






 本文介绍了一种Few-Shot目标检测方法,通过Attention机制和对比训练策略,模型能在少量样本下精准检测新类别目标,无需fine-tune。
本文介绍了一种Few-Shot目标检测方法,通过Attention机制和对比训练策略,模型能在少量样本下精准检测新类别目标,无需fine-tune。


作者 | VincentLee
来源 | 晓飞的算法工程笔记
不同于正常的目标检测任务,few-show目标检测任务需要通过几张新目标类别的图片在测试集中找出所有对应的前景。为了处理好这个任务,论文主要有两个贡献:
- 提出一个通用的few-show目标检测算法,通过精心设计的对比训练策略以及RPN和检测器中加入的attention模块,该网络能够榨干目标间的匹配关系,不需要fine-tune就可以进行靠谱的新目标检测。实验表明,early stage的attention模块能够显著提升proposal的质量,而后面的多关系检测(multi-relation detector)模块则能有效抑制和过滤错误的背景
- 提供了一个1000类的少样本训练集FSOD,论文提出的模型的性能提升有一定程度得益于此训练集,是一个前所未有的训练集


FSOD: A Highly-Diverse Few-Shot Object Detection Dataset
尽管目前目标检测的训练集已经非常庞大,但是对于少样本目标检测算法的使用而言,这些训练集的类别都太少了。因此,论文构造了一个少样本目标检测专用的训练集
Dataset Construction

Dataset Analysis
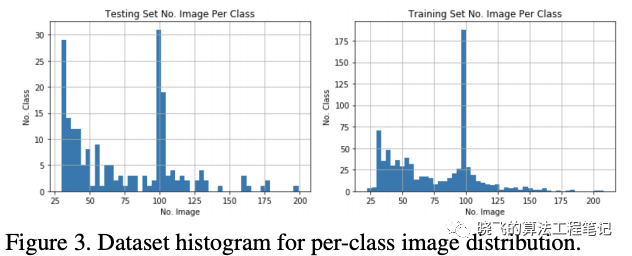
 新训练集的数据情况如图3和表1,主要有两个特性:
新训练集的数据情况如图3和表1,主要有两个特性:- High diversity in categories,类别覆盖的领域很多,包括动物、衣服、武器等,且训练集和测试集的类别来自不同的领域
- Challenging setting,数据集在box大小和宽高比上有很多种,26.5%的图片包含至少3个目标,且有大量非目标类别的物体,干扰性很大

方法论
Problem Definition
给予包含目标特写的辅助图片(support image)以及可能包含类目标的查询图片,任务是找出查询图片中所有辅助图片对应的类别目标,并且标记其准确的位置。如果辅助集包含个类别,每个类提供张图片,则称为K-way N-shot检测。Deep Attentioned Few-Shot Detection
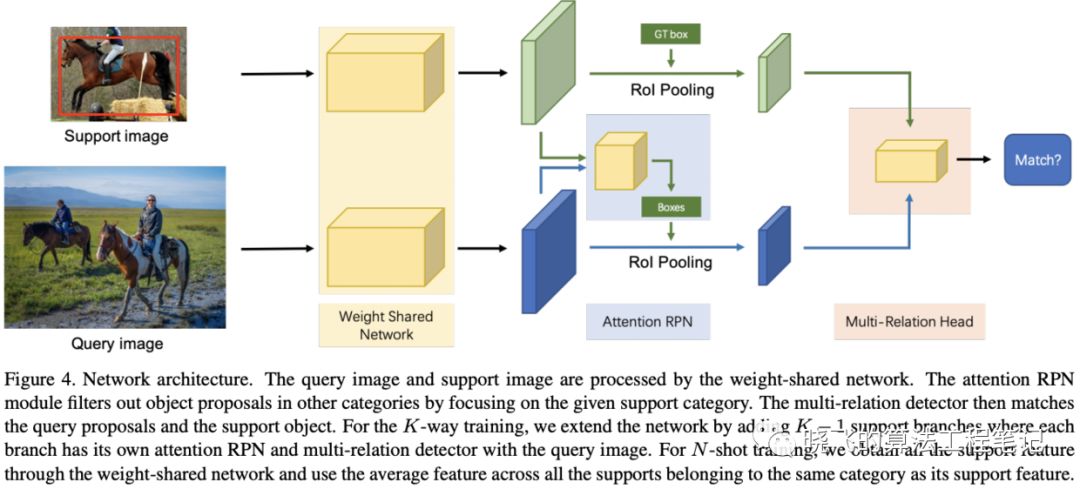 论文提出新attention网络,该网络能够在RPN模块和多关系检测模块中学习辅助集与查询集间的通用的匹配关系。网络为包含多分支的权重共享框架,一个分支用于查询集,其它则用于辅助集(为了方便,图4只画了一个分支),对于同类别的辅助分支,使用平均特征图作为辅助特征图。查询分支的权重共享主干为Faster R-CNN(包括RPN),使用这个分支来训练辅助集和查询集的匹配关系,能够学习到同类别的通用知识。
论文提出新attention网络,该网络能够在RPN模块和多关系检测模块中学习辅助集与查询集间的通用的匹配关系。网络为包含多分支的权重共享框架,一个分支用于查询集,其它则用于辅助集(为了方便,图4只画了一个分支),对于同类别的辅助分支,使用平均特征图作为辅助特征图。查询分支的权重共享主干为Faster R-CNN(包括RPN),使用这个分支来训练辅助集和查询集的匹配关系,能够学习到同类别的通用知识。Attention-Based Region Proposal Network
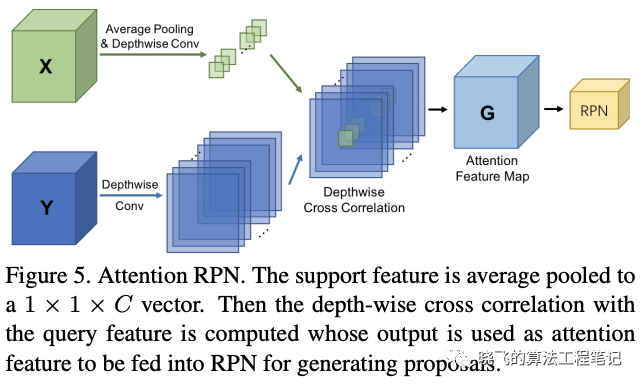 在少样本目标检测中,RPN能够产生潜在的相关box用于接下来的检测任务,不仅要分辨前景和背景,还要过滤不属于辅助集的前景。如果没有足够的辅助集信息,RPN将会产生大量不相关的proposal。为了解决这个问题,提出了attention RPN,能够使用辅助图片的信息来过滤背景以及不相关的前景,产生更少但更准的候选目标.
在少样本目标检测中,RPN能够产生潜在的相关box用于接下来的检测任务,不仅要分辨前景和背景,还要过滤不属于辅助集的前景。如果没有足够的辅助集信息,RPN将会产生大量不相关的proposal。为了解决这个问题,提出了attention RPN,能够使用辅助图片的信息来过滤背景以及不相关的前景,产生更少但更准的候选目标.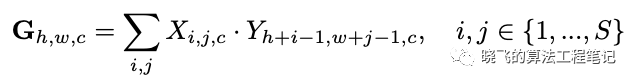 Attention RPN的核心是计算相似度特征图,对于辅助特征图以及查询特征图,相似度特征图计算如上。辅助特征用来作为核在查询特征图上进行类似depth-wise卷积的滑动。在实际中,查询特征采用RPN的输入特征,用于卷积的辅助特征大小为,由global average产生,在获得attention特征后,使用卷积进一步提取特征,然后接objectness分类和box预测,attention RPN的loss 会跟Faster R-CNN一样加入到模型的训练中
Attention RPN的核心是计算相似度特征图,对于辅助特征图以及查询特征图,相似度特征图计算如上。辅助特征用来作为核在查询特征图上进行类似depth-wise卷积的滑动。在实际中,查询特征采用RPN的输入特征,用于卷积的辅助特征大小为,由global average产生,在获得attention特征后,使用卷积进一步提取特征,然后接objectness分类和box预测,attention RPN的loss 会跟Faster R-CNN一样加入到模型的训练中Multi-Relation Detector
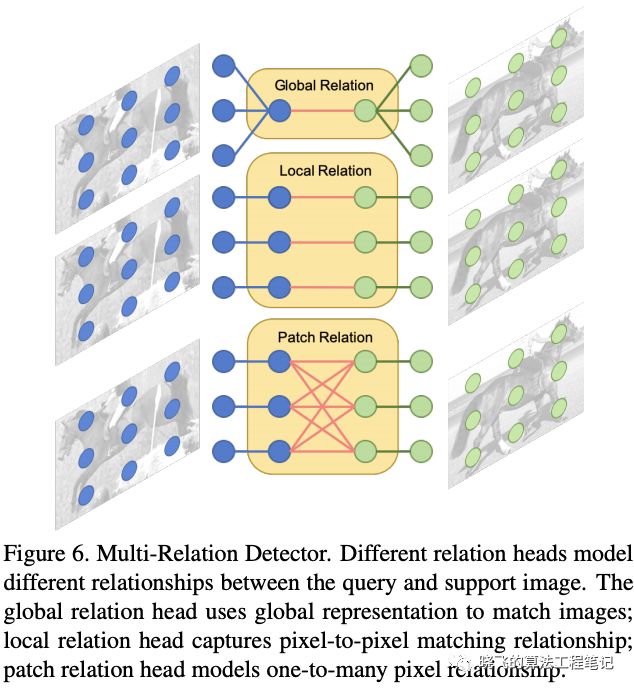 RPN后面一般会接一个检测器用于对proposal进行重新评估和调整,而论文则希望检测器能够有强大的类别区分能力,提出了多关系检测器(multi-relation detector)来度量相似性.该检测器包含3个attention相似性模块,将3个模块的分数求和作为最终的匹配分数。对于大小均为的辅助特征和查询特征:
RPN后面一般会接一个检测器用于对proposal进行重新评估和调整,而论文则希望检测器能够有强大的类别区分能力,提出了多关系检测器(multi-relation detector)来度量相似性.该检测器包含3个attention相似性模块,将3个模块的分数求和作为最终的匹配分数。对于大小均为的辅助特征和查询特征:- global-relation head,用于学习全局匹配的深层embedding。将和concatenate成特征,然后平均池化成,最后用加ReLU的两层全连接层输出最后的分数
- local-correlation head,学习pixel-wise和depth-wise的关系,即对应位置的关系。首先使用卷积分别操作和,使用前面的Attention RPN的相似性计算进行depth-wise的相似性计算获得相似性特征图,,最后用单层全连接层获得分数
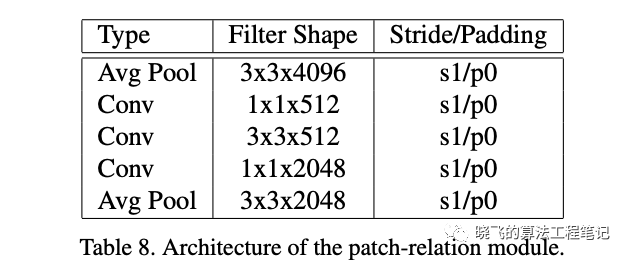
- patch-relation head,用于学习非线性的块匹配,即一对多的关系。将和concatenate成特征,然后输出到表8的块关系模块中,表8的卷积层后面都接ReLU,所有卷积层和池化层都进行0填充,模块将特征图从下采样为(这里池化层的s1/p0感觉描述不清楚,等源码放出来再看看),最后同时接两个全连接层,一个全连接产生匹配分数,另外一个产生bbox的预测
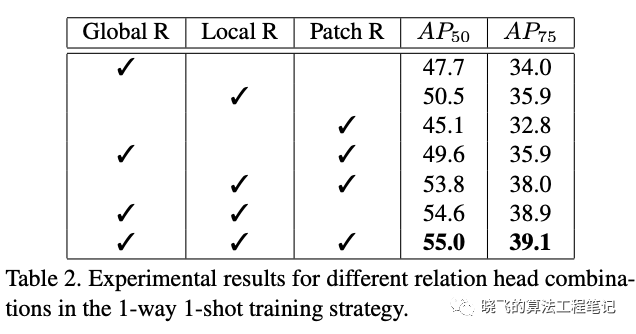 论文对3种head的重要性进行了实验,可以看到这3种head能很好地互补,结合起来能够完整地表达目标间的关系。
论文对3种head的重要性进行了实验,可以看到这3种head能很好地互补,结合起来能够完整地表达目标间的关系。Two-way Contrastive Training Strategy
通常少样本训练策略为每次输入为,论文认为模型应该同时学习识别同类别和区分不同类别,提出2-way对比训练策略。 如图7,该策略每轮随机选择一张查询图片、一张辅助图片以及一张别的类别的辅助图片组成三元组,查询图片中只有类目标标记为前景。在训练时,不仅学习间的相似性,也学习间的差异性。由于背景proposal的数量比较大,占据着训练过程,所以、和控制为1:2:1比例,根据匹配分数从高到低选择。每个proposal的损失为,匹配损失使用二值交叉熵。
如图7,该策略每轮随机选择一张查询图片、一张辅助图片以及一张别的类别的辅助图片组成三元组,查询图片中只有类目标标记为前景。在训练时,不仅学习间的相似性,也学习间的差异性。由于背景proposal的数量比较大,占据着训练过程,所以、和控制为1:2:1比例,根据匹配分数从高到低选择。每个proposal的损失为,匹配损失使用二值交叉熵。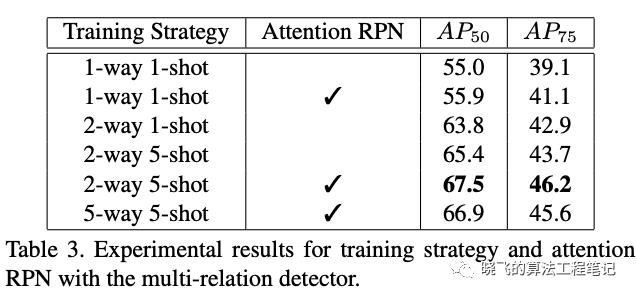 论文对不同的训练策略进行了对比,2-way 5-shot对比训练策略效果最优,并且可以看到attention RPN也是有效的,提升了1.9。
论文对不同的训练策略进行了对比,2-way 5-shot对比训练策略效果最优,并且可以看到attention RPN也是有效的,提升了1.9。 实验
实验Training Details
查询图片短边为600像素,长边上限1000像素,辅助图片裁剪目标区域加16像素的位置,resize然后0填充至,在推理时,相同类别的辅助集使用平均特征集Comparison with State-of-the-Art Methods
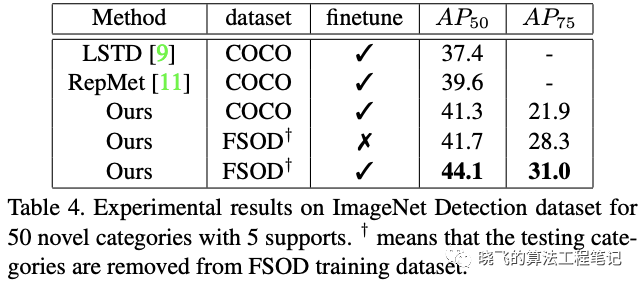
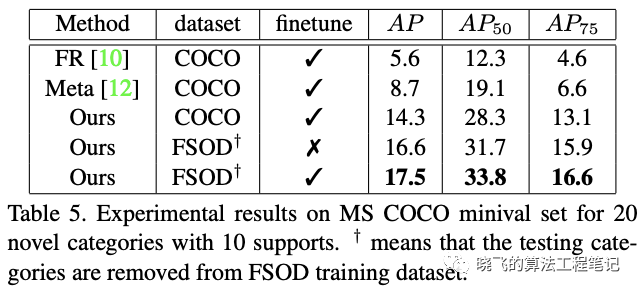 这里表格的finetune是指直接在测试集上进行finetune
这里表格的finetune是指直接在测试集上进行finetuneRealistic Applications


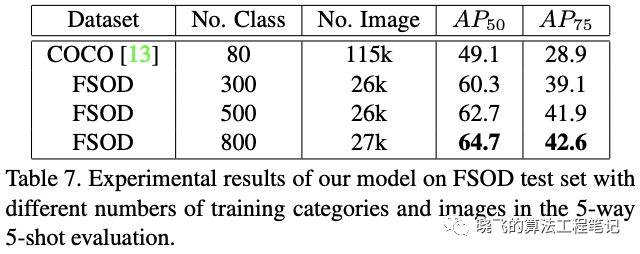
More Categories vs More Samples?

结论
论文提出了新的少样本目标检测算法,创新点包括Attention-RPN、多关系检测器以及对比训练策略,另外还构建了包含1000类的少样本检测数据集FSOD,在FSOD上训练得到的论文模型能够直接迁移到新类别的检测中,不需要fine-tune。
论文地址:https://arxiv.org/abs/1908.01998【end】◆
原力计划
◆
《原力计划【第二季】- 学习力挑战》正式开始!即日起至 3月21日,千万流量支持原创作者!更有专属【勋章】等你来挑战 推荐阅读
推荐阅读2019年度优快云博客之星TOP10榜单揭晓,你上榜了吗?
Javascript函数之深入浅出递归思想,附案例与代码!
不看就亏系列!这里有完整的 Hadoop 集群搭建教程,和最易懂的 Hadoop 概念!| 附代码
智能合约编写之Solidity的基础特性
微信七年「封链」史
计算机博士、加班到凌晨也要化妆、段子手……IT 女神驾到!

你点的每个“在看”,我都认真当成了AI


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









