







简介:在图像处理中,超级分辨率技术能够将低分辨率图像转换为高分辨率图像以提升清晰度和细节。OpenCV的超级分辨率模块基于快速超分辨率卷积神经网络(SRCNN),该模型包含预处理、特征提取与上采样和后处理的卷积层。OpenCV提供了预训练模型,支持从头训练和微调,且其Python API允许用户轻松应用超级分辨率技术。此外,模块支持硬件加速,提高了处理速度,并兼容其他高级超分模型。超级分辨率技术在多个领域有广泛的应用,如监控视频增强、医疗影像分析等。 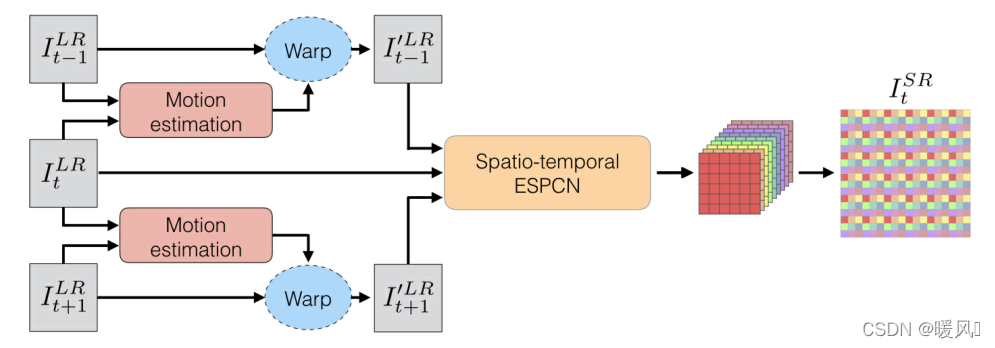
1. 超级分辨率技术概述
在数字图像处理领域,超级分辨率技术(Super-Resolution, SR)已成为一个研究热点,其核心目的是从低分辨率图像中恢复出高分辨率版本。随着计算机视觉和深度学习的发展,SR技术已经由传统方法转变为更多依赖于复杂神经网络模型的实现方式。本章旨在为读者提供SR技术的基本概念、发展历程以及当前的应用现状和未来趋势。
1.1 超级分辨率技术的起源与发展
超级分辨率技术的起源可以追溯到上个世纪九十年代,最初的方法主要基于插值和频域分析等数学技术。然而,随着研究的深入,学者们逐渐认识到仅依靠传统的算法难以克服物理成像系统的限制。进入21世纪后,深度学习技术的兴起为图像超分辨率带来了新的转机,尤其是卷积神经网络(CNN)的引入,有效提升了SR处理的效果和效率。
1.2 当前超级分辨率技术的应用领域
超级分辨率技术在众多领域中都具有重要的应用价值。例如,在卫星遥感、医学成像、视频监控、虚拟现实以及增强现实(AR/VR)等应用场景中,SR技术能够提供更高清晰度的图像,从而辅助专业人士做出更为精确的判断。此外,随着智能手机和网络视频内容的普及,超分辨率技术在消费电子市场也得到了广泛应用,改善用户体验的同时,进一步推动了技术的商业化进程。
2. OpenCV超级分辨率模块介绍
2.1 OpenCV简介及其对超级分辨率的支持
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉和机器学习软件库,它包含了大量的计算机视觉和机器学习算法。OpenCV在支持多种操作系统的同时,提供了C++、Python、Java等多种语言的接口,并且有广泛的社区支持和文档资源。超级分辨率(Super Resolution, SR)作为计算机视觉中的一个重要分支,通过软件技术提升图像分辨率,OpenCV在其多个版本中逐步引入了对SR技术的支持。
随着技术的发展,OpenCV开始集成更先进的超级分辨率方法,如SRCNN(Super-Resolution Convolutional Neural Network)。这些集成使得OpenCV不仅限于传统的插值方法,而是支持端到端的深度学习方法,极大地提高了超分辨率重建的准确度和图像质量。OpenCV在后续版本中不断优化和更新其超级分辨率模块,以适应不同的应用场景和需求。
2.2 安装与配置OpenCV超级分辨率模块
OpenCV可以被安装在多种操作系统上,包括Windows、Linux和macOS。安装和配置OpenCV超级分辨率模块通常涉及以下步骤:
-
安装OpenCV库 :确保安装了最新版本的OpenCV,或者至少是支持超级分辨率功能的版本。这可以通过包管理器或者从源代码编译来完成。
```bash
Ubuntu 示例安装命令
sudo apt-get install python3-opencv ```
```bash
使用pip安装
pip install opencv-python ```
-
下载并安装超级分辨率模块 :根据OpenCV版本,下载相应的超级分辨率模块。在某些版本中,超级分辨率可能作为单独的扩展模块提供。
```python
Python 示例代码
import cv2
确保加载了超级分辨率模块
dnn_superres = cv2.dnn_superres.DnnSuperResImpl_create() ```
-
确认超级分辨率功能的可用性 :在代码中加载并配置超级分辨率模块,确认功能的可用性。
```python
示例代码验证安装是否成功
dnn_superres.readModel('EDSR_x4.pb') # 以ESDR模型为例,需提供模型路径 dnn_superres.setModel("edsr", 4) # 设置模型名称及放大因子 print("DNN SuperRes model loaded: EDSR x4") ```
2.3 模块的架构及主要功能组件
OpenCV超级分辨率模块的架构设计以模块化和灵活性为特点,允许用户在不同的应用场景下灵活使用不同的超级分辨率算法。模块的主要功能组件包括:
-
算法支持 :OpenCV超级分辨率模块目前支持多种算法,如FSRCNN、ESPCN、EDSR等,用户可以根据需要选择合适的算法。
-
模型管理 :提供模型加载、保存和使用等功能。用户可以使用内置模型或者导入自定义模型进行超分辨率处理。
-
超分辨率处理 :包括放大图像、图像增强等主要功能,可以根据不同场景调整参数,实现最佳的超分辨率效果。
```python
示例代码展示如何使用OpenCV进行超级分辨率处理
import cv2 import numpy as np
img = cv2.imread('input.jpg') dnn_superres = cv2.dnn_superres.DnnSuperResImpl_create()
加载预训练模型
dnn_superres.readModel('ESPCN.pb') dnn_superres.setModel("espcn", 3) # 放大因子为3
应用超级分辨率模型
output_img = dnn_superres.upsample(img) cv2.imwrite('output.jpg', output_img) ```
-
质量评估 :提供评估指标,帮助用户评估和比较不同超分辨率算法的效果。
```python
示例代码展示如何评估超分辨率效果
dnn_superres.upsample(img) score = dnn_superres.compareImages(img, output_img, cv2.MSE) print(f"Mean Squared Error between original and super-resolved image: {score}") ```
OpenCV的超级分辨率模块是一个不断进步和发展的项目,随着新算法的加入和现有算法的优化,它将继续在计算机视觉领域发挥重要的作用。
3. SRCNN模型结构与应用
3.1 SRCNN模型的理论基础与设计思想
SRCNN(Super-Resolution Convolutional Neural Network)是最早提出的深度学习方法之一,用于单图像超分辨率(Single Image Super-Resolution, SISR)。它的提出开启了深度学习在图像超分辨率领域的广泛应用。SRCNN的理论基础是利用深度卷积神经网络通过学习低分辨率(LR)图像到高分辨率(HR)图像的非线性映射关系来实现图像的重建。
设计SRCNN时,研究者们基于以下几个核心思想: 1. 特征提取 :首先从LR图像中提取有用信息。这一过程通常通过卷积层完成,每个卷积层由一系列滤波器组成,负责提取不同特征,如边缘、纹理等。 2. 非线性映射 :通过非线性激活函数(如ReLU)将提取的特征映射到一个非线性空间,以增强网络的表达能力。 3. 上采样与重建 :将映射后的特征通过上采样技术恢复到HR图像的尺寸,最后通过一个卷积层生成最终的HR图像。
SRCNN模型简单且高效,它为后续的复杂网络结构提供了基础,并在超分辨率领域中展现出显著的性能。
3.2 SRCNN模型的构建与训练过程
SRCNN模型通常包括三个卷积层:第一层用于提取特征,第二层执行非线性映射,第三层进行上采样和重建。每个卷积层后面通常会跟一个非线性激活函数,常见的选择是ReLU函数。上采样技术是 SRCNN 中的核心,通过它将 LR 特征映射到 HR 特征。
构建SRCNN模型需要选择合适的损失函数。损失函数衡量了预测的HR图像与真实HR图像之间的差异,常用的损失函数为均方误差(MSE):
import keras.backend as K
def mean_squared_error(y_true, y_pred):
return K.mean(K.square(y_pred - y_true), axis=-1)
训练SRCNN模型涉及到调整网络权重以最小化损失函数。这一步骤通常通过反向传播算法来完成,它利用梯度下降法对网络参数进行优化。训练过程中需要配置适当的优化器,如Adam或者SGD。
from keras.optimizers import Adam
model.compile(optimizer=Adam(lr=0.001), loss=mean_squared_error)
在开始训练之前,需要准备好训练数据集,将其划分为训练集和验证集。训练数据通常需要经过标准化处理,并以固定批量大小输入到模型中。
训练过程如下:
history = model.fit(x_train, y_train, validation_data=(x_val, y_val), epochs=100)
训练完成后,需要评估模型在测试集上的性能,确保模型具备良好的泛化能力。
3.3 SRCNN在图像复原中的应用案例分析
SRCNN在图像复原任务中展现了其强大的能力,特别是在从低分辨率图像恢复高分辨率图像的应用场景中。例如,将老旧或模糊的视频画面转换为高清版本,或者在卫星图像中提高细节分辨率以辅助解译工作。
案例分析的一个重要方面是实际操作步骤,包括数据准备、模型应用和结果评估。对于 SRCNN,实际操作包括以下几个步骤:
- 数据准备 :准备一个包含LR图像和对应HR图像的数据集。数据集需要经过预处理,包括归一化、增强等。
- 模型构建 :基于 SRCNN 结构构建模型,并根据实际情况选择合适的网络参数。
- 模型训练 :使用训练数据对模型进行训练,监控训练进度和性能,并在必要时进行调整。
- 模型应用 :将训练好的模型应用于新的LR图像,进行超分辨率重建。
- 结果评估 :使用不同的质量评估指标(如 PSNR、SSIM)对超分辨率结果进行评价,并与其他方法进行比较。
通过这些步骤,可以有效地应用SRCNN模型于实际图像复原问题,并得到高质量的超分辨率图像。接下来,我们以一个具体的代码块来展示 SRCNN 在图像复原中的应用:
from keras.models import load_model
from keras.preprocessing import image
import numpy as np
# 加载训练好的模型
model = load_model('srcnn_model.h5')
# 预处理图像(调整大小、归一化等)
def preprocess_image(lr_image):
# 图像大小调整、归一化等
pass
# 超分辨率重建
def super_resolve(model, lr_image):
preprocessed_image = preprocess_image(lr_image)
sr_image = model.predict(np.array([preprocessed_image]))[0]
sr_image = sr_image.clip(0, 1) # 确保像素值在合理范围内
return sr_image
# 加载低分辨率图像
lr_img_path = 'path_to_lr_image.jpg'
lr_image = image.load_img(lr_img_path, target_size=(240, 320))
lr_image = image.img_to_array(lr_image)
lr_image = np.expand_dims(lr_image, axis=0)
# 应用SRCNN模型
sr_image = super_resolve(model, lr_image)
# 展示原始图像和超分辨率图像
from matplotlib import pyplot as plt
plt.imshow(lr_image[0])
plt.show()
plt.imshow(sr_image)
plt.show()
在上述代码中,我们首先加载了预训练的SRCNN模型,然后定义了两个函数: preprocess_image 用于图像预处理, super_resolve 用于超分辨率重建。最后,我们加载一张低分辨率图像,对其进行处理和重建,并展示重建前后的图像对比。通过这个过程,SRCNN在图像复原中的应用被具体地展现出来。
4. 预处理与后处理步骤详解
4.1 图像预处理的重要性与方法
4.1.1 输入图像的格式转换与尺寸调整
在使用超级分辨率技术之前,对输入图像进行格式转换与尺寸调整是至关重要的一步。图像格式的转换通常涉及对图像数据的读取和写入,而图像尺寸的调整则涉及到分辨率的改变,这两者都是为了更好地适应后续处理步骤的需要。
以下是使用Python进行图像格式转换与尺寸调整的一个实例:
import cv2
import numpy as np
# 读取图像
img = cv2.imread('input.jpg')
# 将图像从BGR转换为RGB格式
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 读取图像尺寸
height, width, channels = img_rgb.shape
# 将图像尺寸调整为600x400
img_resized = cv2.resize(img_rgb, (400, 600), interpolation=cv2.INTER_AREA)
# 保存转换后的图像
cv2.imwrite('resized.jpg', img_resized)
在此段代码中,我们首先读取了一张名为 input.jpg 的图像,并将其从OpenCV默认的BGR格式转换为RGB格式,以便于和其他很多图像处理库兼容。接着,我们获取了图像的原始尺寸,并使用 cv2.resize 函数将其调整为指定的尺寸。这里我们采用了 INTER_AREA 插值方法,它通常用于缩小图像时能够较好地保持图像的质量。最后,调整后的图像被保存为 resized.jpg 。
格式转换与尺寸调整的目的是为了确保输入图像能够被超级分辨率模型正确处理,同时保证处理后的图像在视觉效果上没有出现不希望的失真。
4.1.2 噪声去除与边缘增强技术
噪声去除是图像预处理中的另一个关键步骤,因为噪声可能会对超分辨率模型的性能产生负面影响,特别是对于那些依赖于精细细节的模型而言。边缘增强则是为了改善图像的视觉效果,使得图像的细节更加清晰。
以下是如何使用OpenCV进行噪声去除和边缘增强的示例:
# 创建一个高斯滤波器进行噪声去除
blurred_img = cv2.GaussianBlur(img_resized, (5, 5), 0)
# 使用Canny算子进行边缘检测
edges = cv2.Canny(blurred_img, 100, 200)
# 使用拉普拉斯算子进行边缘增强
laplacian_img = cv2.Laplacian(img_resized, cv2.CV_64F).astype(np.uint8)
# 保存处理后的图像
cv2.imwrite('blurred.jpg', blurred_img)
cv2.imwrite('edges.jpg', edges)
cv2.imwrite('laplacian.jpg', laplacian_img)
在该段代码中,我们首先使用高斯滤波器对图像进行模糊处理,从而去除噪声。高斯滤波通过计算图像每个像素点周围邻域的加权平均值来实现,其中 cv2.GaussianBlur 函数中的 (5, 5) 表示了核的大小,而 0 表示了核的标准差。接着,我们使用Canny算子来检测图像中的边缘,并将边缘图像保存下来。最后,使用拉普拉斯算子来增强边缘,并同样保存处理后的图像。
噪声去除和边缘增强的处理过程不仅能够改善图像的质量,还可以帮助超级分辨率模型提取更加准确的特征,进而提高图像复原的效果。
4.2 后处理技术的实现与优化
4.2.1 模型输出的图像处理技术
在超级分辨率模型的输出图像上进行后处理是一个重要的步骤,可以进一步提升图像质量。常见的后处理技术包括锐化、色彩平衡调整和亮度/对比度调整等。这些技术可以增强模型输出的视觉效果,使图像看起来更加清晰和自然。
下面是一个使用OpenCV进行简单的后处理操作的代码示例:
# 加载模型输出的超分辨率图像
super_res_img = cv2.imread('super_res_output.jpg')
# 应用直方图均衡化以增强图像对比度
enhanced_img = cv2.equalizeHist(cv2.cvtColor(super_res_img, cv2.COLOR_BGR2GRAY))
# 应用高通滤波器进行图像锐化
sharpen_kernel = np.array([[-1,-1,-1], [-1,9,-1], [-1,-1,-1]])
sharpened_img = cv2.filter2D(super_res_img, -1, sharpen_kernel)
# 保存增强后的图像
cv2.imwrite('enhanced.jpg', enhanced_img)
cv2.imwrite('sharpened.jpg', sharpened_img)
在该段代码中,我们首先读取了模型输出的超分辨率图像。然后,我们使用 cv2.equalizeHist 函数进行了直方图均衡化,以提高图像的全局对比度,特别是对于图像中较暗的区域。接下来,我们使用了一个简单的高通滤波器进行锐化处理,以增加图像边缘的清晰度。最后,我们保存了增强后的图像。
通过这些后处理技术,可以使得超分辨率图像更加吸引人眼,提升了视觉体验。
4.2.2 超分辨率图像的质量评估指标
为了量化评估超分辨率处理的效果,需要使用一系列的图像质量评估指标。常见的指标包括峰值信噪比(PSNR)、结构相似性指数(SSIM)、视觉信息保真度(VIF)等。这些指标从不同的角度衡量了原始图像与超分辨率图像之间的差异。
下面是一个使用Python和OpenCV计算PSNR和SSIM的示例:
from skimage.metrics import structural_similarity as ssim
import math
# 计算PSNR
def calculate_psnr(img1, img2):
mse = np.mean((img1 - img2) ** 2)
if mse == 0:
return 100
PIXEL_MAX = 255.0
return 20 * math.log10(PIXEL_MAX / math.sqrt(mse))
# 计算SSIM
def calculate_ssim(img1, img2):
return ssim(img1, img2)
# 假设我们已经有了原始图像和超分辨率图像
psnr_value = calculate_psnr(super_res_img, original_img)
ssim_value = calculate_ssim(super_res_img, original_img)
print(f"PSNR value: {psnr_value}")
print(f"SSIM value: {ssim_value}")
在该段代码中,我们定义了两个函数 calculate_psnr 和 calculate_ssim ,分别用于计算PSNR和SSIM。PSNR的计算是基于均方误差(MSE),通过对比两幅图像的像素值差异来进行。SSIM的计算则更进一步,考虑了图像的亮度、对比度和结构信息的相似性。
通过这些指标的数值,可以对超分辨率技术的性能进行客观的评估,帮助开发者优化和改进模型。
在实际应用中,还会结合用户的主观评价,例如用户体验测试、满意度调查等方法,来综合评价超分辨率技术的实际效果和应用价值。
5. Python API的使用方法
在深度学习和图像处理领域,Python因其简洁易懂的语法和强大的生态系统,已成为开发者的首选语言。Python API提供了丰富的接口用于调用OpenCV库中的函数和模块,包括超级分辨率技术。接下来,我们将深入探讨如何通过Python API有效地使用OpenCV的超级分辨率模块。
5.1 Python与OpenCV的集成使用基础
在开始使用Python API之前,需要确保已经正确安装了Python环境以及OpenCV库。可以通过Python的包管理器pip来安装OpenCV。
pip install opencv-python
安装完成后,我们可以使用Python的import语句来导入OpenCV模块:
import cv2
随后,我们会涉及到图像的加载、处理和显示等操作。在Python中使用OpenCV进行图像处理是非常直接的,例如读取一张图片并显示它:
# 读取图片
image = cv2.imread('path_to_image.jpg')
# 检查图片是否正确读取
if image is not None:
# 显示图片
cv2.imshow('Image', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
接下来,我们来看如何集成超级分辨率模块到我们的开发流程中,并探讨相关的应用技巧。
5.2 OpenCV超级分辨率API的具体实现
OpenCV的超级分辨率API允许开发者通过简单的接口调用来增强图像的分辨率。为了实现这一点,OpenCV提供了一个称为 cv2.dnn_superres 的模块,它包含了几种预训练的超级分辨率模型。
例如,我们可以使用“ESPCN”模型来执行图像超分辨率任务。首先,我们需要创建一个DnnSuperResImpl实例,并指定我们想要使用的模型类型和缩放比例:
import cv2
from cv2.dnn_superres import DnnSuperResImpl
# 创建DnnSuperResImpl实例
sr = DnnSuperResImpl()
# 设置所用的模型和缩放比例
sr.readModel('path_to_model.pb')
sr.setModel('espcn', 3)
# 读取低分辨率的图片
image = cv2.imread('path_to_lowres_image.jpg', cv2.IMREAD_COLOR)
# 使用模型对图片进行放大
result = sr.upsample(image)
# 显示结果
cv2.imshow('Super Resolved Image', result)
cv2.waitKey(0)
cv2.destroyAllWindows()
5.2.1 高级参数调整与应用
开发者可以根据自己的需求调整模型的各种参数,包括但不限于算法的迭代次数、超参数等。让我们通过一个更高级的例子来说明如何调整这些参数:
# 使用已加载的模型,设置缩放比例为2
sr.setModel('espcn', 2)
# 设置参数调整模型行为
# 例如,增加迭代次数来提升质量
sr.setPreferableBackend(cv2.dnn_superres.DNN_SUPERRES_BACKEND_OPENCV)
sr.setPreferableTarget(cv2.dnn_superres.DNN_SUPERRES_TARGET_CPU)
# 应用高级调整
sr.upsample(image, num_iterations=10)
通过调整 num_iterations 的值,开发者可以控制模型的训练次数,进而影响超分辨率的质量和性能。
5.3 实际开发中Python API的应用技巧
在实际开发中,我们通常会遇到各种挑战,比如需要处理大批量的图像、不同尺寸的图像、不同的输入输出格式等。在这些情况下,了解并掌握一些使用技巧是至关重要的。
5.3.1 批量处理图像
处理大量图像时,我们可以将它们组织成数组,并使用循环来逐一处理。例如,使用Python的列表来加载多张图像:
import numpy as np
# 创建一个列表来存储图像数组
images = []
for img_path in image_paths:
image = cv2.imread(img_path, cv2.IMREAD_COLOR)
if image is not None:
images.append(image)
# 使用模型批量处理图像
results = [sr.upsample(img) for img in images]
5.3.2 尺寸不一的图像处理
在面对不同尺寸的图像时,可以先统一调整它们的尺寸,再应用超级分辨率模型:
# 设定一个标准尺寸
standard_size = (640, 480)
# 调整图像尺寸
for i, image in enumerate(images):
images[i] = cv2.resize(image, standard_size, interpolation=cv2.INTER_AREA)
5.3.3 自定义模型训练
虽然OpenCV提供了预训练的模型,但我们也可以使用Python API来训练我们自己的超级分辨率模型:
# 假设我们有一个训练函数trainModel
model = trainModel(data, params)
# 将训练好的模型保存到文件
model.save('my_model.pb')
在此基础上,使用 readModel 和 setModel 方法来加载和设置我们自己的模型,而不是使用预训练模型。
在本章节中,我们了解了如何在Python中使用OpenCV的超级分辨率API进行图像的增强处理,包括图像的预处理、模型的加载、参数的调整以及批量图像处理等实用技巧。这些知识对于开发者来说是非常宝贵的,它能帮助我们更有效地在真实世界项目中应用超级分辨率技术。
在下一章节中,我们将探讨如何通过CUDA/OpenCL等硬件加速技术来进一步优化超级分辨率的处理速度和质量。
6. 硬件加速支持(CUDA/OpenCL)
6.1 CUDA/OpenCL在图像处理中的作用与优势
图形处理单元(GPU)的并行计算能力使其成为处理图像和视频数据的理想选择。CUDA(Compute Unified Device Architecture)是由NVIDIA开发的一种并行计算平台和编程模型,它允许开发者利用NVIDIA的GPU进行通用计算。OpenCL(Open Computing Language)是一种开放标准的框架,它支持跨平台的编程,包括CPU、GPU和其他处理器。
CUDA和OpenCL在图像处理领域中具有显著优势:
- 高性能 :利用GPU的并行处理能力,能够显著提高处理速度,特别是在需要大量计算的图像任务中,例如图像缩放、滤波、转换以及深度学习模型的执行。
- 实时性 :特别是在视频流处理中,高吞吐量的硬件加速允许实时处理,这对于监控、实时分析等应用场景非常重要。
- 成本效益 :与专业图像处理硬件相比,利用现有的GPU硬件进行加速处理通常成本更低,且便于升级和维护。
6.1.1 CUDA的优势
CUDA通过提供一个能够直接与GPU进行通信的接口,让开发者能够深入控制GPU的计算能力。它的优势在于:
- 易用性 :CUDA提供了一套相对简单直观的编程接口,通过C/C++扩展,能够让开发者快速上手。
- 优化性 :可以针对特定的算法和应用场景进行深度优化,提升性能。
- 生态支持 :CUDA生态丰富,拥有大量社区资源和预构建的库,适合多种复杂的图像处理任务。
6.1.2 OpenCL的优势
OpenCL作为一种开放标准,它的优势在于:
- 跨平台 :可以在任何支持OpenCL的处理器上运行,包括NVIDIA、AMD和Intel的GPU,以及CPU和FPGA等。
- 灵活性 :开发者可以针对不同硬件优化代码,OpenCL也支持多种编程语言,如C、C++等。
- 社区支持 :有广泛的开发者社区支持,适合开源项目和需要跨硬件供应商支持的项目。
6.1.3 并行计算在图像处理中的具体应用
- 图像滤波与变换 :对图像进行卷积、傅里叶变换等操作时,可以并行处理多个像素。
- 图像分析 :进行特征检测、边缘检测、对象识别时,可以同时处理多个区域。
- 图像合成 :在图像合成、渲染中,可以并行生成和处理图像的多个部分。
6.2 OpenCV超级分辨率模块的硬件加速配置
OpenCV超级分辨率模块支持使用CUDA进行硬件加速,能够显著提升图像重建的速度和质量。为了使用硬件加速,开发者需要确保已经安装了适当的NVIDIA驱动和CUDA工具包。
6.2.1 环境配置步骤
- 安装NVIDIA驱动 :确保安装了与CUDA兼容的NVIDIA GPU驱动。
- 安装CUDA工具包 :根据GPU的计算能力,选择合适的CUDA版本进行安装。
- 安装OpenCV :使用支持CUDA的OpenCV版本,确保在编译时加入了CUDA支持。
- 配置环境变量 :将CUDA的bin目录加入到系统的PATH环境变量中。
6.2.2 硬件加速代码示例
下面是一个使用OpenCV进行CUDA加速的简单示例:
#include <opencv2/opencv.hpp>
#include <opencv2/gpu/gpu.hpp>
int main() {
// 加载图像
cv::Mat image = cv::imread("input.jpg");
cv::gpu::GpuMat gpu_image(image); // 将图像上传到GPU内存
// 应用CUDA加速的处理
cv::gpu::SuperResolution super_res; // 创建超级分辨率对象
cv::Mat super_res_image = super_res.process(gpu_image); // 处理图像
// 将处理后的图像下载到CPU内存
super_res_image.download(super_res_image);
// 显示结果
cv::imshow("Super Resolution Result", super_res_image);
cv::waitKey();
return 0;
}
在上述代码中, cv::gpu::GpuMat 用于在GPU上处理图像, cv::gpu::SuperResolution 类用于执行超级分辨率任务。通过调用 process 方法,可以在GPU上并行处理图像。
6.3 硬件加速对超级分辨率性能的影响分析
硬件加速对于提升超级分辨率算法的性能至关重要。以下是硬件加速可能带来的性能提升的几个方面:
6.3.1 性能提升的具体影响
- 处理速度 :图像处理任务的执行时间大幅缩短,为实时应用提供了可能。
- 分辨率和质量 :能够处理更高分辨率的图像,提升最终图像的视觉质量。
- 资源消耗 :在资源消耗(如电能)方面更高效,能够长时间运行而不会过热。
6.3.2 性能优化策略
- 算法优化 :针对特定GPU架构对算法进行优化,例如减少内存访问次数、优化线程执行。
- 内核优化 :根据GPU的硬件特性和内存层次结构来优化内核代码,比如合并内存访问、提高并行度。
- 流水线技术 :使用流水线技术来隐藏内存访问的延迟,提高整体计算效率。
6.3.3 性能测试与评估
性能测试通常包括执行时间的测量、吞吐量的评估以及算法在不同硬件平台上的表现比较。评估指标可能包括:
- 帧率 :每秒处理的帧数,用于衡量实时性。
- 加速比 :硬件加速后与无加速时的性能比值。
- 质量损失 :加速处理过程中图像质量的损失。
通过测试和评估,开发者可以了解硬件加速的具体效果,并对算法进行进一步的调整和优化。
7. 其他超分辨率方法与应用场景
在图像处理领域中,超级分辨率技术(Super-Resolution, SR)旨在从低分辨率的图像中重建出高分辨率的图像。除了我们之前讨论的SRCNN模型和OpenCV的超分辨率模块之外,还有许多其他的超分辨率方法,每种方法各有特点,并在不同的应用场景中表现出色。
7.1 传统图像超分辨率技术的回顾与比较
在深度学习兴起之前,传统超分辨率技术主要依赖于插值算法和重建技术。常见的方法包括:
- 双三次插值(Bicubic Interpolation) :一种利用周围16个像素值来进行像素插值的算法。虽然这种方法计算简单,但往往会产生模糊的图像。
- 边缘指导插值(Edge-Guided Interpolation, EGI) :利用图像的边缘信息来指导插值过程,以提高重建图像的锐度。
- 基于稀疏表示的方法 :如稀疏编码(Sparse Coding)和字典学习(Dictionary Learning),通过学习大量高分辨率图像的稀疏表示来重建细节。
在比较这些方法时,我们通常关注其对图像质量的提升、计算效率和适用场景。深度学习方法在图像质量和细节重建方面通常优于传统方法,但需要大量的数据和计算资源。
7.2 其他先进超分辨率技术的原理与特点
近年来,随着深度学习技术的发展,涌现出一批新的超分辨率技术,如:
- ESRGAN(Enhanced Super-Resolution Generative Adversarial Networks) :利用生成对抗网络(GAN)架构,提高超分辨率图像的视觉效果。
- VDSR(Very Deep Super-Resolution) :使用较深的网络结构,通过残差学习提高超分辨率的效果。
- LapSRN(Laplacian Super-Resolution Network) :利用多尺度的拉普拉斯金字塔来重建不同层次的细节。
- RCAN(Real-CUGAN) :对网络结构进行了进一步的优化,强调了通道注意力机制来提升特征表示能力。
这些方法各有优势,适用于不同的图像类型和应用场景。它们能够处理更加复杂的图像细节重建任务,并且在保持计算效率的同时,显著提高图像质量。
7.3 超级分辨率技术在各行业的应用案例分享
超分辨率技术的应用非常广泛,它在多个行业中都发挥着重要作用:
- 卫星和遥感图像 :通过高分辨率图像提高地球观测的质量,用于地图制作、农业监测、灾害评估等。
- 医疗成像 :增强MRI和CT扫描图像的分辨率,帮助医生更准确地诊断和监测病状。
- 视频监控 :改善监控摄像头的图像质量,用于人像识别、行为分析等安全领域。
- 娱乐媒体 :在电影和视频游戏产业中用于提高视觉效果,使老旧电影修复工作成为可能。
这些案例仅展示了超级分辨率技术应用的一部分。随着技术的不断进步和优化,我们可以预见其在未来各领域的应用将更加广泛和深入。
简介:在图像处理中,超级分辨率技术能够将低分辨率图像转换为高分辨率图像以提升清晰度和细节。OpenCV的超级分辨率模块基于快速超分辨率卷积神经网络(SRCNN),该模型包含预处理、特征提取与上采样和后处理的卷积层。OpenCV提供了预训练模型,支持从头训练和微调,且其Python API允许用户轻松应用超级分辨率技术。此外,模块支持硬件加速,提高了处理速度,并兼容其他高级超分模型。超级分辨率技术在多个领域有广泛的应用,如监控视频增强、医疗影像分析等。

















 4797
4797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









