







 本文探讨了日志采集Agent的设计,包括如何发现和跟踪文件,点位文件的高可用性,文件识别,以及如何安全地释放文件句柄。介绍了业界常用的日志采集工具如Fluentd和Logstash,并分析了推模式日志采集的工作原理。通过结合Inotify和轮询策略解决文件发现问题,利用点位文件记录采集位置,通过文件inode和dev来标识文件,使用xattr或文件内容来解决文件重复问题。最后讨论了文件内容更新检测和安全释放文件句柄的挑战。
本文探讨了日志采集Agent的设计,包括如何发现和跟踪文件,点位文件的高可用性,文件识别,以及如何安全地释放文件句柄。介绍了业界常用的日志采集工具如Fluentd和Logstash,并分析了推模式日志采集的工作原理。通过结合Inotify和轮询策略解决文件发现问题,利用点位文件记录采集位置,通过文件inode和dev来标识文件,使用xattr或文件内容来解决文件重复问题。最后讨论了文件内容更新检测和安全释放文件句柄的挑战。
学最好的别人,做最好的我们
概述
日志从最初面向人类演变到现在的面向机器发生了巨大的变化。最初的日志主要的消费者是软件工程师,他们通过读取日志来排查问题,如今,大量机器日夜处理日志数据以生成可读性的报告以此来帮助人类做出决策。在这个转变的过程中,日志采集Agent在其中扮演着重要的角色。
作为一个日志采集的Agent简单来看其实就是一个将数据从源端投递到目的端的程序,通常目的端是一个具备数据订阅功能的集中存储,这么做的目的其实是为了将日志分析和日志存储解耦,同一份日志可能会有不同的消费者感兴趣,获取到日志后所处理的方式也会有所不同,通过将数据存储和数据分析进行解耦后,不同的消费者可以订阅自己感兴趣的日志,选择对应的分析工具进行分析。
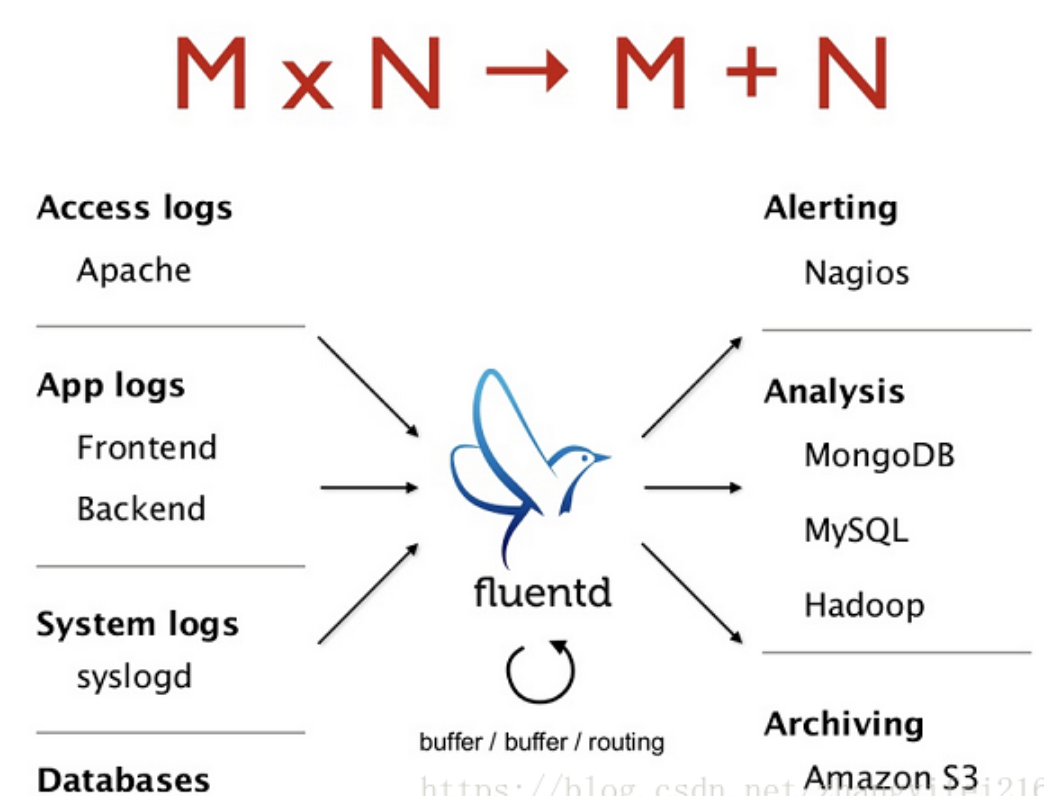
像这样的具备数据订阅功能的集中存储业界比较流行的是Kafka,对应到阿里巴巴内部就是DataHub还有阿里云的LogHub。而数据源端大致可以分为三类,一类就是普通的文本文件,另外一类则是通过网络接收到的日志数据,最后一类则是通过共享内存的方式,本文只会谈及第一类。一个日志采集Agent最为核心的功能大致就是这个样子了。在这个基础上进一步又可以引入日志过滤、日志格式化、路由等功能,看起来就好像是一个生产车间。从日志投递的方式来看,日志采集又可以分为推模式和拉模式,本文主要分析的是推模式的日志采集。
推模式是指日志采集Agent主动从源端取得数据后发送给目的端,而拉模式指的是目的端主动向日志采集Agent获取源端的数据。
业界现状
目前业界比较流行的日志采集主要有Fluentd、Logstash、Flume、scribe等,阿里巴巴内部则是LogAgent、阿里云则是LogTail,这些产品中Fluentd占据了绝对的优势并成功入驻CNCF阵营,它提出的统一日志层(Unified Logging Layer)大大的减少了整个日志采集和分析的复杂度。
Fluentd认为大多数现存的日志格式其结构化都很弱,这得益于人类出色的解析日志数据的能力,因为日志数据其最初是面向人类的,人类是其主要的日志数据消费者。为此Fluentd希望通过统一日志存储格式来降低整个日志采集接入的复杂度,假想下输入的日志数据比如有M种格式,日志采集Agent后端接入了N种存储,那么每一种存储系统需要实现M种日志格式解析的功能,总的复杂度就是M*N,如果日志采集Agent统一了日志格式那么总的复杂度就变成了M + N。
这就是Fluentd的核心思想,另外它的插件机制也是一个值得称赞的地方。Logstash和Fluentd类似是属于ELK技术栈,在业界也被广泛使用,关于两者的对比可以参考这篇文章 Fluentd vs. Logstash: A Comparison of Log Collectors: https://logz.io/blog/fluentd-logstash/
从头开始写一个日志采集Agent
作为一个日志采集Agent在大多数人眼中可能就是一个数据“搬运工”,还会经常抱怨这个“搬运工”用了太多的机器资源,简单来看就是一个tail -f命令,再贴切不过了,对应到Fluentd里面就是in_tail插件。
笔者作为一个亲身实践过日志采集Agent的开发者,希望通过本篇文章来给大家普及下日志采集Agent开发过程中的一些技术挑战。为了让整篇文章脉络是连续的,笔
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









