






 本文详细探讨了MySQL索引的工作原理,尤其是为何选择B+Tree作为主要数据结构。通过对磁盘I/O和数据存储的理解,解释了B+Tree如何减少I/O操作,提高查询效率。同时,介绍了MyISAM和InnoDB存储引擎的索引实现差异,强调了主键和非主键索引的设计考虑。最后,提到了联合索引和最左前缀原则,为数据库性能优化提供了关键洞察。
本文详细探讨了MySQL索引的工作原理,尤其是为何选择B+Tree作为主要数据结构。通过对磁盘I/O和数据存储的理解,解释了B+Tree如何减少I/O操作,提高查询效率。同时,介绍了MyISAM和InnoDB存储引擎的索引实现差异,强调了主键和非主键索引的设计考虑。最后,提到了联合索引和最左前缀原则,为数据库性能优化提供了关键洞察。
深入理解Mysql索引底层数据结构与算法
----->之前很多人还问我一些关于mysql索引的底层和使用,我就特意写一篇文章跟大家一起分享一下我对mysql索引的理解,大家有更深入的理解可以下面留言。
1.索引的定义
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构
大家使用索引有没有想过这个问题?为什么索引能够帮助mysql高效获取数据?我一一给大家道来!在给大家讲之前,先更大家分享一些计算机基础知识,有助于理解
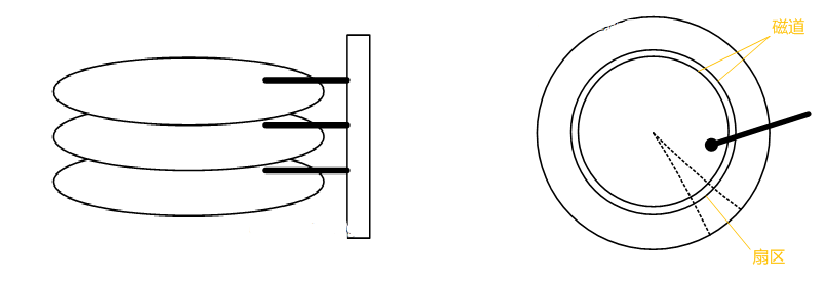
我们都知道mysql数据是已文件的形式存储在磁盘上的。
那磁盘是有一圈一圈的磁道组成的
磁头移动到不同磁道,磁盘旋转,这样就可以读取到数据
磁盘存取原理1.寻道时间(速度慢,费时)2.旋转时间(速度较快)
cpu读取数据都是从内存去读,内存去磁盘读取数据,内存读取磁盘数据大小都是已页的大小单位,一页=10kb
总结:
通过上面的一些知识,我们知道当磁头移动到另一个磁道读取诗句就是我们常说的一次I/O操作,但是我们知道mysql数据是分布到不同的磁道上的,每次读取数据都要把所有磁道读取一遍,那我们进行I/O次数就很多了,查询效率就很低
那索引就是把索引字段数据的地址保存起来,来帮助mysql直接定位到哪个磁道的哪个扇区,这样就减少I/O操作了,自然查询效率就提高了
2.数据结构那么多,mysql索引为什么要用B+Tree数据结构,而不是其他呢?肯定其他的数据不满足我们的要求
常见的数据结构
1.二叉树
2.红黑树
3.Hash
4.B Tree
5.B+Tree
a.二叉树
二叉树是n(n>=0)个结点的有限集合,该集合或者为空集(称为空二叉树),或者由一个根结点和两棵互不相交的、分别称为根结点的左子树和右子树组成。
不使用原因:会出现极端情况,一个节点只有一度,就是只有一个子节点,那读取树的一层就是一次I/O,那性能也不好
b.红黑树
红黑树即为平衡二叉树的一种
不使用原因:极端情况下,一个节点有2个子节点,那就出现一层只有2个节点的情况,这种性能也不好
c.Hash
不使用原因:Hash是把索引数据进行Hash算法对应一个地址,我们会发现这个好像性能很好啊,直接找到,但是我们想想,它能满足我们日常开发大部分情况吗?比如通过大于或者小于去筛选数据,所以说也不合适,当然mysql还是提供了Hash索引,毕竟有些场合还是用起来也不错
d.B Tree
1.度(Degree)-节点的数据存储个数2.叶节点具有相同的深度3.叶节点的指针为空4.节点中的数据key从左到右递增排列
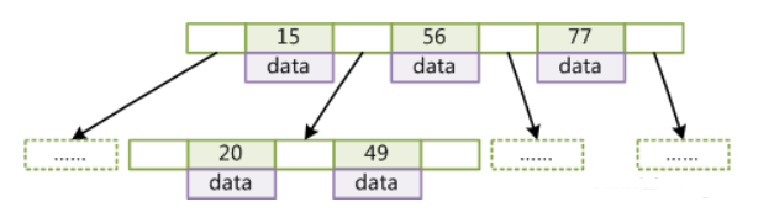
不使用原因:虽然解决了每一层的节点数的极端情况下,但是我们会发现每个节点存储了索引和数据,那一层能存储的数据太多也不好,毕竟内存能读取的数据大小就是10kb
e.B+Tree
1.B+Tree(B-Tree变种)2.非叶子节点不存储data,只存储key,可以增大度3.叶子节点不存储指针4.顺序访问指针,提高区间访问的性能
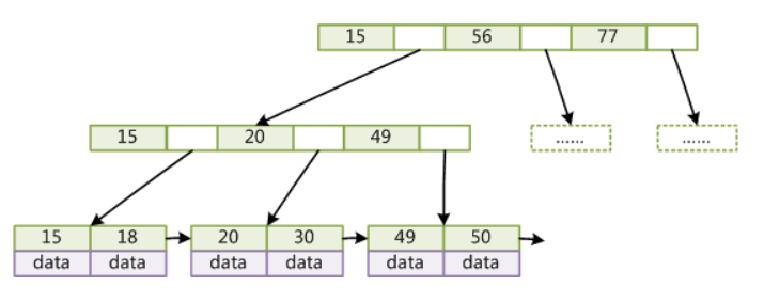
使用原因:设计有几个方面1.非叶子节点不存储data,只存储key,可以增大度2.叶子节点不存储指针3.顺序访问指针,提高区间访问的性能
3.B+Tree索引的性能分析
一般使用磁盘I/O次数评价索引结构的优劣
预读:磁盘一般会顺序向后读取一定长度的数据(页的整数倍)放入内存
局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用
B+Tree节点的大小设为等于一个页,每次新建节点直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,就实现了一个节点的载入只需一次I/O
B+Tree的度d一般会超过100,因此h非常小(一般为3到5之间)
4.不同的存储引擎有不同的索引实现
1.MyISAM索引实现(非聚集)2.InnoDB索引实现(聚集)
a.MyISAM索引实现(非聚集)
--->MyISAM索引文件和数据文件是分离的
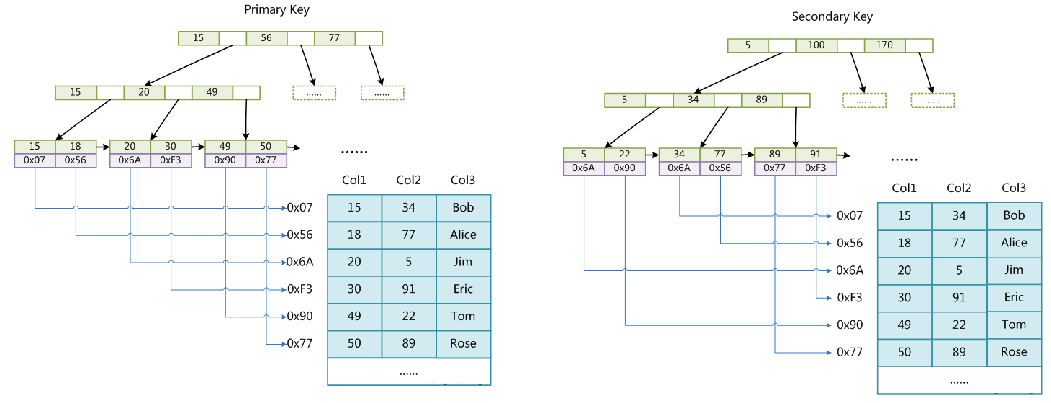
b.InnoDB索引实现(聚集)
1.数据文件本身就是索引文件2.表数据文件本身就是按B+Tree组织的一个索引结构文件3.聚集索引-叶节点包含了完整的数据记录4.为什么InnoDB表必须有主键,并且推荐使用整型的自增主键?5.为什么非主键索引结构叶子节点存储的是主键值?(一致性和节省存储空间)
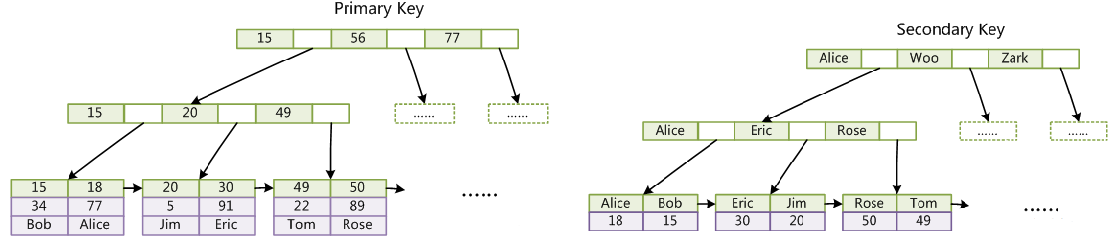
5.联合索引结构
---->联合索引的底层存储结构长什么样?
6.索引最左前缀原理

















 2648
2648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









