



 本文介绍如何使用Python爬虫抓取糗事百科的内容,并利用pymongo模块将抓取到的数据存储到MongoDB数据库中。文章详细展示了从安装MongoDB、配置数据存储路径到Python代码实现的全过程。
本文介绍如何使用Python爬虫抓取糗事百科的内容,并利用pymongo模块将抓取到的数据存储到MongoDB数据库中。文章详细展示了从安装MongoDB、配置数据存储路径到Python代码实现的全过程。

Mongo实际上是以文档、集合、数据库的形式。
文档有唯一的一个ID,类似python里的字典,数据以key-value的形式存储其中,但是键值对是有顺序的,顺序不同文档也是不同的。
集合是在MongoDB中的一组文档,类似关系型数据库中的数据表。
一个MongDB中可以建立多个数据库,默认数据库为“db”,在MongDB的shell窗口中,使用show dbs命令可以查看所有的数据库,使用db命令可以看当前的数据库。
安装Mongo:去https://www.mongodb.com/download-center下载Mongo
进行安装。安装后可以看到如下:其中那个mongodb-win32-x86_64-2008plus-ssl是安装包,data是设置的数据存储文件。
前面说的设置数据存储路径具体操作如下:
mongod -dpath 路径
例如:mongod -dpath F:\常用软件\MongoDB\data然后就会开启mongDB服务:
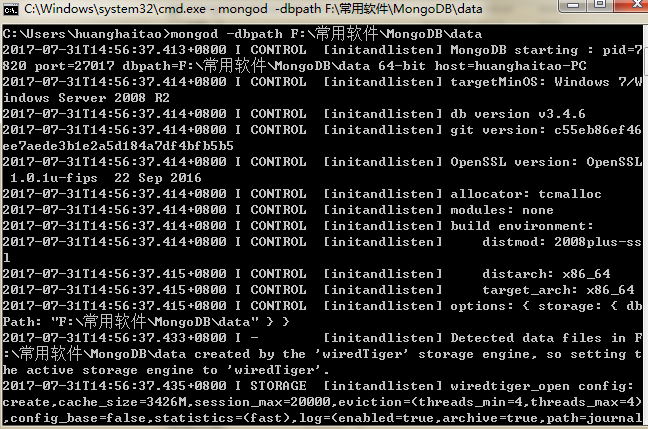
mongDB服务不用关闭,用以接下来的python连接,否则会出错
python操作Mongo的模块是pymongo,通过pip安装:
pip install pymongo爬虫代码仍然使用上次的爬取糗事百科的代码,对其进行改造:
#-*- coding-8 -*-
import pymongo
import requests
import lxml
from bs4 import BeautifulSoup
def craw(url,page = '1'):
user_agent = 'Mozilla/4.0 (compatible; MISE 5.5; Windows NT)'
headers = {'User_Agent':user_agent}
url_text = requests.get(url,headers = headers)
if url_text.status_code != 200:
url_text.encoding = 'utf-8'
print('ERROR')
soup = BeautifulSoup(url_text.text,'lxml')
contents = soup.select(r'.content')
names = soup.find_all('h2')
n = 1
client = pymongo.MongoClient(host='localhost',port=27017)
qiushi = client['qiushi']
newsdata = qiushi['newsdata']
for content,name in zip(contents,names):
print('第%s趣事'%n)
n += 1
name = name.get_text()
content = content.get_text()
print('用户名:'+name+'内容:'+content)
data = {
'name':name,
'content':content
}
newsdata.insert_one(data)
for i in newsdata.find():
print(i)
if __name__ == '__main__':
url = r'https://www.qiushibaike.com/'
s1 = craw(url)
具体改动:
client = pymongo.MongoClient(host='localhost',port=27017)
qiushi = client['qiushi']
newsdata = qiushi['newsdata']
连接Mongo,选择或创建一个数据库,选择或创建一个数据集合
for content,name in zip(contents,names):
print('第%s趣事'%n)
n += 1
name = name.get_text()
content = content.get_text()
print('用户名:'+name+'内容:'+content)
data = {
'name':name,
'content':content
}
newsdata.insert_one(data)
创建一个字典,插入一行数据:
newsdata.insert_one(data)输出数据:
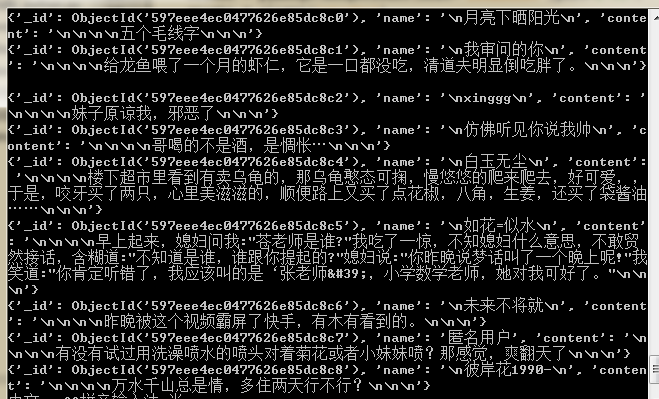
for i in newsdata.find():
print(i)结果如下:

















 1164
1164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









