







 本文详细介绍了HashMap的概念、底层原理,包括JDK1.8后采用的“数组+链表/红黑树”结构,以及HashMap的put、get操作,扩容机制resize(),为何长度是2的幂次方,以及线程安全问题。HashMap是非线程安全的,解决并发问题可使用ConcurrentHashMap。
本文详细介绍了HashMap的概念、底层原理,包括JDK1.8后采用的“数组+链表/红黑树”结构,以及HashMap的put、get操作,扩容机制resize(),为何长度是2的幂次方,以及线程安全问题。HashMap是非线程安全的,解决并发问题可使用ConcurrentHashMap。
重要!!!
前言知识
hashcode:哈希码不唯一,它是一种算法尽量让同一个类的不同对象拥有不同的哈希码,但是可能也会出现相同的情况。
一、HashMap一些概念
- HashMap是一个散列表,它存储的是键值对(key-value)映射。
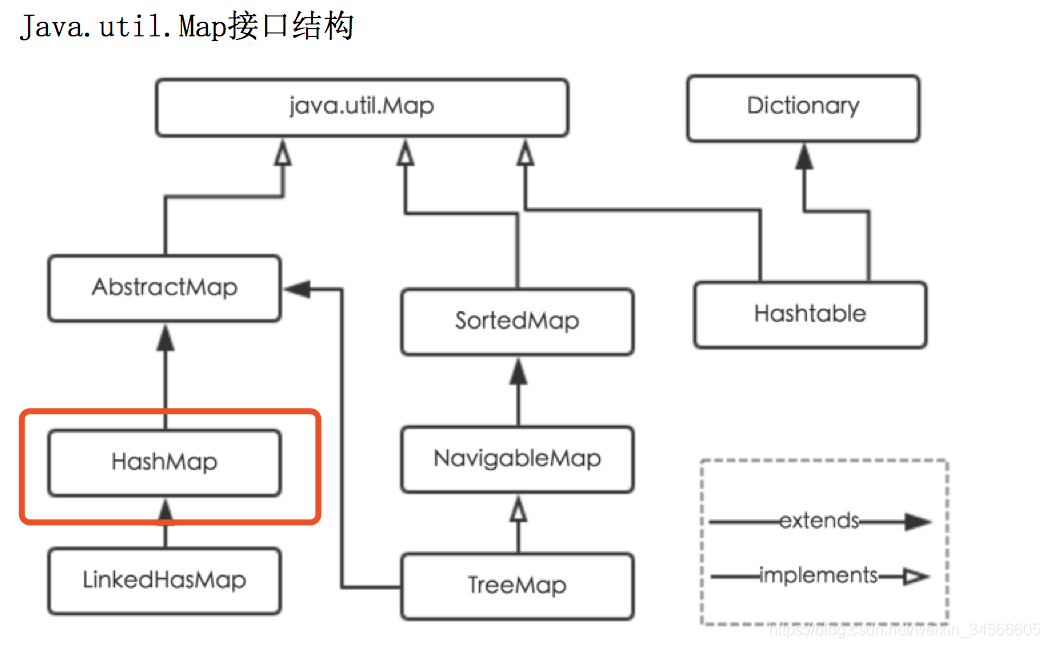
- HashMap继承AbstractMap类,实现了Map、Cloneable、java.io.Serializable接口。用一张图解释一下。
- HashMap的实现是不同步的,也就是说不是线程安全的
- HashMap的key唯一,value值可以重复。其中key,value都可以为null。
- HashMap的映射不是有序的,也就是说你做了一堆put操作后,遍历打印出来的数据顺序可能和你put的顺序不一致。
二、HashMap底层原理
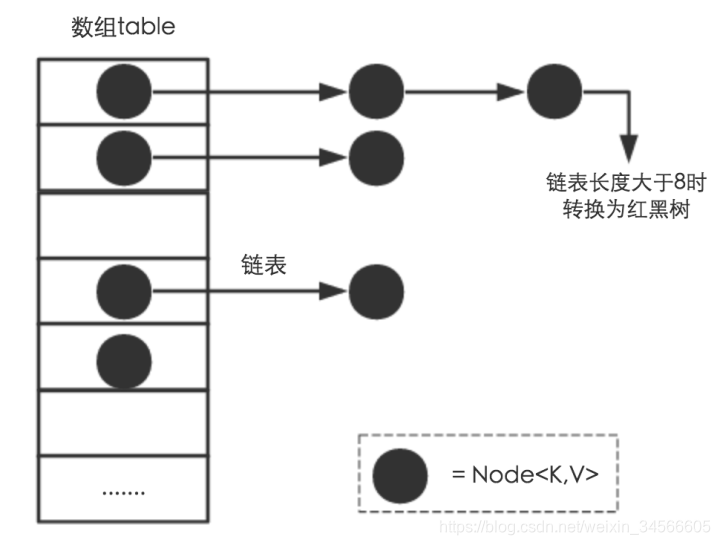
- JDK1.8之前HashMap是采用“数组+链表”(散列表)组成的。数组是hashMap的主体,链表是为了解决hash冲突,采用拉链法(链地址法)解决冲突。
- JDK1.8之后,解决Hash冲突发生了变化。当链表长度大于阈值(默认为8)时,将链表转换为红黑树,可以减少搜索时间。“数组+链表/红黑树”
疑问解答区:
1. 为什么要用红黑树?
链表过长的时候可能会导致查询的时间加大,TreeMap、TreeSet以及JDK1.8之后的HashMap底层都用到了红黑树。红黑树就是为了解决二叉搜索树的缺陷,因为二叉搜索树在某些情况下会退化成一个线性结构。
2. 链表什么时候会转换红黑树,红黑树什么时候转换回链表?
若bucket的链表元素>=8,则链表转换成红黑树结构。
若bucket的链表元素<=6,则红黑树转换成链表结构。
原因:链表平均查找长度为N/2,红黑树平均查找长度为logN。当元素个数为8时,链表平均查找长度为4,红黑树平均查找长度为3,所以转换成红黑树可以加快查找速度。当元素个数为6,链表平均查找长度为3和红黑树差不多,而且链表结构比较简单,所以采用链表就可以了。
三、HashMap的put操作、get操作
- HashMap的put方法实现
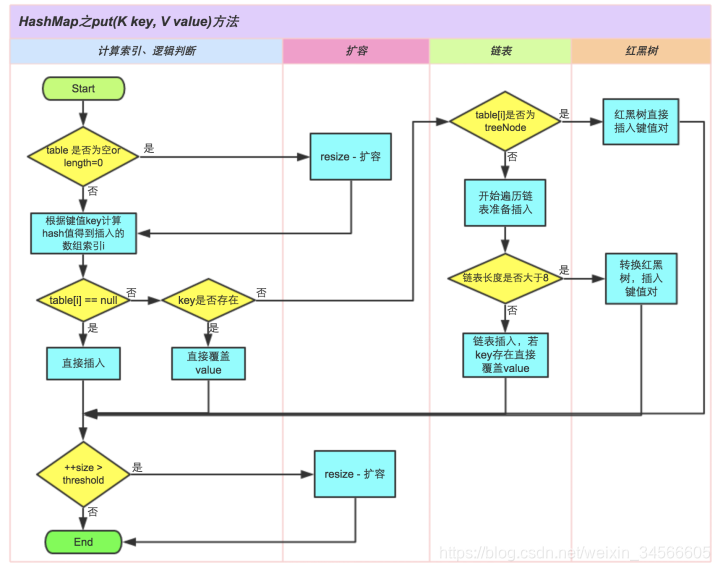
- 对key做hash,算出来bucket(数组索引)的位置
- 如果没有碰撞,直接放bucket里。
- 如果发生碰撞,则以链表的形式存在bucket后(不同key的hashcode相同,导致计算出来的hash值相同,会出现这种hash碰撞),若链表大于长度8,则转换为红黑树。
- 如果节点key已经存在则替换value值
- 如果bucket满了(超过了loadfactor*currentCapacity),就要resize。
将对象放入到集合中时,首先判断要放入对象的hashcode值与集合中的任意一个元素的hashcode值是否相等,如果不相等直接将该对象放入集合中。如果hashcode值相等,然后再通过equals方法判断要放入对象与集合中的任意一个对象是否相等,如果equals判断不相等,直接将该元素放入到集合中,否则不放入。
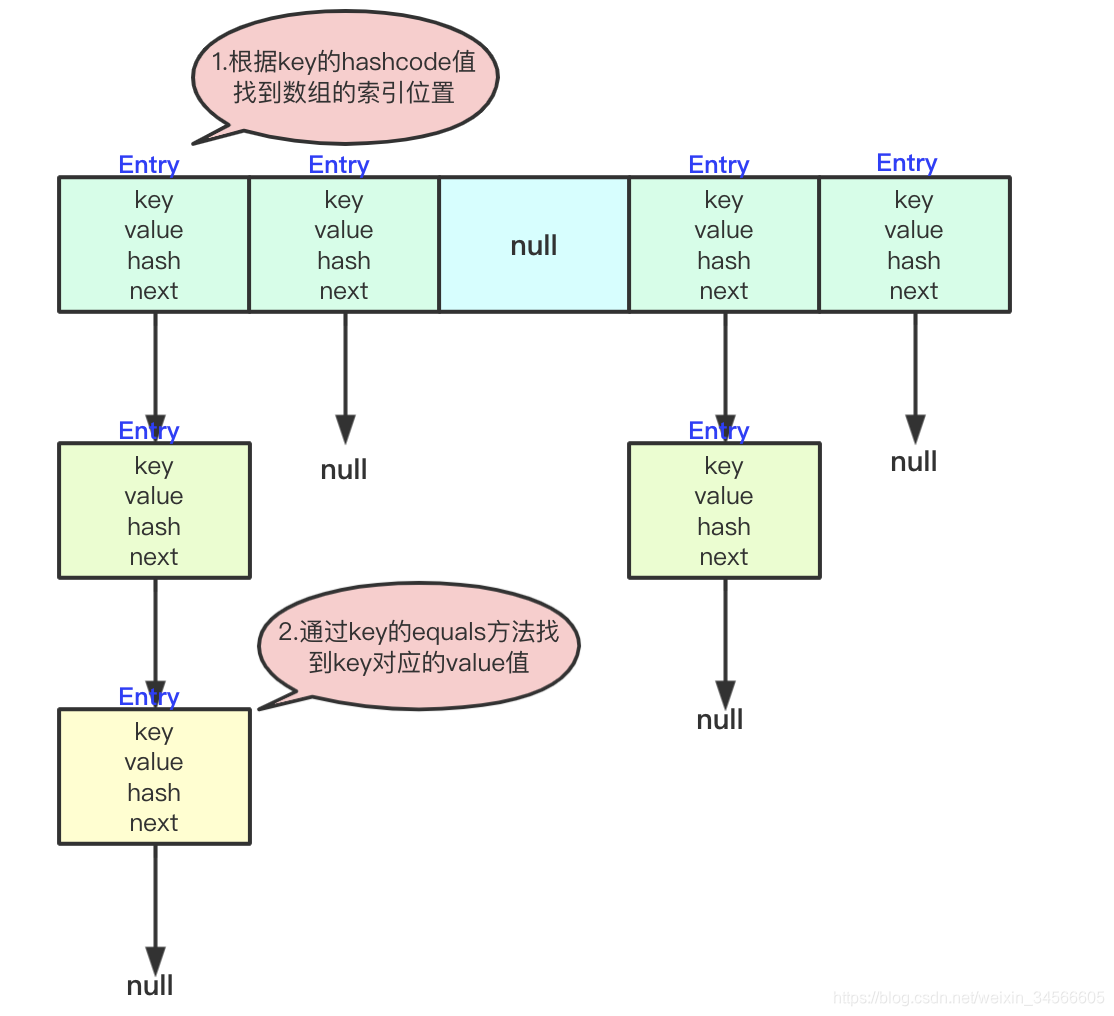
- HashMap的get操作
- 如果是bucket里的第一个节点,直接查找到值,时间复杂度为O(1);
- 如果有冲突,则通过key.equals(k)去查找对应的entry(key-value整体当成一个entry对象),【链表】时间复杂度为O(n),【红黑树】时间复杂度为O(logn)。
hashcode()和equals()关系
1.equal()相等的两个对象他们的hashCode()肯定相等,也就是用equal()对比是绝对可靠的。
2.hashCode()相等的两个对象他们的equal()不一定相等,也就是hashCode()不是绝对可靠的。
总结:
hashmap在底层将key-value当成一个整体进行处理,叫entry对象。hashmap底层采用一个entry[]数组来保存所有的key-value对,当需要存储一个entry对象时,会根据hash算法来决定其在数组中的存储位置,再根据equals方法决定其在该数组位置上的链表中的存储位置,当需要取出一个entry时,也会根据hash算法找到其在数组中的存储位置,再根据equals方法从该位置上的链表中取出该entry。
四、HashMap的扩容机制resize()
为什么要扩容?当hashmap中元素越来越多,碰撞几率也越来越大,为了提高查询效率,需要对数组进行扩容,进行rehash的过程。
什么时候扩容?当元素个数>=loadfactor*capacity,(loadFactor默认0.75,capacity初始值16),也就是第一次扩容是数组元素超过阈值12的时候,且新建的Entry刚好落在一个非空的桶上,此刻触发扩容机制,将其容量扩大为2倍。
注意⚠️: 当size大于等于threshold的时候,并不一定会触发扩容机制(比如增加的entry对应的是一个空桶,那直接加载空桶里面,如果对应的不是空桶,会将链表拉长,就会触发扩容),但是会很可能就触发扩容机制,只要有一个新建的Entry出现哈希冲突,则立刻resize。

怎么扩容呢?第一次hashmap没有任何值的时候,数组直接扩成长度16,然后超过阈值12时,创建一个新数组,扩大一倍,然后重新计算每个元素在数组中的位置。以后每次都扩大一倍。

Jdk7中创建对象时,则初始化table容量为16(饿汉式)。
Jdk8中创建对象时,并没有初始化,而是第一次添加元素时初始化table变量为16(懒汉式)。
五、HashMap的长度为什么是2的幂次方
原因1:
看下图,左边两组是数组长度为16(2的4次方),右边两组是数组长度为15。两组的hashcode均为8和9,但是很明显,当它们和1110“&”的时候,产生了相同的结果,也就是说它们会定位到数组中的同一个位置上去,这就产生了碰撞,8和9会被放到同一个链表上,那么查询的时候就需要遍历这个链表,得到8或者9,这样就降低了查询的效率。同时,我们也可以发现,当数组长度为15的时候,hashcode的值会与14(1110)进行“与”,那么最后一位永远是0,而0001,0011,0101,1001,1011,0111,1101这几个位置永远都不能存放元素了,空间浪费相当大,更糟的是这种情况中,数组可以使用的位置比数组长度小了很多,这意味着进一步增加了碰撞的几率,减慢了查询的效率! 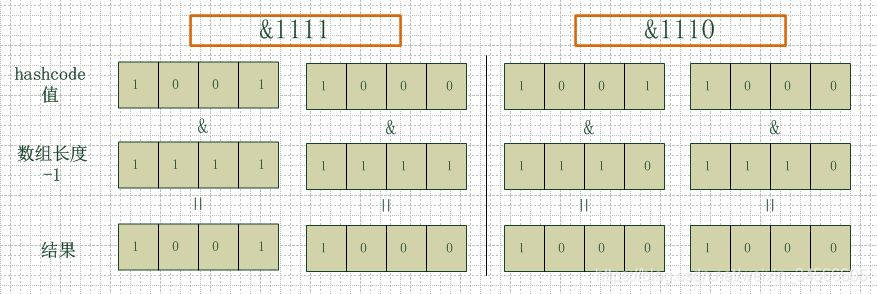
所以说,当数组长度为2的n次幂的时候,**不同的key算得得index相同的几率较小,那么数据在数组上分布就比较均匀,**也就是说碰撞的几率小,相对的,查询的时候就不用遍历某个位置上的链表,这样查询效率也就较高了。
原因2:
为了HashMap存取高效,尽量减少碰撞,就要尽量让数据分配均匀,让每个链表/红黑树长度大致相同。解决这个问题可以采用取余(取模)来实现,【当length是2的次幂时,hash%length==hash&(length-1)】,又二进制&比%更能提高运算效率。所以采用了&操作,前提是HashMap的长度必须是2的幂次方。
HashMap中的hash算法(源码实现):
方法一:
static final int hash(Object key) { //jdk1.8 & jdk1.7
int h;
// h = key.hashCode() 为第一步 取hashCode值
// h ^ (h >>> 16) 为第二步 高位参与运算
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
方法二:
static int indexFor(int h, int length) { //jdk1.7的源码,jdk1.8没有这个方法,但是实现原理一样的
return h & (length-1); //第三步 取模运算
}
Hash算法本质上就是三步:取key的hashCode值(h)、高位运算、取模运算。取模运算为h & (table.length -1)来得到该对象的保存位,当length总是2的n次方时,h& (length-1)运算等价于对length取模【length=2^n时,h& (length-1) == h% length】,也就是h%length,但是&比%具有更高的效率。如下:(n为table长度length)
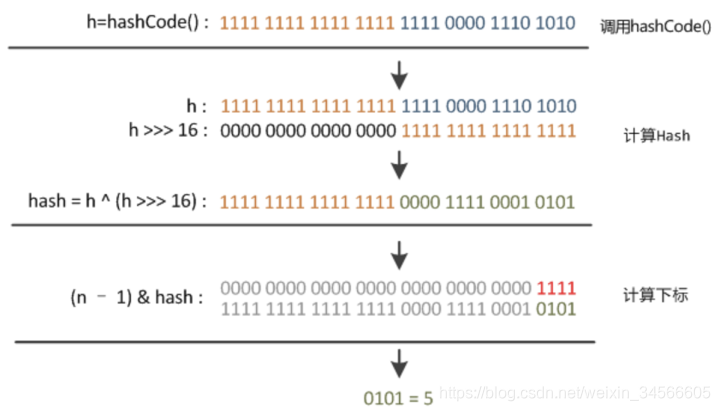
hashmap中数组默认长度为16
六、HashMap的线程安全问题
- jdk7中hashmap并发put操作同时触发resize会造成循环链表,导致get出现死循环。【该问题jdk8中已经解决】
transfer代码如下:
do {
Entry<K,V> next = e.next;// <–假设线程一执行到这里就被调度挂起了
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
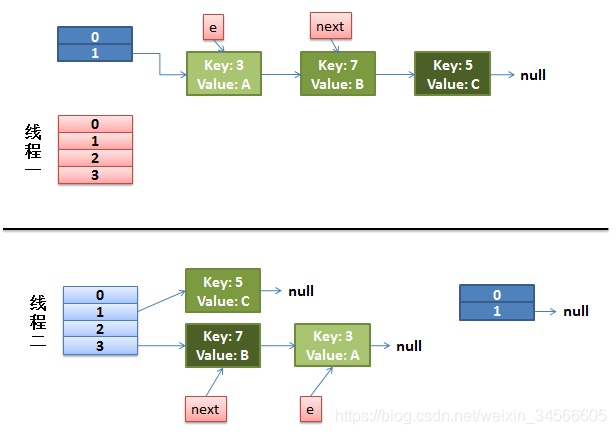
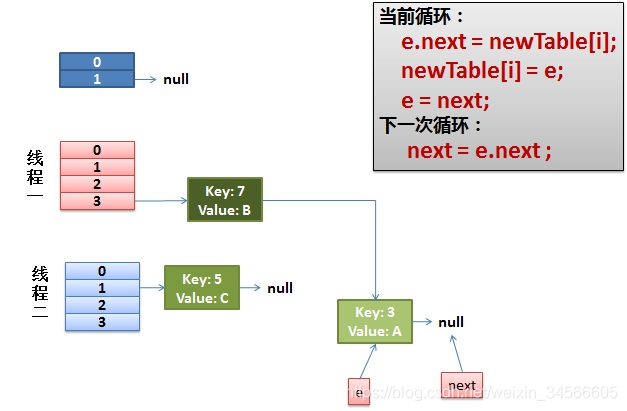
1)假设两个线程,其中线程1执行到一半挂起,时间片分给了线程2,线程2执行完成。出现下面的情况:
这时,线程1的e指向了key(3),next指向了key(7),而线程2在rehash后,e和next的位置发生了变化。
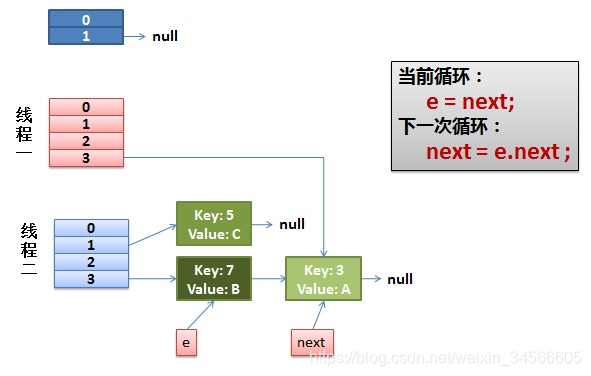
2)线程1结束挂起后开始执行,
先执行newTable[i]=e;
然后e=next,导致e指向了key(7)
下一次循环的next=e.next导致next指向了key(3)
线程一接着工作。把key(7)摘下来,放到newTable[i]的第一个,然后把e和next往下移。
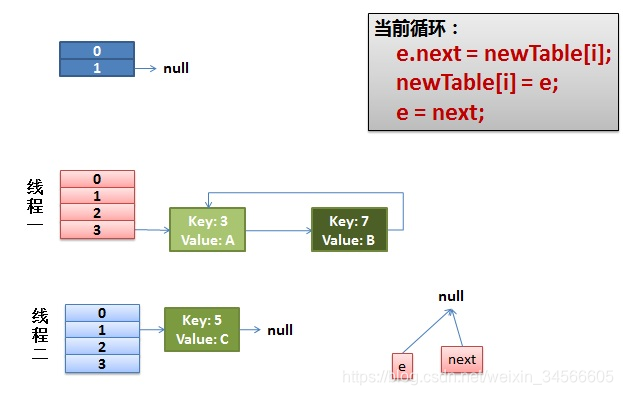
4)环形链接出现。
e.next = newTable[i] 导致 key(3).next 指向了 key(7)
注意:此时的key(7).next 已经指向了key(3), 环形链表就这样出现了。
于是当我们进行get操作,比如get(11)时,遍历索引3所在的链表,由于是循环链表,所以永远也不会结束。。。
- 多个线程进行put操作时,可能触发resize操作,如果产生hash碰撞,导致两个线程在得到相同的索引去存储值,可能会出现覆盖丢失的情况。
解决方案:
- 使用Hashtable类替换HashMap(现在一般不用这个了) ,HashTable是线程安全的。
- 使用ConcurrentHashMap替换HashMap,具有分段锁,也是线程安全的。
- 使用Collection.synchronizedMap将HashMap包装起来。
参考文章:
https://www.jb51.net/article/113433.htm
cnblogs.com/williamjie/p/9358291.html
https://www.jianshu.com/p/c3633291ecda
https://www.cnblogs.com/andy-zhou/p/5402984.html


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









