看Index+Match结合的公式,其中,Match函数用于确定所需要查找内容的位置,而Index用于提取该位置相应的值!那么,如果我们只用Match一次把位置先找出来,后面所有的列都直接用这个位置去提取相应的值,会怎样?
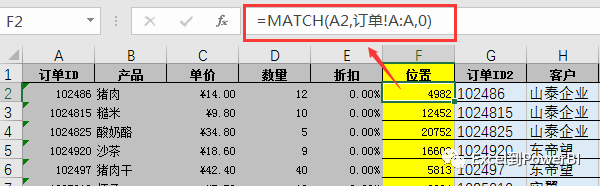
于是,我首先用Match函数构建一个辅助列,用于获取匹配位置,如下图所示:
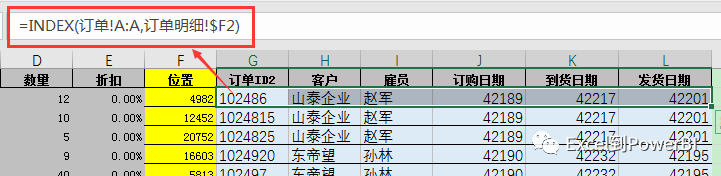
然后,通过Index函数,直接根据辅助列的位置从订单表里读取相应的数据,如下图所示:
分不同情况执行如下:
单独填充位置列(Match公式列),用时约15秒;
同时根据已匹配的位置列填充G:L列(Index公式全部列),用时约1秒(双击填充柄直接出现进度条,不出现“正在计算,##%”过程);
位置列和其他数据列同时填充,用时约17秒,约为直接使用VLookup函数或Index+Match函数组合公式(约85秒)的五分之一!
七、结论
在批量性匹配查找多列数据的情况下,通过对Index和Match函数的分解使用,先单独获取所需要匹配数据的位置信息,然后再根据位置信息提取所需多列的数据,效率明显提升,所需匹配提取的列数越多,效率提升越明显。
当然,使用公式的方法,即使在一定程度上进行改进,和Power Query相比仍然有很大的差距。因此,在数据量较大,数据处理较为复杂的情况下,建议使用Power Query来进行。
Power新书榜第1 | 最适合入门打基础
当当/京东100减50 | 购书领60元视频券
- 最通俗易懂Power系列视频 -
【★★★★★好评】
【5万+播放人次】

点“阅读原文”看视频


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









