






 本文介绍如何使用正则表达式精确匹配中文汉字及双字节字符,适用于特定需求下的字符串处理任务。
本文介绍如何使用正则表达式精确匹配中文汉字及双字节字符,适用于特定需求下的字符串处理任务。
这篇文章主要介绍了通过正则表达式准确匹配出字符串中存在的中文汉字,同时还有匹配双字节字符的正则,需要的朋友可以参考下
\w匹配的仅仅是中文,数字,字母,但是对于特殊需求来讲,仅匹配中文时常会用到
匹配中文字符的正则表达式: [\u4e00-\u9fa5]
或许你也需要匹配双字节字符,中文也是双字节的字符
匹配双字节字符(包括汉字在内):[^\x00-\xff]
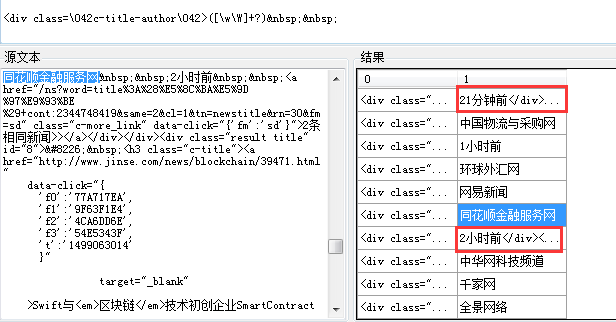
以下图为例:我想要的仅仅只是某一标题下的文章的来源,但是下面的正则就匹配到了多少分钟前,多少小时前这显然不是我想要的,这种情况下我就需要只取这个正则块中所有的中文汉字
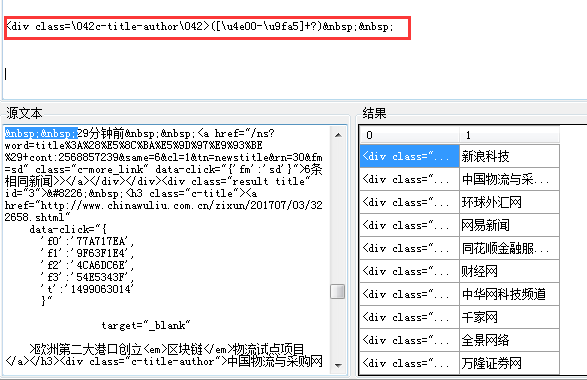
下图既是通过匹配中文字符的正则表达式获得结果:

















 897
897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









