






 本文介绍了如何使用Node.js、Express、Superagent和Cheerio库构建网页爬虫,实现从指定网站抓取内容,并通过登录逻辑处理验证用户身份。详细解释了依赖管理、爬虫实现、登录流程以及使用Cheerio处理HTML内容的技术要点。
本文介绍了如何使用Node.js、Express、Superagent和Cheerio库构建网页爬虫,实现从指定网站抓取内容,并通过登录逻辑处理验证用户身份。详细解释了依赖管理、爬虫实现、登录流程以及使用Cheerio处理HTML内容的技术要点。

1.爬虫抓取
爬虫抓取就是获取他人也面的内容,显示在自己的页面里,我们抓取https://cnodejs.org/getstart的:

显示在自己页面里。
{
"name": "application-name",
"version": "0.0.1",
"private": true,
"scripts": {
"start": "node ./bin/www"
},
"dependencies": {
"express": "~3.4.8",
"static-favicon": "~1.0.0",
"morgan": "~1.0.0",
"cookie-parser": "~1.0.1",
"body-parser": "~1.0.0",
"debug": "~0.7.4",
"ejs": "~0.8.5",
"formidable": "*",
"mongodb":"*",
"mongoskin":"*",
"express-session":"*",
"superagent":"*",
"cheerio":"*"
}
}依赖加入,一个superagent一个cheerio,前面是获取页面内容,后面是筛选内容。
我们npm install下载依赖。
index.js引入:
var superagent = require('superagent');
var cheerio = require('cheerio');我们把内容显示在list页面里,改变/list路由处理。
app.get('/list', function(req, res){
var targetUrl = 'https://cnodejs.org/getstart';
superagent.get(targetUrl)
.end(function (err, ares) {
console.log(ares.text);
res.render('list', { text: ares.text });
});
});地址输入:http://localhost:1234/list
显示了html页面源码:
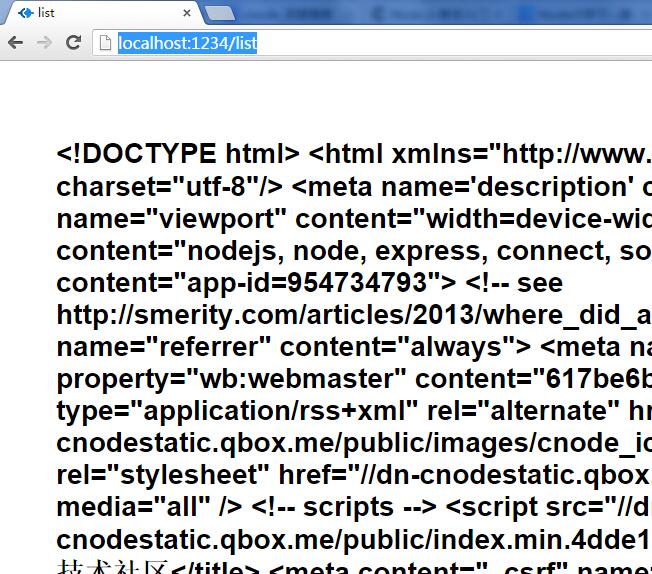
此时如果我们有jq类似工具,$(".xx").html()就可以拿到内容了,cheerio就是类似实现,返回的html我们当做dom树处理就可以了。
我们在/list加入cheerio的处理:
app.get('/list', function(req, res){
var targetUrl = 'https://cnodejs.org/getstart';
superagent.get(targetUrl)
.end(function (err, ares) {
console.log(ares.text);
var $ = cheerio.load(ares.text);
//通过CSS selector来筛选数据
var arr=[];
$('.markdown-text p strong').each(function (idx, element) {
console.log($(element).html());
arr.push($(element).html());
});
res.render('list', { text: arr });
});
});list.html页面:
<!DOCTYPE html>
<html>
<head>
<title>list</title>
<link rel='stylesheet' href='/stylesheets/style.css' />
</head>
<body>
<ul>
<% for(var i=0; i<text.length; i++) {%>
<li><%= text[i] %></li>
<% } %>
</ul>
</body>
</html>显示:
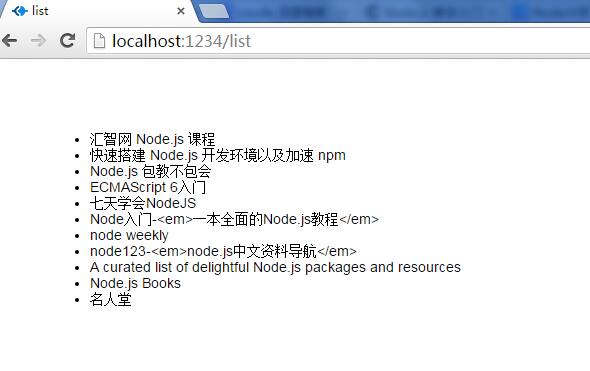
好像有点问题,选的不是全是需要的内容,要获取看来只能一部分一部分的拿会正确显示。
2.登录逻辑
登录其实使用的就是查询处理,
用户发送请求,req会携带用户名和密码
req的用户名作为依据,我们去数据库查询,会有2中结果,要吗不存在,要吗存在,
如果不存在直接登录失败,存在我们把数据库中用户名记录字段密码值返回
用户名存在,返回数据库密码和用户登录req的密码对比,要吗成功,要吗失败
成功,session的name赋值为用户名,进入首页,失败返回到登陆页
总结:
nodejs+express+mongodb+ejs!

















 110
110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









