






 本文介绍如何在Solr 7.0中配置和使用IK分词器及拼音分词器,包括下载所需软件、创建Solr Core、安装分词器插件并进行测试。
本文介绍如何在Solr 7.0中配置和使用IK分词器及拼音分词器,包括下载所需软件、创建Solr Core、安装分词器插件并进行测试。
资料准备
• solr7.0下载
• IK分词器下载
• 拼音分词器下载
solr文件目录(只讲一下7有些变化的目录)
• web目录 : solr7/server/solr_webapp/webapp/
• home目录 : solr7/server/solr
• bin目录 : solr7/bin
创建Core
运行solr
#进入bin目录
$ cd ./solr7/bin
#执行solr
$ ./solr start -p 8000 ps: 停止和重启分别是(stop/restart)
创建core
• 这里有个坑 就是在管理页面上根本创建不起
推荐使用手动创建方法:
进入home目录
$ cd ./solr7/server/solr/
创建core
$ ./solr create -c core1
创建完成 重启solr 进入管理页面 可看到刚创建的core
创建中文分词器
IK分词器:
• ext.dic为扩展字典
• stopword.dic为停止词字典
• IKAnalyzer.cfg.xml为配置文件
• solr-analyzer-ik-5.1.0.jar ik-analyzer-solr5-5.x.jar为分词jar包。
• 1:将IK分词器 JAR 包拷贝到solr7/server/solr_webapp/webapp/WEB-INF/lib/
• 2:将词典 配置文件拷贝到 solr7/server/solr_webapp/webapp/WEB-INF/
• 3: 更改test_core\conf\managed-schema配置文件
<!-- 我添加的IK分词 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="true"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="true"/>
</analyzer>
</fieldType>
• 重启 测试分词器text_ik ,测试在后面
pinyin分词器
• 1:将pinyin分词器 JAR 包拷贝到solr7/server/solr_webapp/webapp/WEB-INF/lib/
• 2: 更改test_core\conf\managed-schema配置文件
<fieldType name="text_pinyin" class="solr.TextField" positionIncrementGap="0">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory"/>
<filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory" minTermLenght="2" />
<filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory" minGram="1" maxGram="20" />
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory"/>
<filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory" minTermLenght="2" />
<filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory" minGram="1" maxGram="20" />
</analyzer>
</fieldType>
• 重启 测试分词器text_pinyin 测试在后面
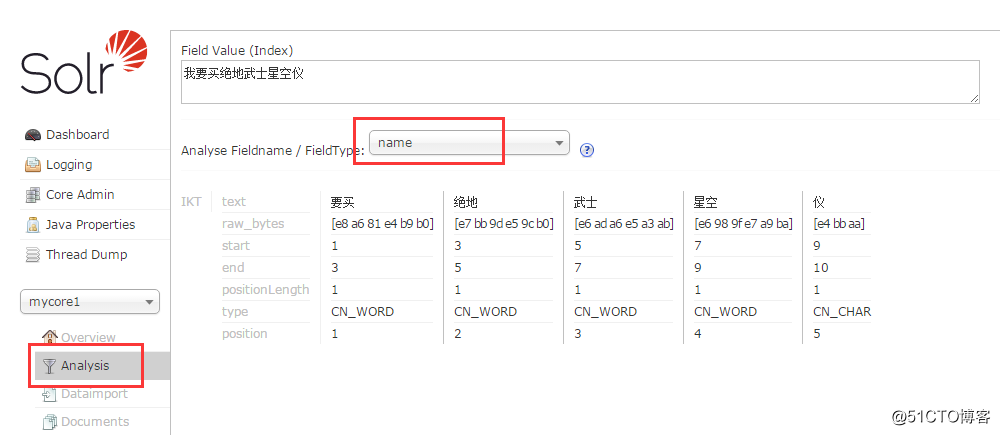
在admin后台, analysis 下查看分词效果
- 中文分词效果
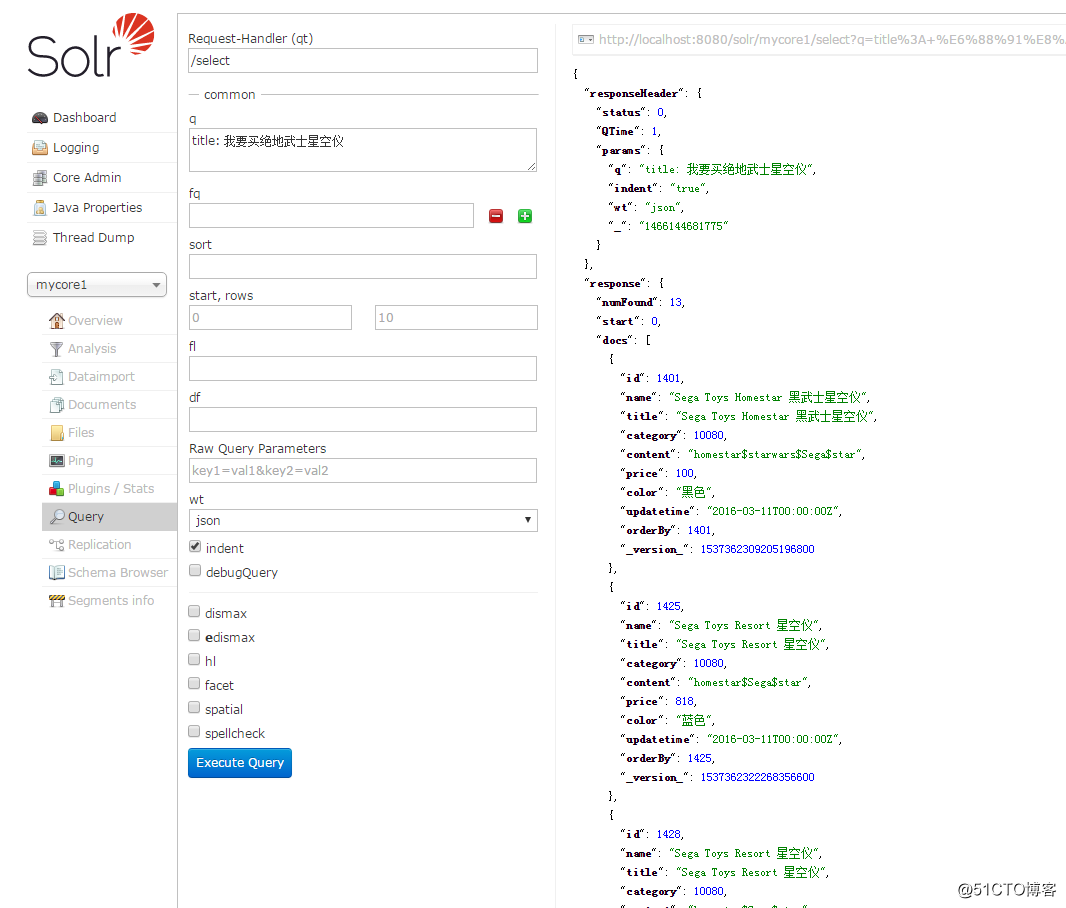
- 索引查询效果
转载于:https://blog.51cto.com/204222/2085602

















 555
555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









